







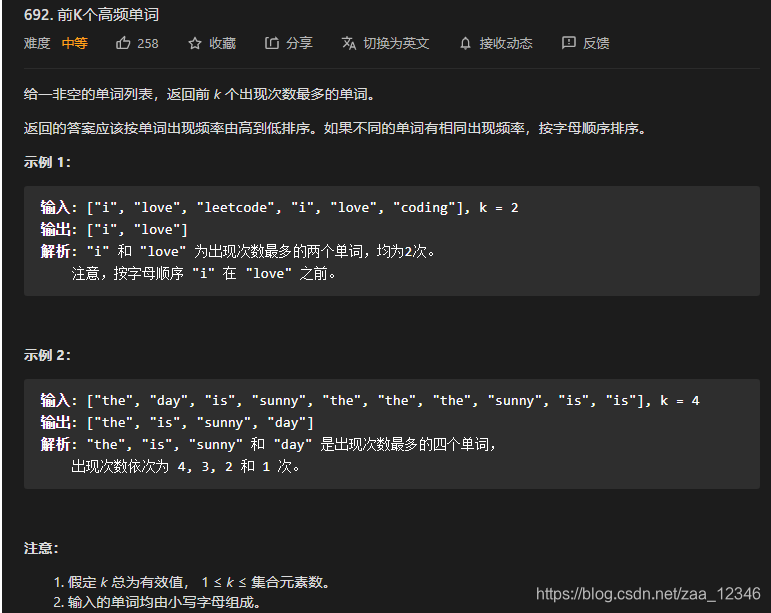
题目出处:https://leetcode-cn.com/problems/top-k-frequent-words/
方法1:哈希表+排序
思路:用哈希表记录每个单词出现的次数,再按照每个单词出现的次数降序排列(若不同单词出现的次数相同,则按照字符串大小排列)
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
unordered_map<string, int> mp;
for(string & s : words){
++mp[s];
}
vector<string> ans;
for(auto & [str, cnt] : mp){
ans.push_back(str);
}
sort(ans.begin(), ans.end(), [&](const string &a, const string &b){
if(mp[a] == mp[b]){
return a < b;
}
return mp[a] > mp[b];
});
ans.erase(ans.begin() + k, ans.end());
return ans;
}
};
方法2:优先级队列+哈希表
topK问题:前k个最大元素用最小堆,前k个最小元素用最大堆
typedef pair<string, int> ll;
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
unordered_map<string, int> mp;
for(string & s : words){
++mp[s];
}
auto cmp = [](const ll & a, const ll & b){
if(a.second == b.second){
return a < b;
}
return a.second > b.second;
};
priority_queue<ll, vector<ll>, decltype(cmp)> q(cmp); //构造小根堆
for(auto & ele : mp){
q.push(ele);
if(q.size() > k){
q.pop();
}
}
vector<string> ret(k);
for (int i = k - 1; i >= 0; i--) {
ret[i] = q.top().first;
q.pop();
}
return ret;
}
};
注意点
上述两个代码均用lambda表达式重写priority_queue方法、重写sort方法。
仿函数版本
typedef pair<string, int> ll;
struct cmp{ //仿函数
bool operator()(const ll &a, const ll &b){
if(a.second == b.second){
return a < b;
}
return a.second > b.second;
}
};
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
unordered_map<string, int> mp;
for(string & s : words){
++mp[s];
}
priority_queue<ll, vector<ll>, cmp> q; //构造小根堆
for(auto & ele : mp){
q.push(ele);
if(q.size() > k){
q.pop();
}
}
vector<string> ans(k);
int index = k-1;
while(!q.empty()){
ans[index--] = q.top().first;
q.pop();
}
return ans;
}
};

















 490
490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









