




摘要
联邦学习旨在在不访问客户端本地私人数据的情况下,协作训练模型。由于不同客户端的数据可能是非独立同分布(Non-IID)的,这可能导致性能较差。最近,个性化联邦学习(PFL)通过在本地优化中引入正则化或改善服务器上的模型聚合方案,在处理非IID数据方面取得了很大成功。然而,大多数PFL方法并未考虑由数据分布不均衡和每个客户端中某些类别缺乏正样本所引发的不公平竞争问题。为了解决这一问题,我们提出了一种新颖且通用的PFL框架,称为基于二分类的联邦平均(Federated Averaging via Binary Classification),简称FedABC。具体而言,我们在每个客户端采用“一对多”(one-vs-all)训练策略,通过为每个类别构建个性化的二分类问题,来缓解类别间的不公平竞争。这可能加剧类别不平衡问题,因此我们设计了一种新颖的个性化二分类损失函数,结合了欠采样和困难样本挖掘策略。在不同设置下,我们在两个流行的数据集上进行了大量的实验,结果表明我们的FedABC显著优于现有的同类方法。
前言
联邦学习中的一个关键挑战是在非独立同分布(non-i.i.d.)数据下进行训练(Hsieh等,2020)。由于不同客户端之间的数据分布差异,通过简单平均获得的单一全局模型(GM)难以满足所有异构客户端的需求。此外,客户端在其本地数据集上更新全局模型,导致本地模型与全局模型不一致,进而引发权重发散(weight divergence)(Zhao等,2018)。这些问题已被发现会导致收敛不稳定且缓慢(Li等,2020),甚至可能造成极差的性能表现(Li等,2021a)。
为了应对联邦学习(FL)中的异质性问题,已经提出了许多解决方案,例如通过约束本地模型更新的方向来对齐本地和全局优化目标的方法(Li et al. 2020; Karimireddy et al. 2020; Acar et al. 2021; Zhang et al. 2022; Liu et al. 2022)。个性化联邦学习(PFL)(Smith et al. 2017; Huang et al. 2022b; Dai et al. 2022)是一种有前景的解决方案,它通过联合学习多个个性化模型(PMs)来应对这一挑战,每个客户端对应一个模型。例如,参考文献(Collins et al. 2021; Liang et al. 2020; Sun et al. 2021)采用了灵活的参数共享策略(parameter sharing strategies),仅传输部分模型参数,并使用可学习的全局模型对本地模型进行正则化(T Dinh, Tran, and Nguyen 2020; Hanzely et al. 2020; Li et al. 2021b)。Dai et al. (2022) 和 Huang et al. (2022b) 则采用稀疏训练(sparse training)来实现个性化。
然而,所有这些方法仅仅是在额外引入正则化或改善聚合策略,而忽略了联邦学习(FL)客户端中经常存在的某些极端数据分布情况(见图1)。这些情况可以分为两类:
1)类别不平衡分布(He和Garcia,2009),其中某些类别的样本数量比其他类别多得多或少得多;
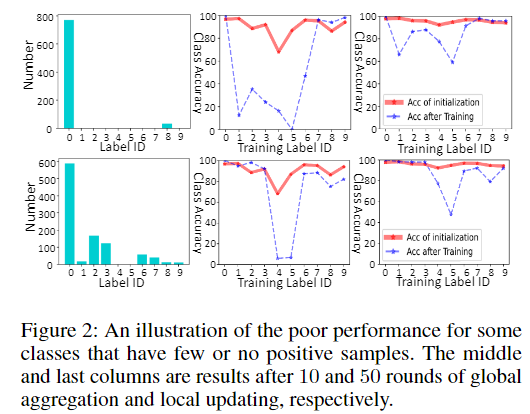
2)某些类别缺乏正样本,而且这种情况的发生概率随着异质性的增加而增加。
在这些极端情况下,如果采用普遍的 Softmax 函数(结合交叉熵损失)(Jang, Gu, 和 Poole 2016),则归一化会强制所有类别的 logits 之和为 1,从而导致不同类别之间的竞争。也就是说,增加一个类别的置信度必然会降低其他类别的置信度。这很容易导致主导类别的 过度自信预测(over-confident predictions)(Guo 等人,2017)、少数类的 次优性能(sub-optimal performance),以及缺乏正样本的类别 极差的性能(见图2)。尽管与服务器的通信可以在一定程度上缓解这一问题,但每个模型的神经网络权重可能会被随机排列,因此很难完全整合所有客户端的知识。此外,在本地模型中表现差的类别,通过对所有模型的 逐点平均(point-wise-averaging),也很难实现良好的全局性能。
为了解决联邦学习客户端中类别间的不公平竞争问题,我们提出了一种新方法 FedABC(基于二分类的联邦平均),它在标准个性化联邦学习(PFL)基础上提升了性能。该方法采用了著名的 "一对多" 策略(Rifkin和Klautau,2004;Wen等人,2021),以减少类别间的不公平竞争,并更加关注个性化类别。与传统的基于 Softmax 的多类别分类训练不同,我们的 FedABC 对每个类别执行二分类任务,其中特征提取器对于不同类别是共享的。具体而言,假设训练集有 K 个类别,FedABC 将构建 K 个二分类问题,其中目标类别的数据被视为正样本,而其余类别的数据被视为负样本。通过采用这一策略,正样本较少甚至没有正样本的类别不会在预测时被多数类别压制,从而可以避免不公平竞争。这使得我们能够专注于每个类别,并个性化地处理其数据不平衡或缺乏正样本的问题,这些问题通过设计一种新颖且有效的二分类损失函数来解决,该损失函数结合了 欠采样(under-sampling)(Yen 和 Lee,2009)和 硬样本挖掘(hard-sample mining)(Schroff,Kalenichenko 和 Philbin,2015;Wu 等人,2017)策略。这些策略专注于学习硬样本,并减少容易样本的影响。总结来说,本文的主要贡献包括:
- 提出了一个新颖的联邦学习方法 FedABC,该方法采用二分类策略,提高了每个类别的个性化学习,并解除了不同类别在异质客户端中的不公平竞争;
- 设计了一种有效的二分类损失函数,通过结合困难样本挖掘和欠采样策略,缓解了数据不平衡和正样本不足的问题。
我们在两个流行的视觉数据集(CIFAR-10 和 MNIST)上进行了大量实验,涵盖了四种异质性设置。结果表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 389
389



 到【灌水乐园】发言
到【灌水乐园】发言








