







目录
一、简介
ES官方简介:Elasticsearch 是一个基于Lucene的分布式搜索、存储和分析引擎。所以不要只是将ES认为是一个搜索引擎。但是我们主要学习和使用的都是搜索和分析功能。ES实现搜索主要使用的是倒排索引。
1、Lucene与倒排索引
Lucene其实就是一个jar包,为我们提供了复杂的API,帮我们创建倒排索引。但是Lucene在做集群搜索时存在一些缺点,下图为Lucene实现集群搜索的展示以及缺点总结。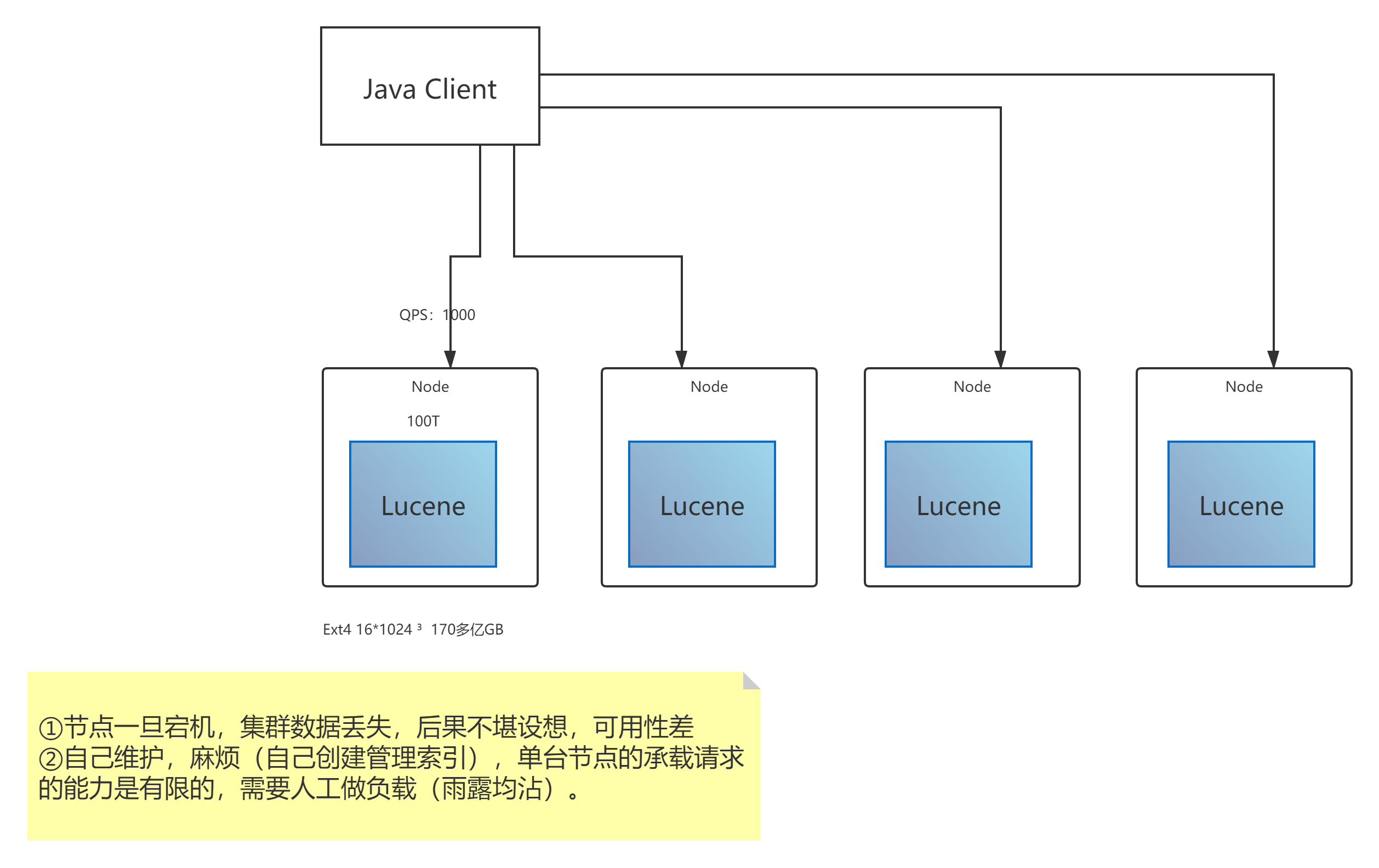
那什么是倒排索引呢?我们使用关系型数据库实现搜索功能时,会将这个词项在数据库中遍历查找,这种方式性能非常差,同时查询到的值相关度比较低。而倒排索引会将词项的一些信息进行存储,倒排索引的数据结构(一些词语会在后边通过与传统数据库字段进行对比理解):
1、包含关键词的document list.。
2、TF:关键词在每个document中出现的次数。越大越好,比如document-1为:我是张春明,document-2为:我是张春明,是一个小男孩。关键字张春明在1中的TF就比在2的大。
3、IDF:关键词在整个索引中出现的次数,越小越好。
4、关键词在当前document出现次数。
5、每个document的长度。
6、包含词项的所有document的平均长度。
实例如下:
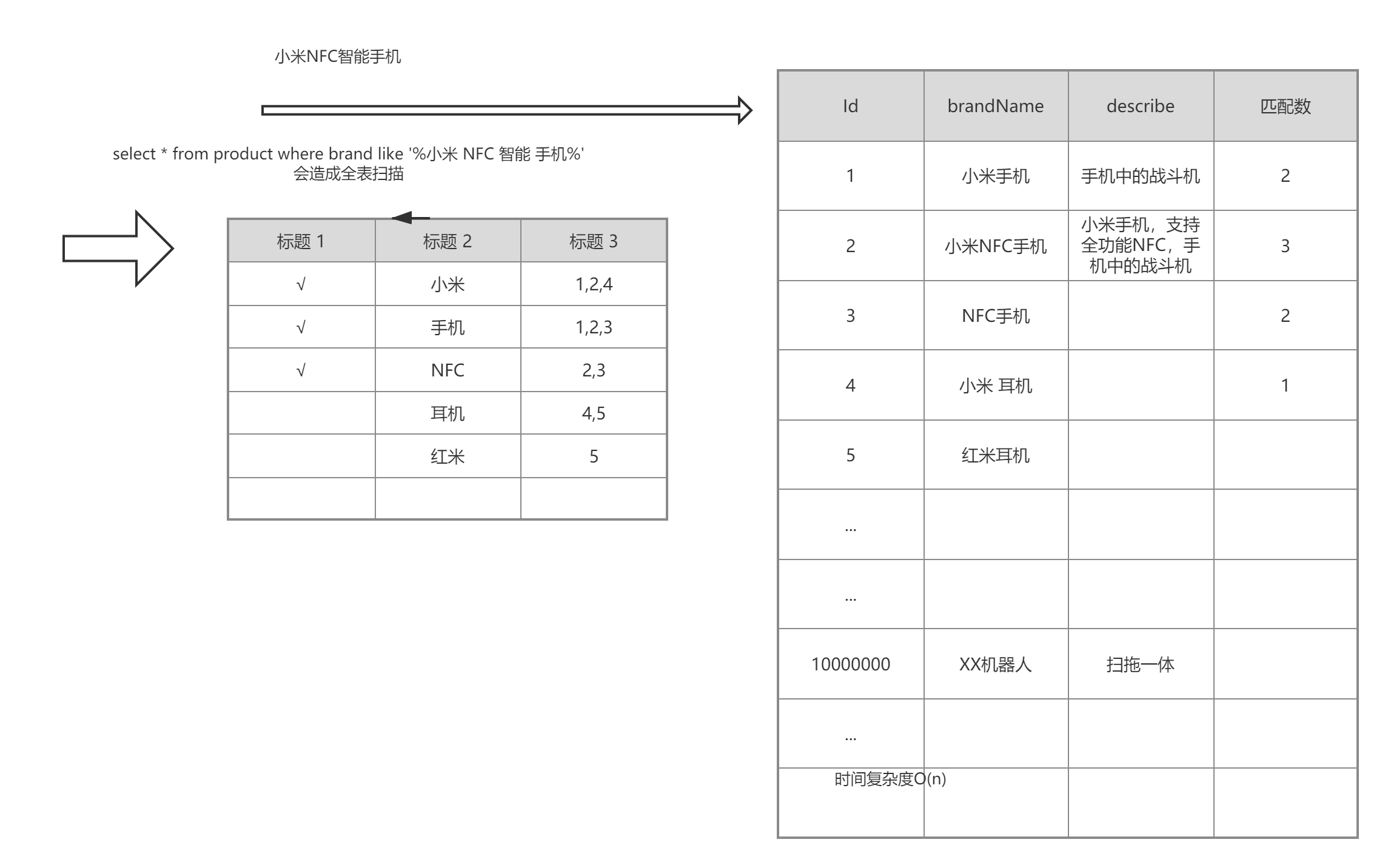
二、基本概念
主要是ES中各种重要的指标。
- 索引(Index):ElasticSearch把数据存放到一个或者多个索引(indices)中。ElasticSearch内部用Apache Lucene实现索引中数据的读写。但是在ElasticSearch中被视为单独的一个索引(index),在Lucene中可能不止一个。这是因为在分布式体系中,ElasticSearch会用到分片(shards)和备份(replicas)机制将一个索引(index)存储多份。
- 文档(Document):文档(Document)由一个或者多个字段(Field)组成。ES中的文档(Document)是没有固定的模式和统一的结构。
- 文档类型(Type):每个文档在ElasticSearch中都必须设定它的类型。文档类型使得同一个索引中在存储结构不同文档时,只需要依据文档类型就可以找到对应的参数映射(Mapping)信息,方便文档的存取。ES 7之后删除type概念。
- 节点(Node):单独一个ElasticSearch服务器实例称为一个节点。对于许多应用场景来说,部署一个单节点的ElasticSearch服务器就足够了。但是考虑到容错性和数据过载,配置多节点的ElasticSearch集群是明智的选择。
- 集群(Cluster):集群是多个ElasticSearch节点的集合。是提供高可用与高性能的重要手段
- 分片索引(Shard):集群能够存储超出单机容量的信息。为了实现这种需求,ElasticSearch把数据分发到多个存储Lucene索引的物理机上。这些Lucene索引称为分片索引,这个分发的过程称为索引分片(Sharding)。
- 需要注意的是:集群中分片的数量需要在索引创建前配置好,而且服务器启动后是无法修改的,至少目前无法修改。
- 索引副本(Replica):当集群负载增长,用户搜索请求可能会阻塞在单个节点上时,通过索引副本(Replica)机制就可以解决这个问题。在提供基础查询性能的同时,也保证了数据的安全性。即如果主分片数据丢失,ElasticSearch通过索引副本使得数据不丢失。索引副本可以随时添加或者删除,所以用户可以在需要的时候动态调整其数量。
- 网管(Gateway):ES运行过程中需要的所有数据(文档,状态、索引参数等)都被存储在Gateway中。
三、ES与关系型数据库
| 结构对比 | |
| 关系型数据库 | ES |
| DataBase | index |
| Table | type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | Query DSL |
| 操作对比 | ||
| ES方法 | 数据库处理 | 说明 |
| POST | Update | 获取信息或者更新 |
| GET | Read | 获取信息 |
| PUT | Create | 创建或覆盖 |
| DELETE | Delete | 删除 |
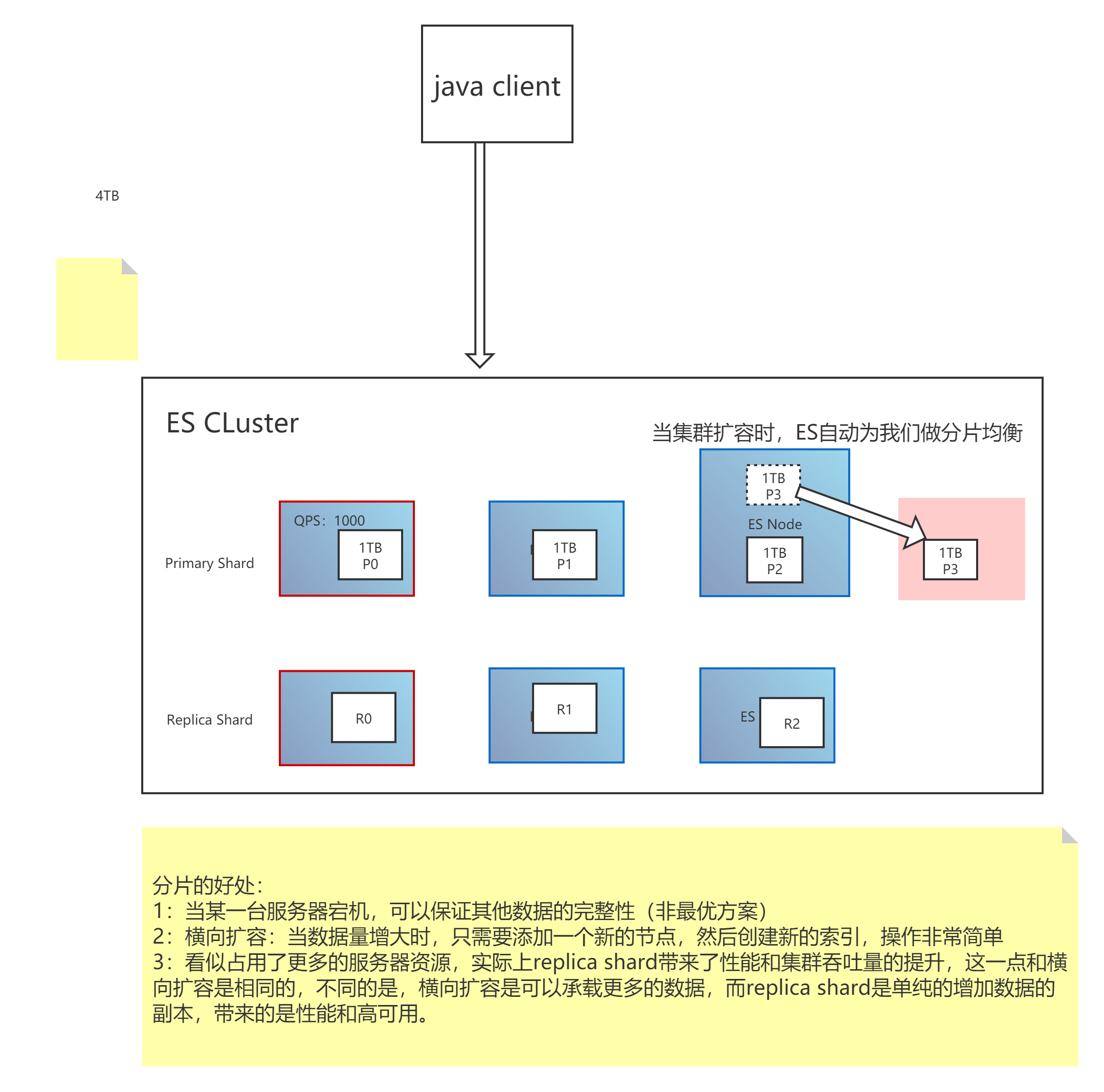
四、分片(Shard)和副本(Replica)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。
Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。
Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。
每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。
ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
五、注意事项
1、分片数量不可以实时修改
为什么ES的分片数量不可以实时修改呢?主要是因为索引数据存储导致的,es中文档数据的存储不是随机分派到不同的分片上的,是按照一定的规则进行分片的,所以如果实时修改分片数量会导致文件位置出现错误。索引数据的分片规则如下:
公式:shard_num = hash(_routing) % num_primary_shards字段解析:shard_num: 分片位置,数据分配到哪个分片。
_routing: 唯一标识,id字段或者parent字段。
num_primary_shards: 主分片数量。
2、副本最大值+1 <= 集群节点数量 <= 分片数量
我们首先需要明白必须满足如下规则才能保证ES集群的高可用性。
1、同一分片的副本不会放在同一个节点。
2、ES禁止同一个分片的主分片和副本分片在同一个节点。
要想满足如上条件副本数量+1必须小于等于集群节点数量。
集群节点数量<=分片数量是因为分片数量小于节点数量时分片的作用已经消失,分片主要是为了提高吞吐量,分片数量小于节点数量相当于直接使用节点进行存储,吞吐量没有提升。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











