




前一段时间需要利用某个学校的教务网的数据来构建一个web应用,后台使用Java。
本来这应该是一个很简单的任务,只需要利用JSoup写好爬虫就可以了,但没想到打开教务网之后发现每次都需要输入验证码,那么一方面为了简化用户操作另一方面也为了练手,我决定识别这个验证码来实现无验证码登录。
能这样做的主要原因是它的验证码长得还是比较规整的,基本上是这个样子:

但还是不够规整,不能直接用图像处理然后匹配来做,如果长这个样子完全可以匹配像素点然后来识别数字的:
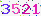
当时正好在学tensorflow,于是我决定利用tensorflow训练一个简单的NN模型来对验证码进行识别(当时本来想着如果效果不好就改CNN,没想到简单的NN就已经有90多的正确率了),然后再把模型放到Java的爬虫上作为登录的工具。
1.训练模型
1.1.数据获取
由于没有现成的数据集,所以我自己用python写了一个爬虫爬了1000张的验证码图片作为训练数据集:
import requests
from PIL import Image
import time
def getOnePic(code):
r=requests.get('http://xx.xx.xx.xx/CheckCode.aspx') #获取验证码页面
f=open('./oriPic/'+code+'.gif','wb') #打开文件
f.write(r.content) #写出图片
f.close() #关闭文件
time.sleep(1) #休眠一段时间防止频率过高爆炸
for i in range(1001): #获取1000张图片
getOnePic(str(i))
执行完成之后,我就已经拥有了比较多的数据可以用于训练了:

1.2.数据处理
按照以往的经验,把图片黑白化之后,会使得识别效果更好,此外这个验证码每个字符所处的位置还是比较规整的,可以将字符切分之后分别识别,如果不切分的话这个数据量应该是不够的,因为四个字符输出会有 3 6 4 36^{4} 364种可能。
1.2.1.工具文件实现
from PIL import Image
import numpy as np
# 阅读标签列表
def readList(filename):
li=[]
with open(filename,'r') as fp: # 打开文件
for l in fp: # 遍历每一行
strs=l.split(',')
for w in strs[:-1]:
li.append(w)
return li
# 打开图片文件为图片或数组
def openPic(filename,arr=False):
return np.array(Image.open(filename)) if arr else Image.open(filename)
#打印一个数组
def printArray(arr,spl=False):
for i in arr:
count=-1
for j in i:
count+=1
#if(count%5==0 and count!=0):
# print('\033[50m ',end='')
if(spl and (count==13 or count==26 or count==39)):
print('\033[40m ',end='')
print('\033[42mx' if j>=128 else '\033[46mx',end='')
print()
# 获取分割后的子图
def getSplitPic(pic):
res=[]
for i in range(4): # 共四个子图
res.append(pic.crop((3+i*12,0,3+(i+1)*12,20)))
return res
# 判断一个像素点是否为黑色
def isBlack(dot):
return dot<128
# 清除孤立点
# f=0 上 1 左 2 下 3 右
def check_neiber(arr,y,x,f,w):
if w==0: # 如果超过了最大栈 撤回
return False # 不是要清除的点
if x>0 and isBlack(arr[y][x-1]) and f!=1: # 如果在左边发现黑点并且不来自左边
if not check_neiber(arr,y,x-1,3,w-1): # 递归检查左边,如果不需要清除
return False # 返回
if x<len(arr[0])-1 and isBlack(arr[y][x+1]) and f!=3: # 检查右边
if not check_neiber(arr,y,x+1,1,w-1):
return False
if y>0 and isBlack(arr[y-1][x]) and f!=0: # 检查上边
if not check_neiber(arr,y-1,x,2,w-1): # 表示从下边过来的
return False
if y<len(arr)-1 and isBlack(arr[y+1][x]) and f!=2: # 检查下边
if not check_neiber(arr,y+1,x,0,w-1):
return False
arr[y][x]=255 # 清除
return True
# 黑白化并去噪
def clearPic(arr):
for i in range(len(arr)):
for j in range(len(arr[0])):
arr[i][j]=0 if arr[i][j]<128 else 255 # 首先设置黑白点
if isBlack(arr[i][j]): # 如果是黑点
check_neiber(arr,i,j,-1,2) # 处理噪音
1.2.2.黑白化并分割字符
import sys
sys.path.append("../")
import tool
import numpy as np
from PIL import Image
import readData
#获取处理之后的子数组
def handlePicToPics(pic):
pic=np.array(pic.crop((4,0,56,20)))
tool.clearPic(pic) #黑白化并去噪
#tool.printArray(pic) #打印看看
pic=Image.fromarray(pic) #获取图片
pics=tool.getSplitPic(pic) #获取分割后的子图
arrays=[]
for i in range(4):
arrays.append(p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









