




知识点回顾:
- 预训练的概念
- 常见的分类预训练模型
- 图像预训练模型的发展史
- 预训练的策略
- 预训练代码实战:resnet18
作业:
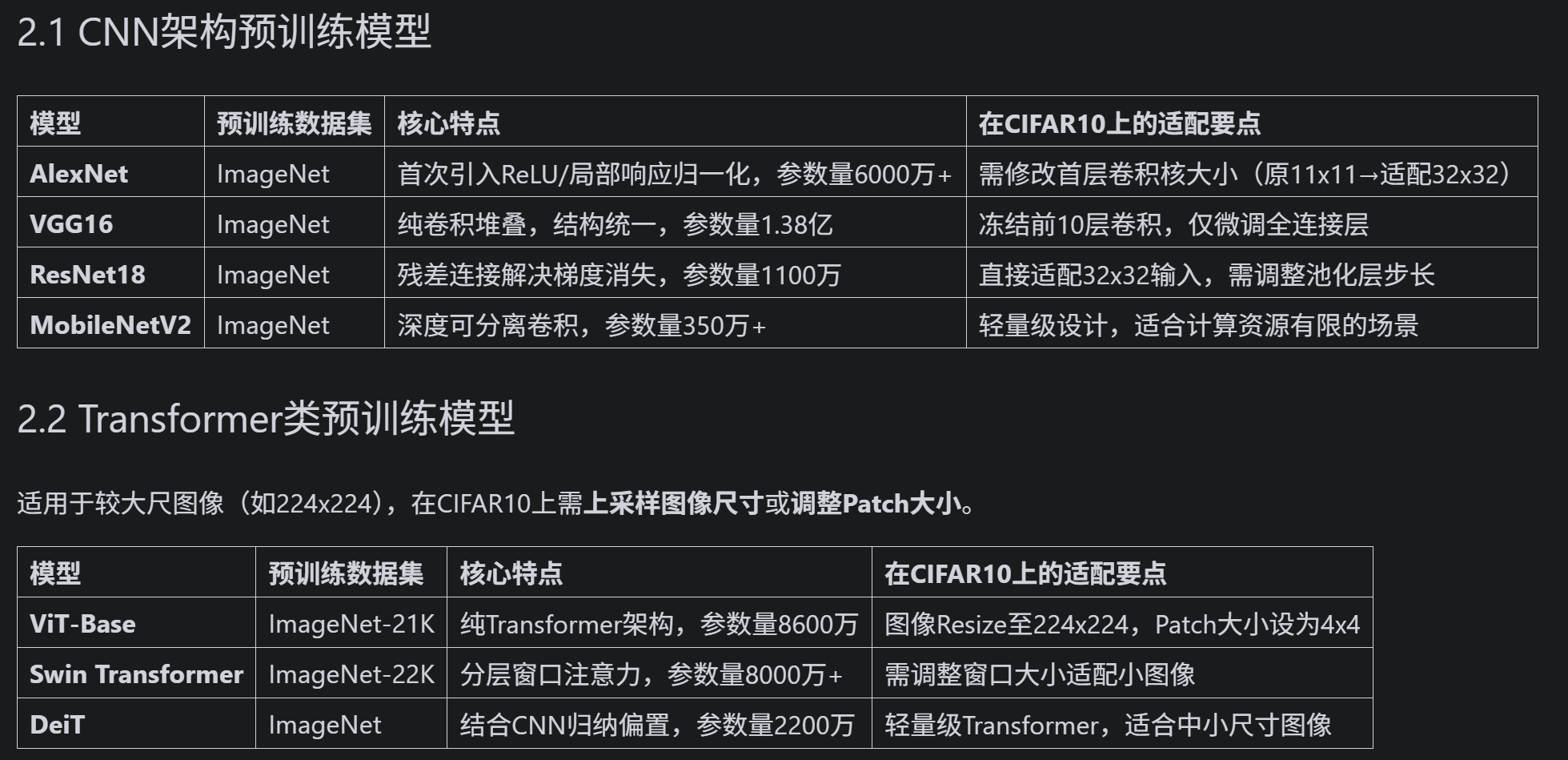
- 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同
- 尝试通过ctrl进入resnet的内部,观察残差究竟是什么
一、预训练的概念
因为准确率最开始随着epoch的增加而增加,随着循环的更新,参数在不断发生更新
所以参数的初始值对训练结果有很大的影响:如果最开始的初始值比较好,后续训练的轮数就会少很多,不同的初始值可能会导致陷入不同的局部最优解
所以如果最开始能有比较好的参数,即可能导致未来训练次数少,也可能导致未来训练避免陷入局部最优解的问题。由此引出预训练模型。
1. 那为什么要选择类似任务的数据集预训练的模型参数呢?
因为任务差不多,他提取特征的能力才有用,如果任务相差太大,他的特征提取能力就没那么好。
所以本质预训练就是拿别人已经具备的通用特征提取能力来接着强化能力使之更加适应我们的数据集和任务。
2. 为什么要求预训练模型是在大规模数据集上训练的,小规模不行么?
因为提取的是通用特征,所以如果数据集数据少、尺寸小,就很难支撑复杂任务学习通用的数据特征。比如你是一个物理的博士,让你去做小学数学题,很快就能上手;但是你是一个小学数学速算高手,让你做物理博士的课题,就很困难。所以预训练模型一般就挺强的。
我们把用预训练模型的参数,然后接着在自己数据集上训练来调整该参数的过程叫做微调,这种思想叫做迁移学习。把预训练的过程叫做上游任务,把微调的过程叫做下游任务。
这里给大家介绍一个常常用来做预训练的数据集,ImageNet,ImageNet 1000 个类别,有 1.2 亿张图像,尺寸 224x224,数据集大小 1.4G,下载地址:http://www.image-net.org/。
二、经典的预训练模型

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









