







下以此店为例:
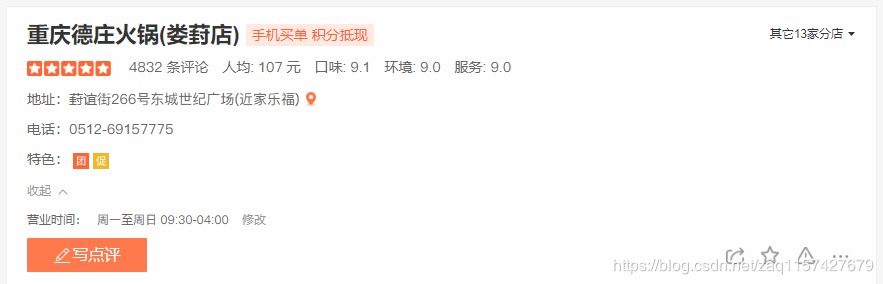
可以在源码中找到一个后缀为css的链接
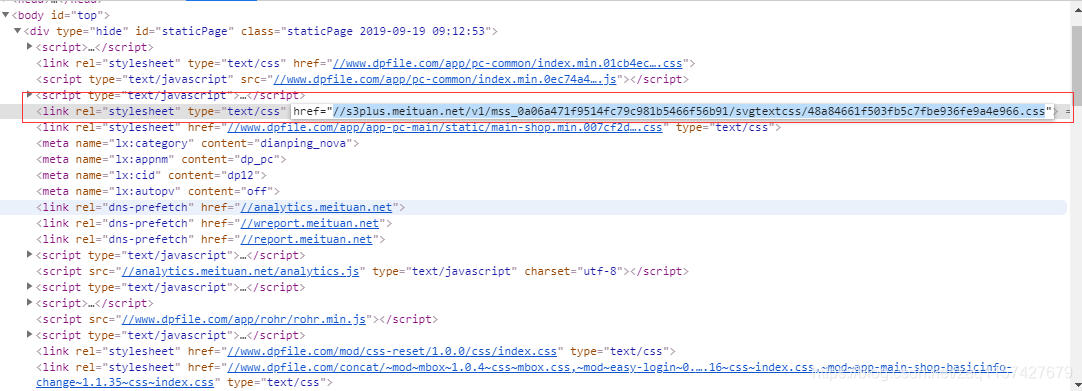 访问链接得到
访问链接得到
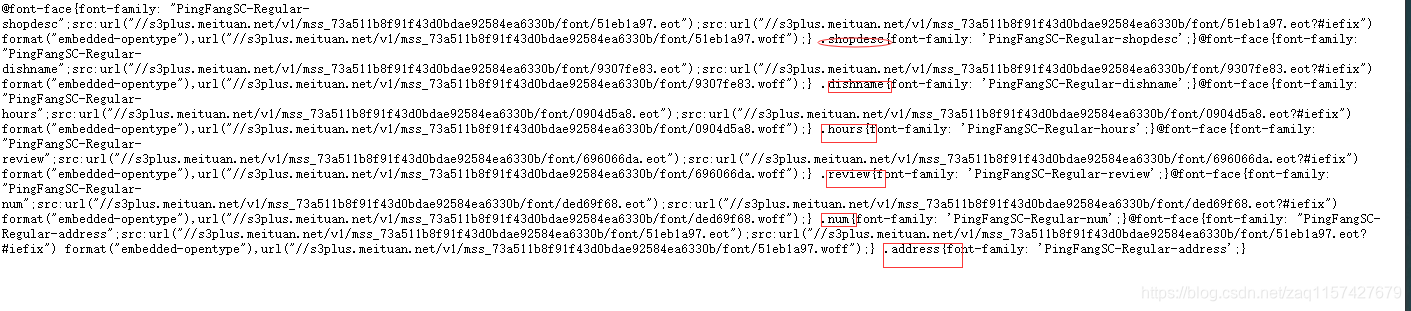
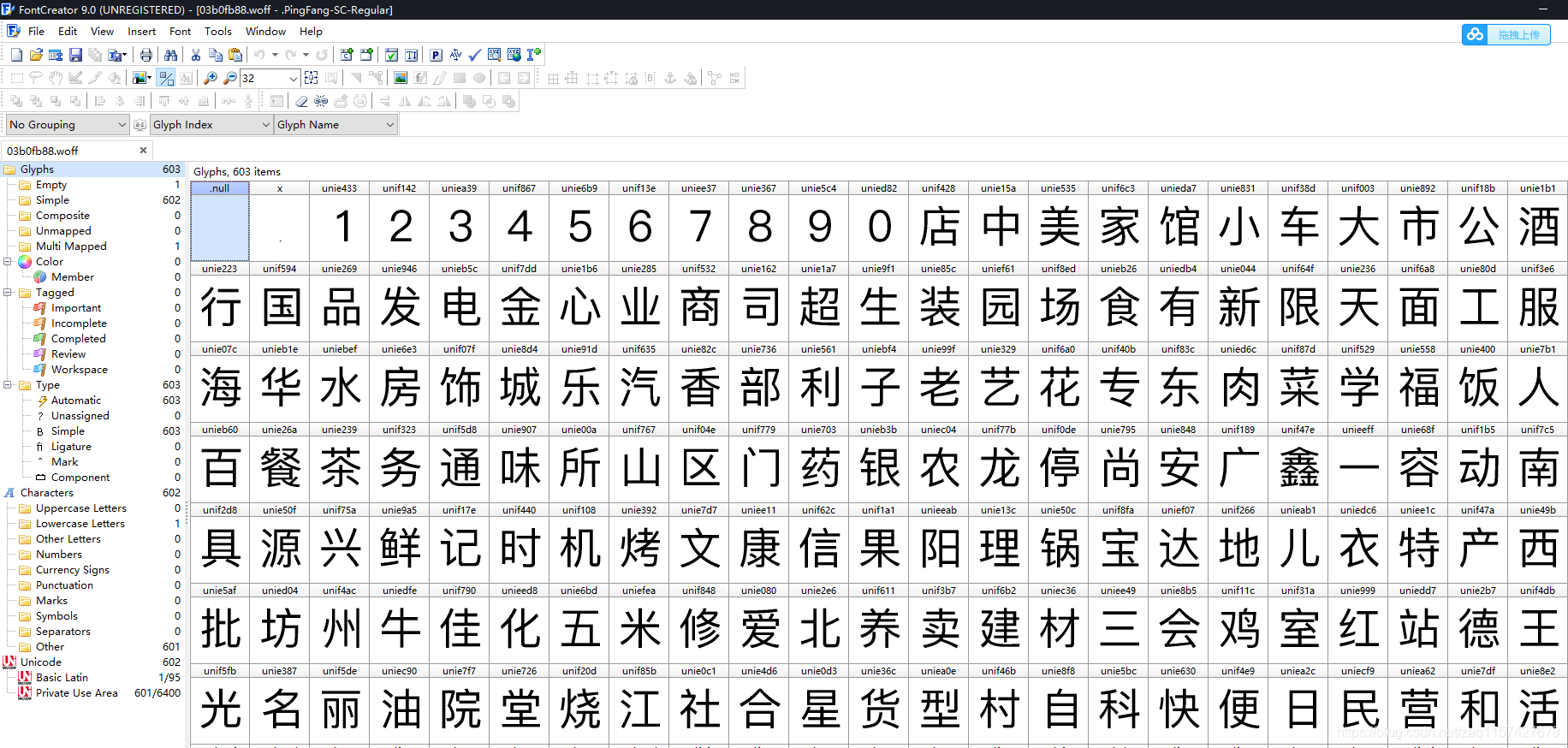
有六种加密字体,可以下载下来用fontcreate软件打开,试了多种办法没有找到快速生成对应字典的方法,那就只有手撸了。(如果你有方法,请评论分享一下,大家共同进步)
import requests
from lxml import etree
class DaZhong(object):
def __init__(self):
self.headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
'cookie':'cy=6; cye=suzhou; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; _lxsdk_cuid=16d47136832c8-04fe51d4cafd54-4c312373-1fa400-16d47136833c8; _lxsdk_s=16d47136833-993-88a-a2c%7C%7C125; _lxsdk=16d47136832c8-04fe51d4cafd54-4c312373-1fa400-16d47136833c8; _hc.v=4f50d523-576f-480b-0924-c26da6953b89.1568855518; s_ViewType=10'
}
def get_content(self):
url = 'http://www.dianping.com/shop/5417836'
r = requests.get(url,headers=self.headers)
tree = etree.HTML(r.text)
# 店名
name = tree.xpath('//h1[@class="shop-name"]/text()')[0]
# 评论数
comment_class = tree.xpath('//span[@id="reviewCount"]/*/@class')
comment_list = tree.xpath('//span[@id="reviewCount"]/*/text()')
comment_content = tree.xpath('//span[@id="reviewCount"]//text()')
# 人均
avg_class = tree.xpath('//span[@id="avgPriceTitle"]/*/@class')
avg_list = tree.xpath('//span[@id="avgPriceTitle"]/*/text()')
avg_content = tree.xpath('//span[@id="avgPriceTitle"]//text()')
# 口味
taste_class = tree.xpath('//span[@id="comment_score"]/span[1]/*/@class')
taste_list = tree.xpath('//span[@id="comment_score"]/span[1]/*/text()')
taste_content = tree.xpath('//span[@id="comment_score"]/span[1]//text()')
# 环境
environment_class = tree.xpath('//span[@id="comment_score"]/span[2]/*/@class')
environment_list = tree.xpath('//span[@id="comment_score"]/span[2]/*/text()')
environment_content = tree.xpath('//span[@id="comment_score"]/span[2]//text()')
# 服务
service_class = tree.xpath('//span[@id="comment_score"]/span[3]/*/@class')
service_list = tree.xpath('//span[@id="comment_score"]/span[3]/*/text()')
service_content = tree.xpath('//span[@id="comment_score"]/span[3]//text()')
# 地址
area_class = tree.xpath('//div[@id="J_map-show"]/span/*/@class')
area_list = tree.xpath('//div[@id="J_map-show"]/span/*/text()')
area_content = tree.xpath('//div[@id="J_map-show"]/span//text()')
# 电话
phone_class = tree.xpath('//p[@class="expand-info tel"]/*/@class')
phone_list = tree.xpath('//p[@class="expand-info tel"]/*/text()')
phone_content = tree.xpath('//p[@class="expand-info tel"]//text()')
# 营业时间
time_class = tree.xpath('//p[@class="expand-info tel"]/*/@class')
time_list = tree.xpath('//p[@class="expand-info tel"]/*/text()')
time_content = tree.xpath('//p[@class="expand-info tel"]//text()')
print(name)
print(comment_class)
print(comment_list)
print(comment_content)
print(avg_class)
print(avg_list)
print(avg_content)
print(taste_class)
print(taste_list)
print(taste_content)
print(environment_class)
print(environment_list)
print(environment_content)
print(service_class)
print(service_list)
print(service_content)
print(area_class)
print(area_list)
print(area_content)
print(phone_class)
print(phone_list)
print(phone_content)
print(time_class)
print(time_list)
print(time_content)
if __name__ == '__main__':
dz = DaZhong()
dz.get_content()
结果如下:

然后对拿到的加密字段用字典进行解密,拼接可得到明文。


















 2047
2047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









