







相同对象优化
dx11渲染时,我们需要设置vertexBuffer,indexBuffer巴拉巴拉,具体可以参照下图
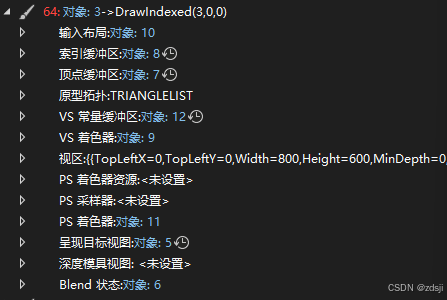
例如创建一个三角形:
// 顶点缓存
std::vector<ZDSJ::Vertex2D> vertices = {
{0.0f, 1.0f, 255, 0, 0, 128},
{0.5f, 0.0f, 0, 255, 0, 255},
{-0.5f, 0.0f, 0, 0, 255, 128},
};
// 顶点索引
const UINT16 indices[] = {
0,1,2
};
// 顶点缓存
this->addStaticBind(new ZDSJ::VertexBufferBindAble(_device, vertices));
// 顶点索引
this->addStaticIndexBuffer(new ZDSJ::IndexBufferBindAble(_device, indices, sizeof(indices)), sizeof(indices) / sizeof(UINT16));
// this->m_index_size = ;
// 顶点着色器
this->addStaticBind(new ZDSJ::VertexShaderBindAble(_device, g_main_vertex_shader, sizeof(g_main_vertex_shader)));
// layout
std::vector<D3D11_INPUT_ELEMENT_DESC> ied = {
{"Position", 0, DXGI_FORMAT::DXGI_FORMAT_R32G32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0},
{"Color", 0, DXGI_FORMAT_R8G8B8A8_UNORM, 0, 8u, D3D11_INPUT_PER_VERTEX_DATA, 0},
};
this->addStaticBind(new ZDSJ::InputLayoutBindAble(_device, ied, g_main_vertex_shader, sizeof(g_main_vertex_shader)));
// 像素着色器
this->addStaticBind(new ZDSJ::PixelShaderBindAble(_device, g_main_pixel_shader, sizeof(g_main_pixel_shader)));
// 缩放旋转矩阵
this->m_transform = new ZDSJ::VertexConstantBufferBindAble(_device);
this->m_bind_able->push_back(m_transform);这些对象放在构造函数中,那么每创建一个三角形,都需要创建出这些相同的对象,并将其绑定到管线上,这些操作完全是相同的,这里就是可以优化的点。
如何优化
很明显,将存储这些bindable对象的vector设置为静态成员变量,则每个类的对象将共享同一组bindable对象,问题在于,这个静态成员变量放在哪里,如果放在三角形、四边形类中,则每个类都需要重复写一遍静态的逻辑不利于扩展(大量重复代码)。如果放在基类DrawAbleAdapter中,每个类都继承与它,也就是不同的类使用了同一组bindable对象。
这里再次进行抽取,在三角形类与DrawAbleAdapter类之间再抽取出一层,构建模板类DrawAbleBase,传入不同的模板,将重复代码部分交给编译器去做。
template<class T>
class DrawAbleBase : public DrawAbleAdapter {
public:
bool isStaticInitialized() const {
return !this->m_static_bindable.empty();
}
void addStaticBind(BindAbleInterface* _bindable) {
this->m_static_bindable.push_back(_bindable);
}
void addStaticIndexBuffer(IndexBufferBindAble* _index_buffer, size_t _index_size) {
this->m_index_size = _index_size;
this->m_static_bindable.push_back(_index_buffer);
}
private:
static std::vector<BindAbleInterface*> m_static_bindable;
static size_t m_index_size;
protected:
const std::vector<BindAbleInterface*>& getStaticBindAble() const override {
return this->m_static_bindable;
}
const size_t getStaticIndexSize() const override {
return this->m_index_size;
}
};
template<class T>
std::vector<BindAbleInterface*> DrawAbleBase<T>::m_static_bindable;
template<class T>
size_t DrawAbleBase<T>::m_index_size = 0;而三角形类对模板类进行特化
class Triangle2DDrawAble : public DrawAbleBase<Triangle2DDrawAble>就达到了我们的效果,相同类型的形状共用一组bindable对象,也就是共用相同的顶点缓冲,索引缓冲等等。注意旋转矩阵要是对象私有的成员变量,一边不同对象给出不同的旋转、平移变换。借此设置对象的位置等信息。
绑定优化
现在不同的形状类可以使用同一组bindable对象了,减少了内存消耗,但是在渲染时,需要将这些对象绑定到渲染管线中,相同的形状绑定的对象又是相同的,这里又可以进行优化,相同类型的对象只进行一次渲染管线的绑定,也就是两个三角形对象共用的bindable对象在渲染时只绑定一次。
如何优化
首先,将存储这些drawable对象的容器抽取到单独的类DrawAbleManager中,方便后续优化。
这里先做一个兼容,兼容最早的写法,使用vector存储,做一个分类的判断,容器采用万能指针定义,根据不同分类new出不同的容器。
switch (this->m_render_type)
{
case Default:
this->m_container = new std::vector<ZDSJ::DrawAbleInterface*>;
break;
case Category:
this->m_container = new std::map<std::string, std::vector<ZDSJ::DrawAbleInterface*>>;
break;
default:
break;
}首先想到的就是根据类型对drawable对象进行存储,采用map结构。
std::map<std::string, std::vector<ZDSJ::DrawAbleInterface*>>* container = reinterpret_cast<std::map<std::string, std::vector<ZDSJ::DrawAbleInterface*>>*>(this->m_container);
std::string type_name(typeid(*_drawable).name());
std::map<std::string, std::vector<ZDSJ::DrawAbleInterface*>>::iterator item = container->end();
do {
item = container->find(type_name);
if (item != container->end()) {
item->second.push_back(_drawable);
}
else {
container->emplace(std::make_pair(type_name, std::vector<ZDSJ::DrawAbleInterface*>()));
}
} while (item == container->end());在添加drawable对象时,将相同类型的对象存到一起。
std::map<std::string, std::vector<ZDSJ::DrawAbleInterface*>>* container = reinterpret_cast<std::map<std::string, std::vector<ZDSJ::DrawAbleInterface*>>*>(this->m_container);
for (auto pair : *container) {
pair.second.at(0)->bindStatic(_context);
for (auto item : pair.second) {
item->update(_context);
item->bind(_context);
item->drawIndex(_context, 0u, 0u);
}
}渲染时遍历map,不同的key表示不同的类型,变换渲染类型时将该类型共用的bindable对象绑定到管线中,之后遍历该类型的每个对象,update主要完成动画计算,bind绑定自身旋转矩阵,最后draw出相应形状。
对比
在采用默认渲染方式,也就是不分类,每个对象渲染时都绑定一遍所有资源,借助图形调试可以看出:
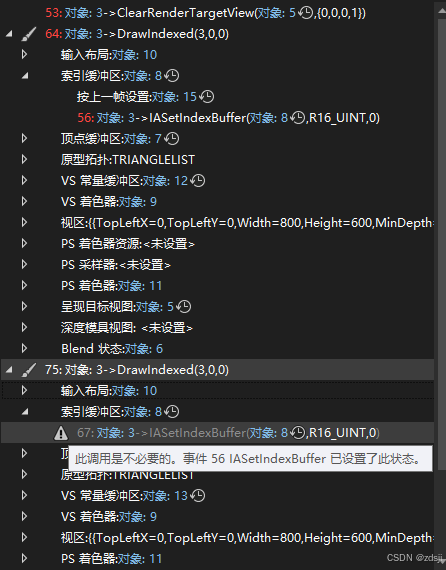
绘制相同类型形状时,对象的绑定是不必要的,相同的对象绑定了多次。
采用分类渲染方式:

问题解决。
源码放在github,develop分支



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









