craete orreplaceview test2_02 as(select sid, name
from pub.student
where sid in(select sid
from pub.sudent_course
where cid in(select cid
from pub.student_course
where sid=200900130417)))
minus (select sid, name
from pub.student
where sid=200900130417);
"至少" 表示 “存在”
模式和上一题一样:先找一个参考表,再依据参考表筛选
solution 1:
select sid, name
from pub.student
where sid in(select sid
from pub.student_course
where cid in(select cid
from pub.course
where fcid=300002));
solution 2:
select sid, name
from pub.student_course naturaljoin pub.student
where cid in(select cid
from pub.course
where fcid=300002);
select sid, name
from pub.student naturaljoin pub.student_course
where sid in(select sid
from pub.student_course
where cid =300002)and sid in(select sid
from pub.student_course
where cid =300005)and sid notin(from pub.student_course
where cid =300001);
“平均值”: 分组聚集
1. 找到分组标准
2. 明确聚集函数类型再计算
注意:SQL的书面写法更名要有 as ,即 avg(score) as avg_score
select sid, name,round(avg(score)) avg_score,sum(sore) sum_score
from pub.student naturaljoin pub.student_course
where age=20groupby sid, name
select a.cid, a.name, max_score, max_score_count
from(select cid, name
from pub.course
) a,(select sc.cid,count(distinct sid) max_score_count
from pub.student_course
groupby cid
) b,(select sc.cid,count(distinct sid) max_score_count
from pub.student_course sc,(select cid,max(score) max_score from pub.student_course
groupby cid
) max_sc
where sc.cid=max_sc.cid and sc.score=max_sc.max_score
groupby sc.cid
) d
where a.cid = b.cid and b.cid = d.cid
like 语句
select sid, name
from pub.student
minus (select sid,name
from pub.student
where name like'张%'or name like'李%'or name like'王%');
字串函数 substr(pos, len)
count(*) 为自己计数
select substr(name,1,1)second_name,count(*) p_count
from pub.student
groupby substr(name,1,1)
select sid, name, score
from pub.student naturaljoin pub.student_course
where cid =300003;
本质还是计数的聚合,就是外面再套一层选择
select sid, name
from pub.student
where sid in(select sid
from(select sc.sid, sc.cid,count(*) count
from pub.student_course sc
where score <60groupby sc.sid, sc.cid
)where count >=2);








 本文详细讲解了SQL实验中的集合操作,如‘至少’筛选和‘至少存在’查询,以及如何使用IN和DISTINCT。还介绍了聚合函数如平均值、最高分计数,通过实例演示如何结合分组和子查询。最后展示了如何运用LIKE、substr和COUNT等函数进行字符串处理和数据筛选。
本文详细讲解了SQL实验中的集合操作,如‘至少’筛选和‘至少存在’查询,以及如何使用IN和DISTINCT。还介绍了聚合函数如平均值、最高分计数,通过实例演示如何结合分组和子查询。最后展示了如何运用LIKE、substr和COUNT等函数进行字符串处理和数据筛选。

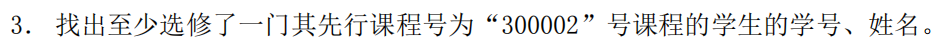



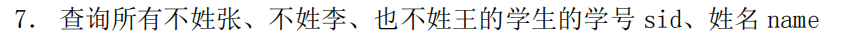





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









