




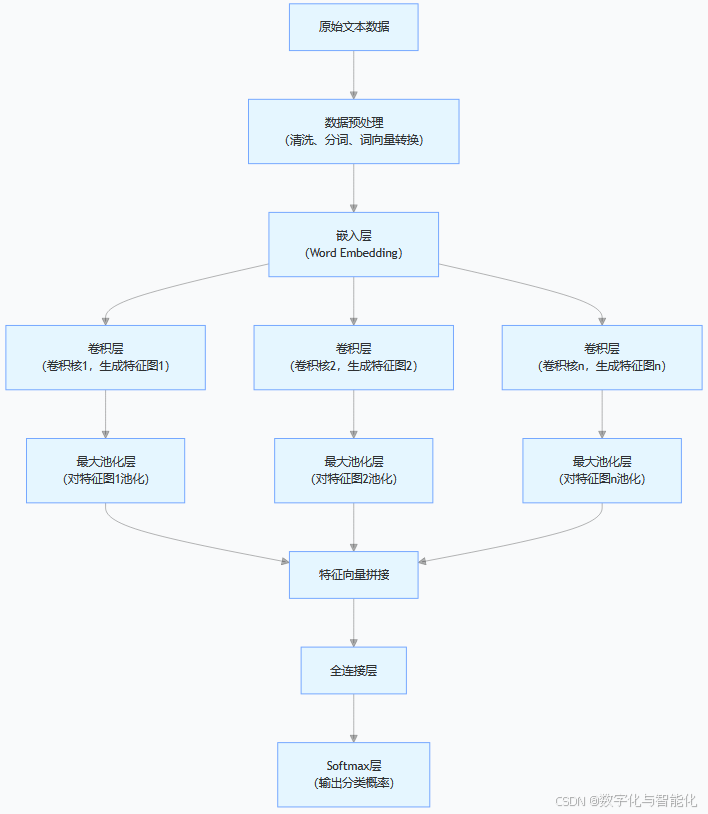
一、TextCNN模型架构
1、TextCNN概述
TextCNN 即文本卷积神经网络(Text Convolutional Neural Network) ,是一种基于卷积神经网络(CNN)架构,专门针对文本数据进行分类任务的深度学习模型。其核心思想是借鉴 CNN 在图像处理中提取局部特征的能力,通过卷积操作自动从文本中提取关键语义特征,进而完成文本分类。在文本中,词语与词语之间的组合顺序和相邻关系蕴含着语义信息,就如同图像中的局部像素组合构成有意义的图案,TextCNN 利用卷积操作捕捉文本中的这些局部语义单元。
2、输入层(Embedding Layer)
TextCNN 的输入层是整个模型处理文本数据的起点,负责将原始文本转换为神经网络可以处理的数值表示。输入层主要完成以下两个关键转换:
【1】符号化表示:将文本中的单词/字符映射为离散的索引(Tokenization)
【2】向量化表示:将离散索引转换为连续的稠密向量(Embedding)
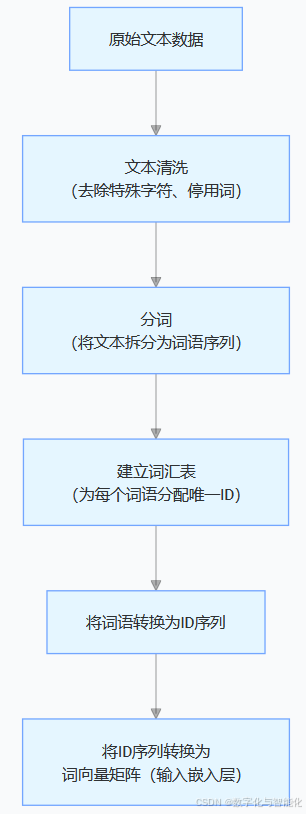
输入层的具体组成:
【1】文本符号化(Tokenization)
# 示例:将句子转换为单词索引序列
sentence = "TextCNN is great for text classification"
token_indices = [124, 15, 876, 32, 45, 1023] # 词汇表中对应的索引
关键参数:
vocab_size:词汇表大小(通常5万-20万)
max_seq_length:最大序列长度(如512或256)
【2】词嵌入层(Embedding Layer)
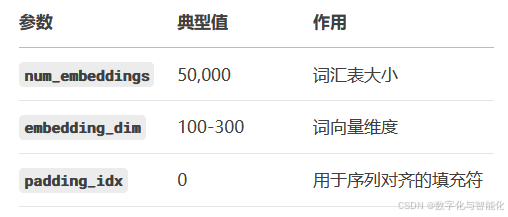
# PyTorch 实现
embedding_layer = nn.Embedding(
num_embeddings=vocab_size, # 词汇表大小
embedding_dim=300, # 词向量维度
padding_idx=0 # 填充符索引
)
参数说明:
【3】输入张量形状
输入层最终输出的张量形状为:
[batch_size, sequence_length, embedding_dim]
示例:
[32, 256, 300] 表示:
批量大小32
每句256个词
每个词300维向量
示例:
完整实现TextCNN的输入层处理流程,包含文本清洗、分词、建立词汇表、转换为ID序列和词向量矩阵的完整过程。
【1】 模拟数据准备
# 模拟数据集:8条中文文本,4个类别(0:体育, 1:科技, 2:娱乐, 3:财经)
raw_texts = [
"昨天NBA篮球比赛太精彩了!库里投中了10个三分球。",
"这款新手机的摄像头有5000万像素,拍照效果很棒!",
"周杰伦的演唱会门票3分钟就被抢光了,太火爆了!",
"今日股市大涨,上证指数突破3500点。",
"欧冠决赛将在下周六凌晨举行,球迷们准备好熬夜吧!",
"人工智能技术在新药研发领域取得重大突破。",
"电影《流浪地球2》票房突破40亿,创科幻片新纪录。",
"央行宣布降准0.5个百分点,释放长期资金约1万亿元。"
]
labels = [0, 1, 2, 3, 0, 1, 2, 3] # 对应类别标签

【2】文本清洗
import re
def clean_text(text):
# 1. 去除特殊符号和标点
text = re.sub(r'[^\w\s]', '', text)
# 2. 去除数字
text = re.sub(r'\d+', '', text)
# 3. 去除多余空格
text = re.sub(r'\s+', ' ', text).strip()
return text
cleaned_texts = [clean_text(text) for text in raw_texts]
print("清洗后的文本:")
for i, text in enumerate(cleaned_texts):
print(f"{i+1}. {text}")

输出结果:
清洗后的文本: 1. 昨天NBA篮球比赛太精彩了库里投中了个三分球 2. 这款新手机的摄像头有万像素拍照效果很棒 3. 周杰伦的演唱会门票分钟就被抢光了太火爆了 4. 今日股市大涨上证指数突破点 5. 欧冠决赛将在下周六凌晨举行球迷们准备好熬夜吧 6. 人工智能技术在新药研发领域取得重大突破 7. 电影流浪地球票房突破亿创科幻片新纪录 8. 央行宣布降准个百分点释放长期资金约万亿元
【3】中文分词
import jieba
# 添加自定义词典(可选)
jieba.add_word('NBA')
jieba.add_word('上证指数')
jieba.add_word('流浪地球')
def chinese_segment(text):
return list(jieba.cut(text))
tokenized_texts = [chinese_segment(text) for text in cleaned_texts]
print("\n分词结果:")
for i, tokens in enumerate(tokenized_texts):
print(f"{i+1}. {' '.join(tokens)}")

输出结果:
分词结果: 1. 昨天 NBA 篮球比赛 太精彩 了 库里 投中 了 个 三分球 2. 这 款 新手机 的 摄像头 有 万 像素 拍照 效果 很棒 3. 周杰伦 的 演唱会 门票 分钟 就 被 抢光 了 太 火爆 了 4. 今日 股市 大涨 上证指数 突破点 5. 欧冠 决赛 将 在 下 周六 凌晨 举行 球迷 们 准备 好 熬夜 吧 6. 人工智能 技术 在 新药 研发 领域 取得 重大突破 7. 电影 流浪地球 票房 突破 亿创 科幻片 新纪录 8. 央行 宣布 降准 个 百分点 释放 长期 资金 约 万亿元
【4】建立词汇表
from collections import Counter
def build_vocab(tokenized_texts, max_vocab_size=50, min_freq=1):
# 统计词频
word_counts = Counter()
for tokens in tokenized_texts:
word_counts.update(tokens)
# 按词频排序
sorted_vocab = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)
# 构建词汇表
vocab = {
'<PAD>': 0, # 填充标记
'<UNK>': 1, # 未知词
}
# 添加高频词
for word, count in sorted_vocab:
if count >= min_freq and len(vocab) < max_vocab_size:
vocab[word] = len(vocab)
return vocab
vocab = build_vocab(tokenized_texts)
print("\n词汇表(前10项):", dict(list(vocab.items())[:10]))
print("词汇表大小:", len(vocab))

输出结果:
词汇表(前10项): {'<PAD>': 0, '<UNK>': 1, '了': 2, '个': 3, '的': 4, '在': 5, '昨天': 6, 'NBA': 7, '篮球比赛': 8, '太精彩': 9}
词汇表大小: 50
【5】转换为ID序列
def texts_to_sequences(tokenized_texts, vocab):
sequences = []
for tokens in tokenized_texts:
seq = [vocab.get(token, vocab['<UNK>']) for token in tokens]
sequences.append(seq)
return sequences
sequences = texts_to_sequences(tokenized_texts, vocab)
print("\nID序列:")
for i, seq in enumerate(sequences):
print(f"{i+1}. {seq}")

输出结果:
ID序列: 1. [6, 7, 8, 9, 2, 10, 11, 2, 3, 12] 2. [13, 14, 15, 4, 16, 17, 18, 19, 20, 21, 22] 3. [23, 4, 24, 25, 26, 27, 28, 29, 2, 30, 31, 2] 4. [32, 33, 34, 35, 36] 5. [37, 38, 39, 5, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49] 6. [1, 1, 5, 1, 1, 1, 1, 1] 7. [1, 1, 1, 1, 1, 1, 1] 8. [1, 1, 1, 3, 1, 1, 1, 1, 1, 1]
【7】转换为词向量矩阵
import torch
import torch.nn as nn
class EmbeddingLayer(nn.Module):
def __init__(self, voc
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4772
4772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











