









Python 爬虫–[最简单的爬虫例子]
1、拷贝代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
movie_url = 'https://movie.douban.com/subject/1292052/'
def download_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_12)AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/47.0.2526.80 Safari/537.36 '
}
data = requests.get(url, headers=headers).content
return data
def paser_html(html):
soup = BeautifulSoup(html, 'lxml')
title = soup.find(property='v:itemreviewed').string
return title
def main():
print(paser_html(download_page(movie_url)))
if __name__ == '__main__':
main()
2、编译程序
- 可能会编译出错
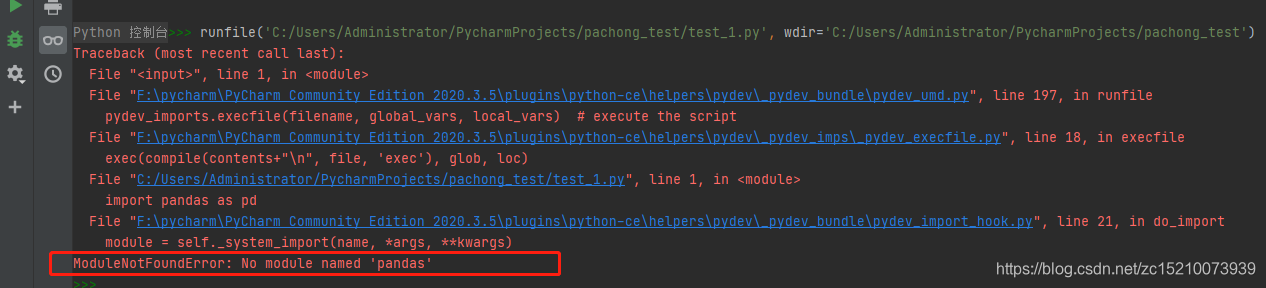
*我们主要关注最后一排报错,一般报错是因为缺少包,我们在pycharm的终端下载一下就好了。
例如:上图显示缺少 ‘pandas’
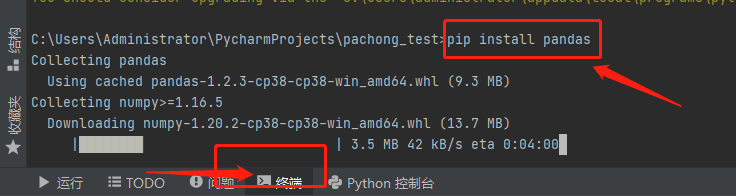
我们只需要点击终端,然后输入 pip install <缺失的包>
最后等待下载完成,重新编译就可以了~
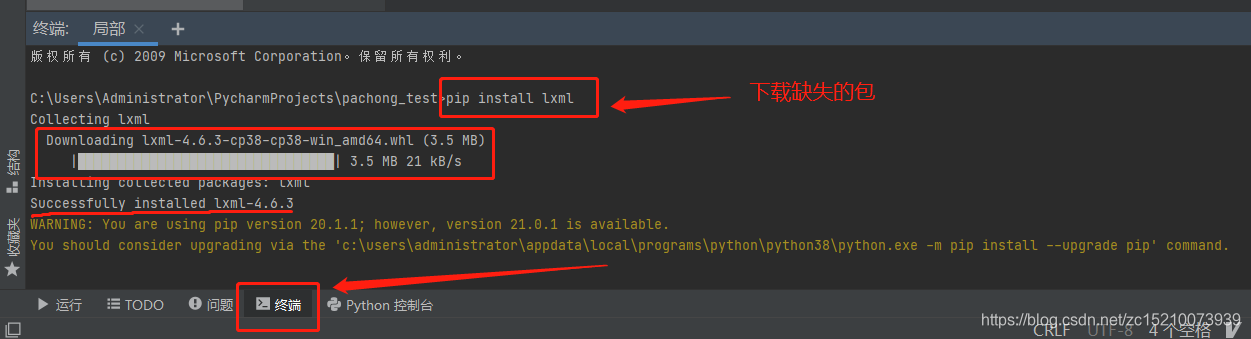
*例如缺少的是‘lxml’
同样的我们在终端输入: pip install lxml
等待下载完成,重新编译,就可以了~
3、实验结果
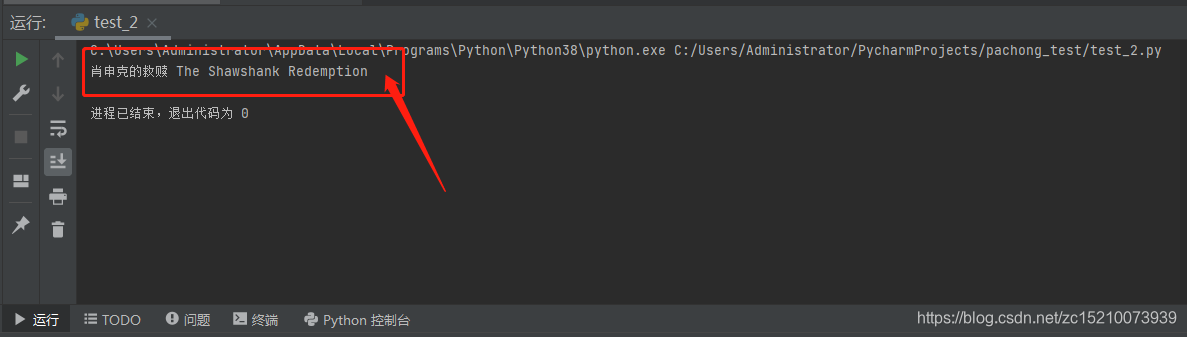
- 通过爬取豆瓣网站上的某个具体链接,我们爬取得到:该链接是电影《肖申克的救赎》 “The Shawshank Redemption”
总结
这是个非常简单的爬虫例子,通过这个例子,我们可以非常直观的看到爬虫是怎么通过代码爬取我们需要的信息,有了这一理性的认知之后,我们再从代码入手,一点点往里学习爬虫的奥秘,同时也可以学习python,就很好玩,对不对~
------[分界线]-------



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











