







 文章讲述了业务系统在异步积分初始化过程中遇到401未授权错误,经调查发现是由于Feign调用时带有已过期的Token,源于全局Feign拦截器将ThreadLocal中的Token传递。提供了三种解决方案,包括禁用线程上下文继承、动态刷新上下文和让业务方自选是否继承上下文。
文章讲述了业务系统在异步积分初始化过程中遇到401未授权错误,经调查发现是由于Feign调用时带有已过期的Token,源于全局Feign拦截器将ThreadLocal中的Token传递。提供了三种解决方案,包括禁用线程上下文继承、动态刷新上下文和让业务方自选是否继承上下文。
背景
当某业务发布计划后,将以异步方式启动积分初始化流程,以确保操作高效且不影响用户体验。初始化时涉及调用相关基础服务接口,获取必要的信息并执行积分计算。
同时实施了异常兜底策略,如果初始化出现问题导致失败,系统会自动定时进行重试。
某日,线上发现异步初始化时调用基础服务返回401-未授权的报错。
看了下兜底定时任务,调用基础服务正常,奇怪的很,难道基础服务不稳定?
异步流程时序图如下:
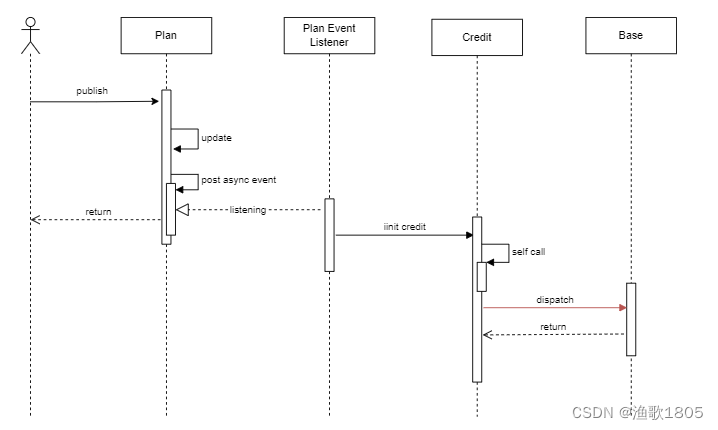
定位
首先尝试在测试环境复现,居然能复现,那就简单了呢;
在k8s容器内抓个包吧(fegin内部调用是基于http), 或通过打印详细日志、或使用Arthas都可以;
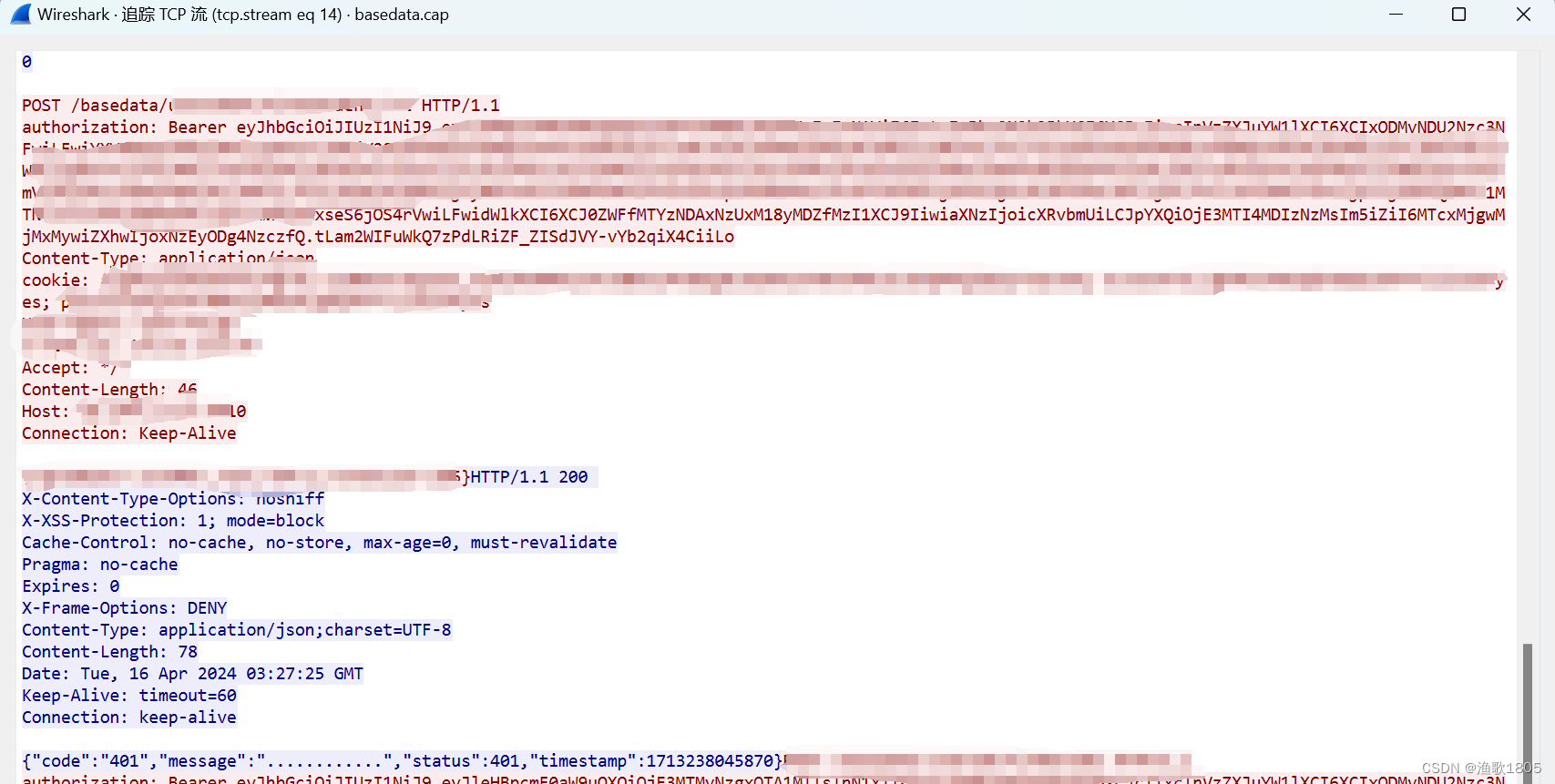
请求头中居然有authorization及token,而且token已经过期了,这就是请求基础服务导致401的原因;( 部分内部调用的接口定义无需token,但是传了会校验)
这里是异步处理业务,当前线程归属于线程池的核心线程,为啥会在feign请求时加上token的请求头?
这里其实大概有怀疑方向了;
我司框架定义的全局Feign拦截器headerInterceptor,会获取请求上下文,Feign调用时通过请求头传递请求上下文;(代码涉密,以下用类似代码说明)
@Bean
public RequestInterceptor headerInterceptor() {
return template -> {
Map<String, Collection<String>> headers = new HashMap<>();
Map<String, Collection<String>> localHeaders = HeadersHolder.getHeaders();
if (localHeaders != null && !localHeaders.isEmpty()){
headers.putAll(localHeaders);
}
// 省略其它
template.headers(headers);
};
}请求上下文类如下:
public class HeadersHolder {
private static final TransmittableThreadLocal<Map<String, Collection<String>>> LOCAL = new TransmittableThreadLocal<>();
public static void setBetaHeaders(Map<String, List<String>> headers){
LOCAL.set(headers);
}
public static Map<String, Collection<String>> getHeaders(){
return LOCAL.get();
}
public static void remove(){
LOCAL.remove();
}
}TransmittableThreadLocal是alibaba的transmittable-thread-local组件中的类:
transmittable-thread-local对应的MAVEN坐标如下:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>transmittable-thread-local</artifactId>
</dependency>TransmittableThreadLocal:在使用线程池等会池化复用线程的执行组件情况下传递ThreadLocal值;
那么,就很容易理解上面的现象;
异步事件使用了Google Guava库的AsyncEventBus类;
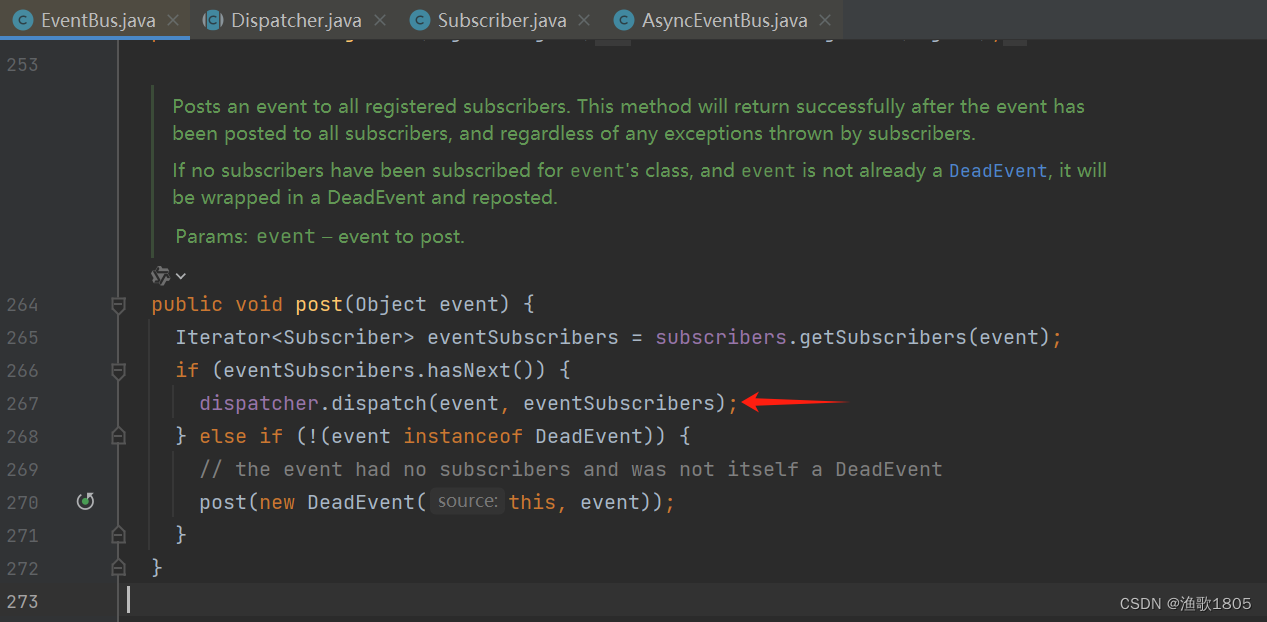
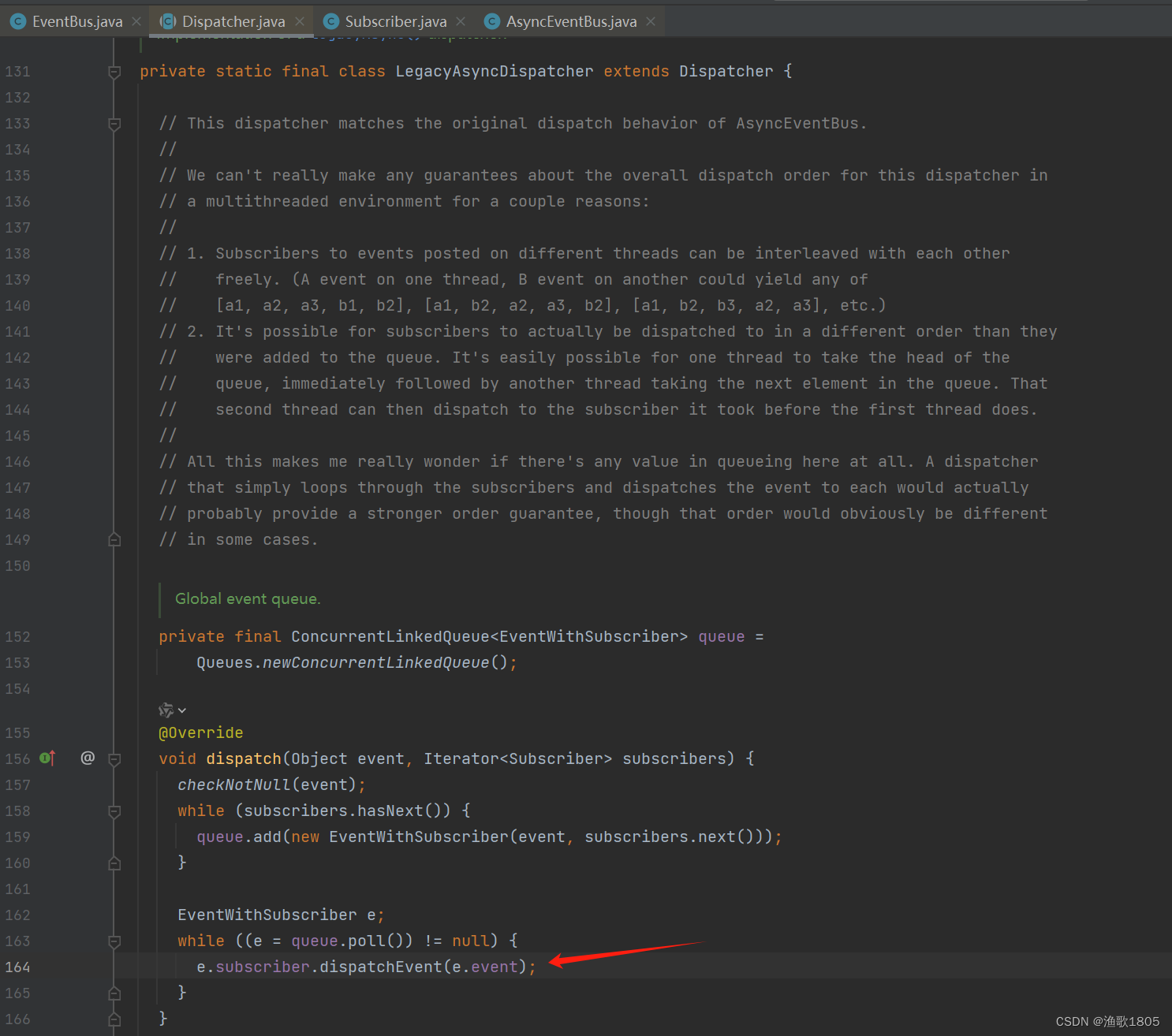
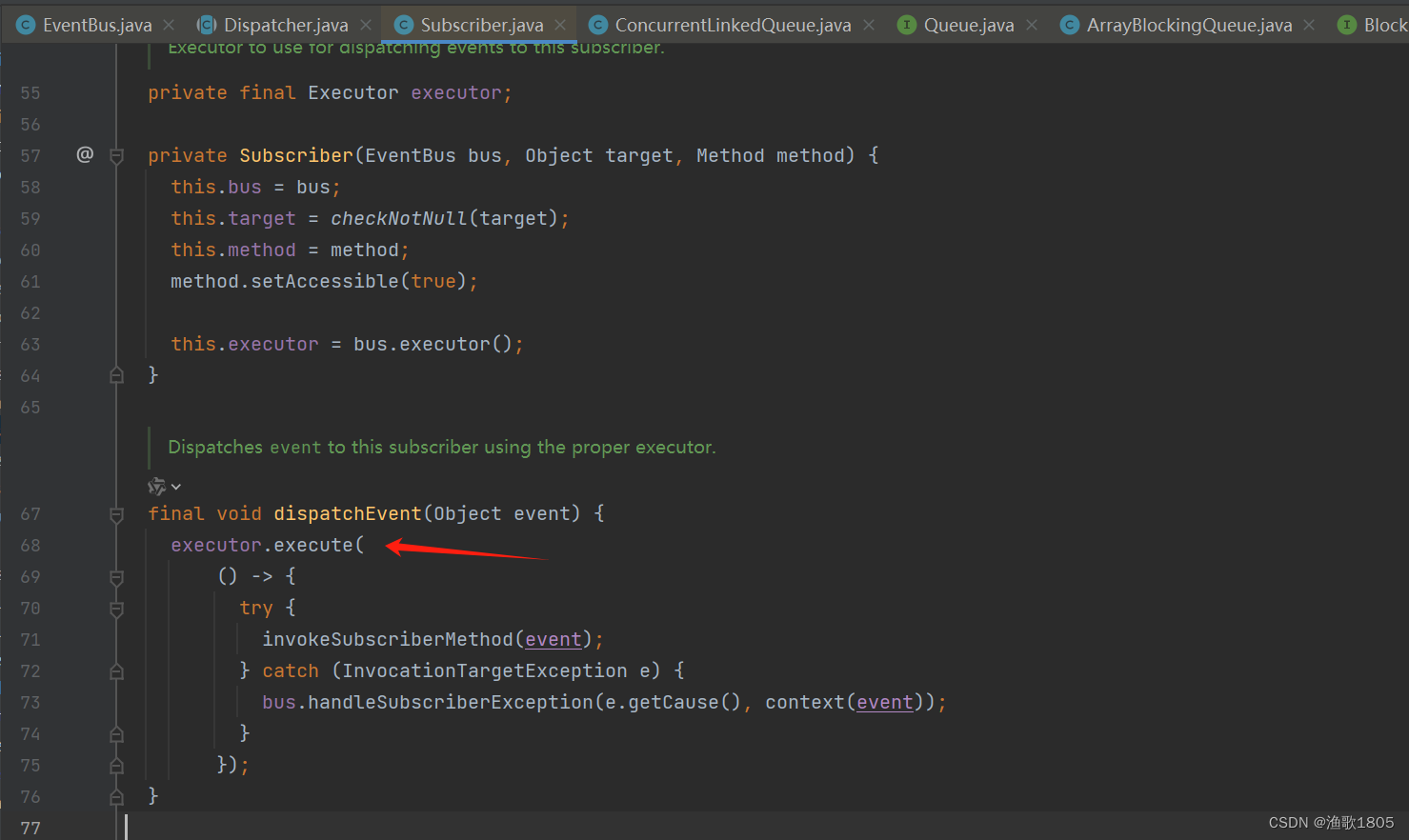
发布事件后,提交到线程池执行;如果线程池核心线程未满,此时创建核心线程,是基于当前tomcat的请求线程,会把当前ThreadLocal(包含token)存到线程池的核心线程里;
线程池的线程在调用内部feign接口时,会把token传过去,并且该核心线程后续的上下文都是当前这个上下文;
这就是问题所在啦~
解决
问题清晰之后,解决方案有很多种,也和架构师同学一起聊了聊,方案各有优缺取舍,列出如下:
方案一
某些业务代码很明确不需要用户上下文,使用TtlExecutors#getDisableInheritableThreadFactory包装ThreadFactory,这样在创建线程时就不会继承上下文;
优点: 线程池的线程上下文很干净;
缺点:线程上下文太干净了; 如果你的项目中使用了链路追踪、埋点日志等组件,也不会继承相关ThreadLocal信息,会导致收集不到信息;
@Bean
public EventBus asyncEventBus() {
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("async-event-pool-%d").build();
Executor threadPoolExecutor = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(QUEUE_CAPACITY), TtlExecutors.getDisableInheritableThreadFactory(namedThreadFactory));
return new AsyncEventBus(threadPoolExecutor);
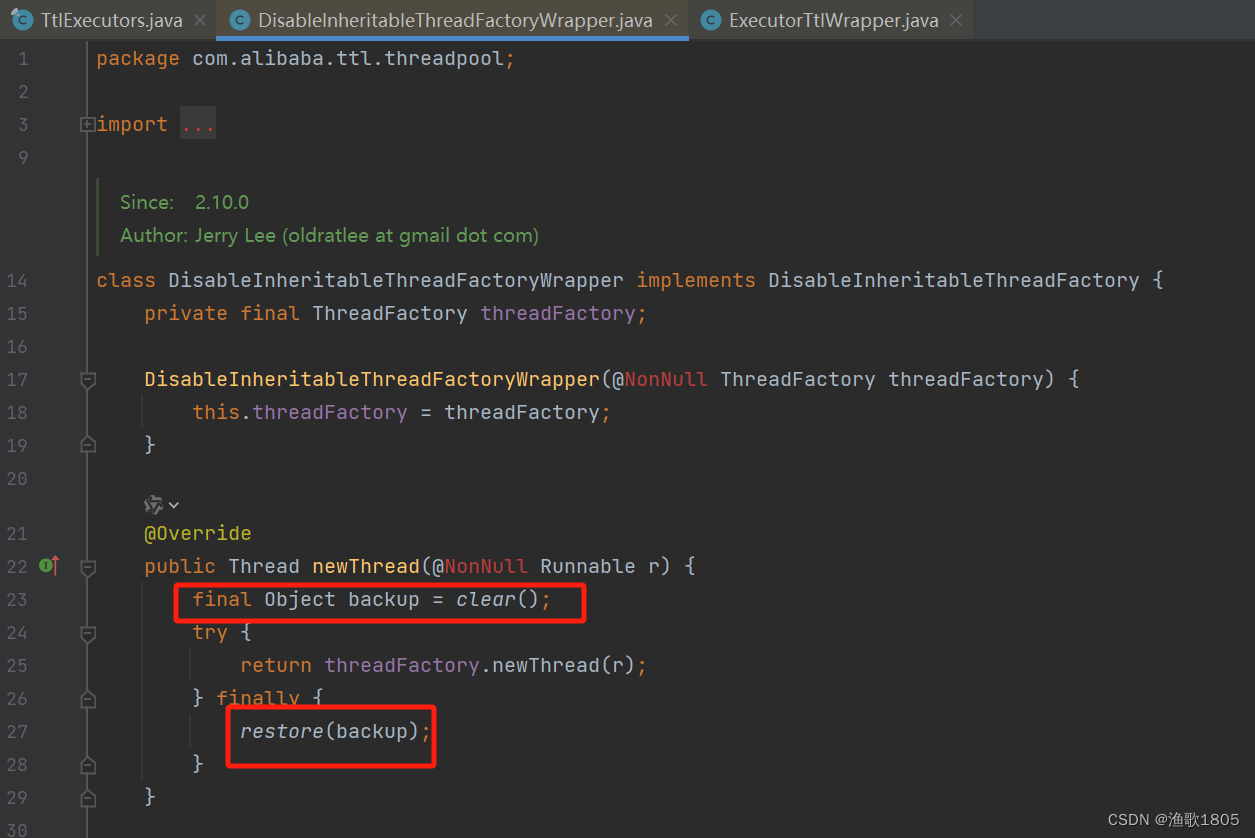
}源码中,DisableInheritableThreadFactoryWrapper类在创建子线程前备份及清理了上下文,创建子线程后又恢复了;
方案二
动态刷新线程池中线程的上下文;
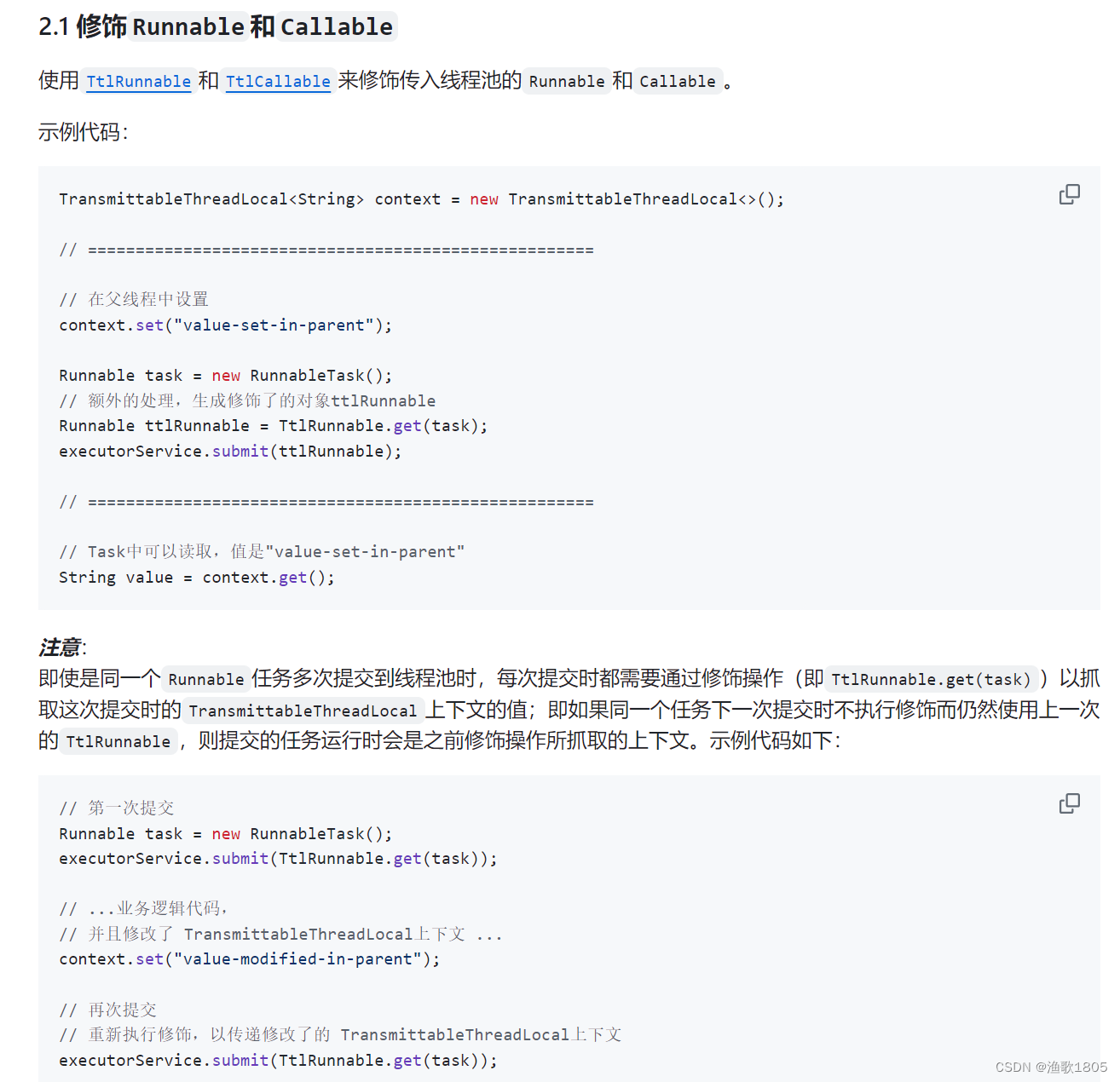
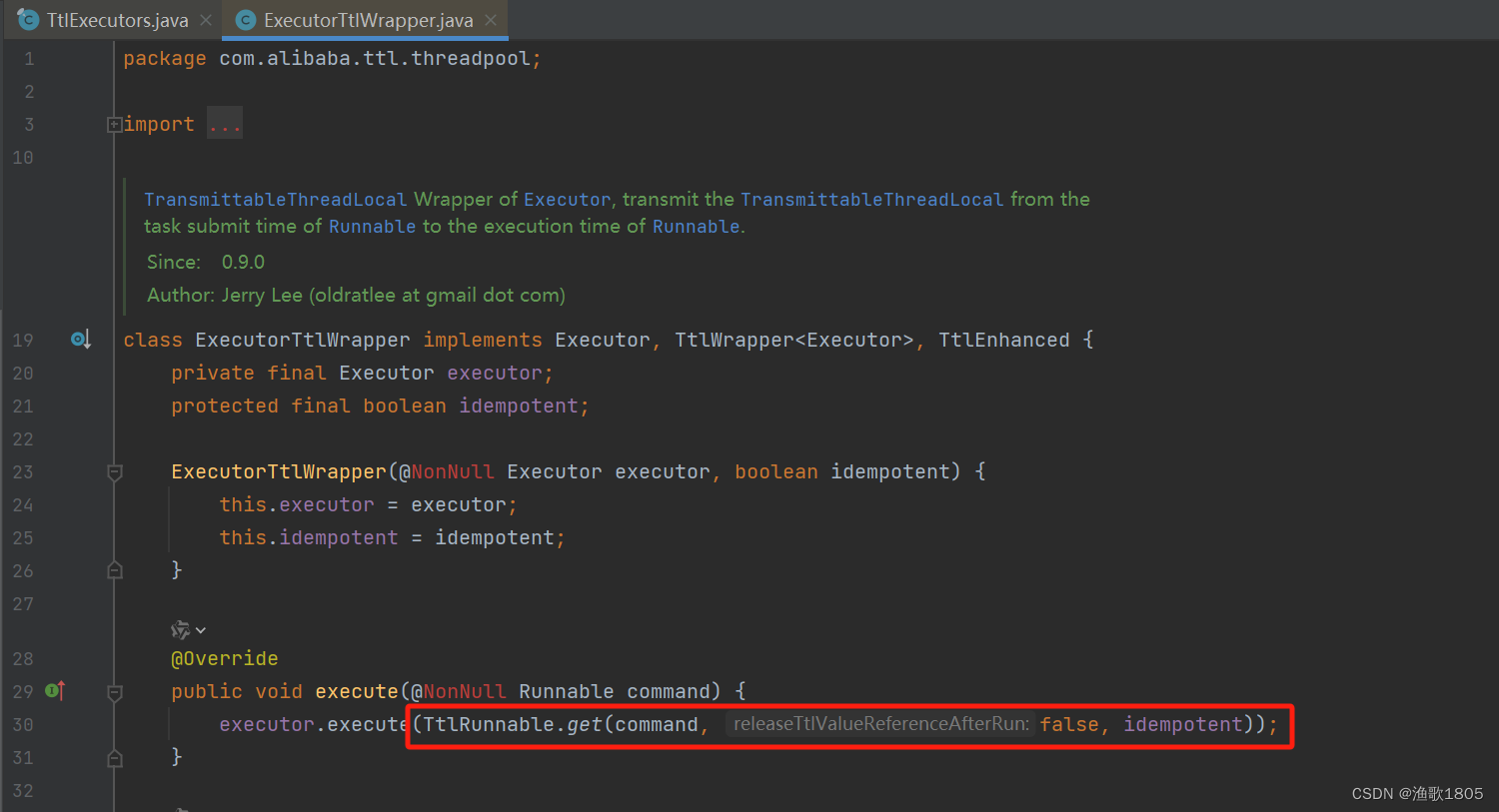
- 线程池执行任务时,使用TtlRunnable.get(task)包装Runable; (代码侵入较大,不建议)
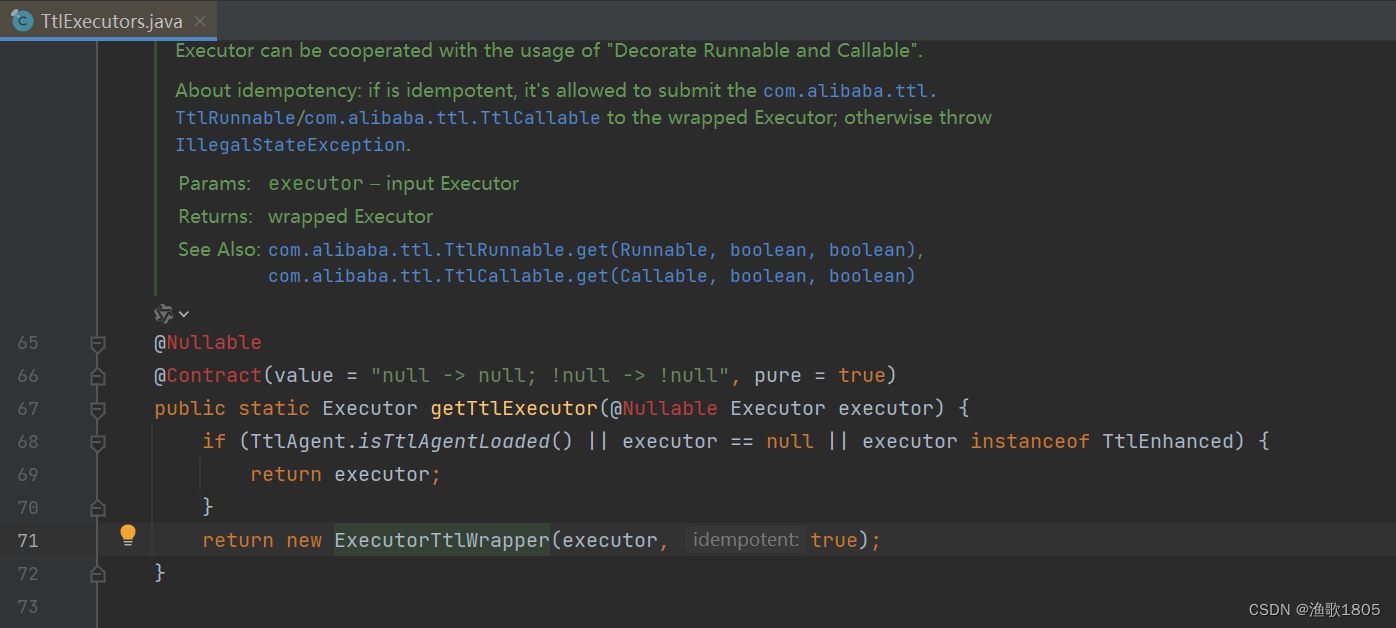
- 使用TtlExecutors#getTtlExecutor包装Executor; (代码侵入较小,建议)
优点:子线程实时刷新上下文;
缺点:某些场景中,子线程上下文我们可能不需要继承;
TtlExecutors#getTtlExecutor包装示例:
@Bean
public EventBus asyncEventBus() {
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("async-event-pool-%d").build();
Executor threadPoolExecutor = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(QUEUE_CAPACITY), namedThreadFactory);
return new AsyncEventBus(TtlExecutors.getTtlExecutor(threadPoolExecutor));
}Alibaba官方两种示例:
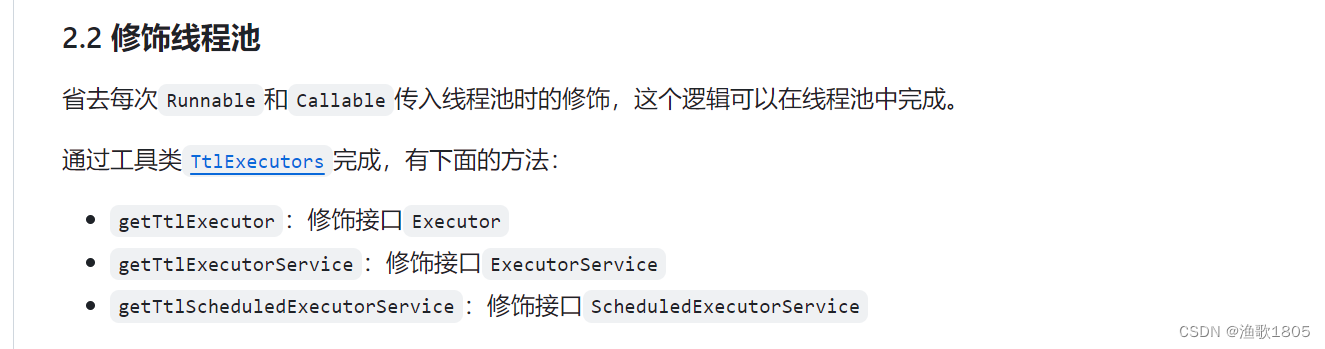
从源码看,方案二的两种包装最后都是调用的TtlRunnable.get;
方案三
借鉴思想,子线程需不需要业务的上下文,业务方其实是最清楚的,交给业务方选择使用。
提供一个ThreadFactory包装类,支持是否继承用户上下文ThreadLocal,业务方按需使用。(其余ThreadLocal默认都保留继承)

















 5451
5451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









