







 本文主要探讨了Flink处理数据倾斜的问题,包括如何判断数据倾斜、解决keyBy后的聚合操作倾斜、keyBy前的数据倾斜以及窗口聚合操作的倾斜。提出了LocalKeyBy、shuffle、rebalance等方法,并给出了具体实现案例和优化思路。
本文主要探讨了Flink处理数据倾斜的问题,包括如何判断数据倾斜、解决keyBy后的聚合操作倾斜、keyBy前的数据倾斜以及窗口聚合操作的倾斜。提出了LocalKeyBy、shuffle、rebalance等方法,并给出了具体实现案例和优化思路。
第4章 数据倾斜
4.1 判断是否存在数据倾斜
相同 Task 的多个 Subtask 中,个别 Subtask 接收到的数据量明显大于其他 Subtask 接收到的数据量,通过 Flink Web UI 可以精确地看到每个 Subtask 处理了多少数据,即可判断出 Flink 任务是否存在数据倾斜。通常,数据倾斜也会引起反压。
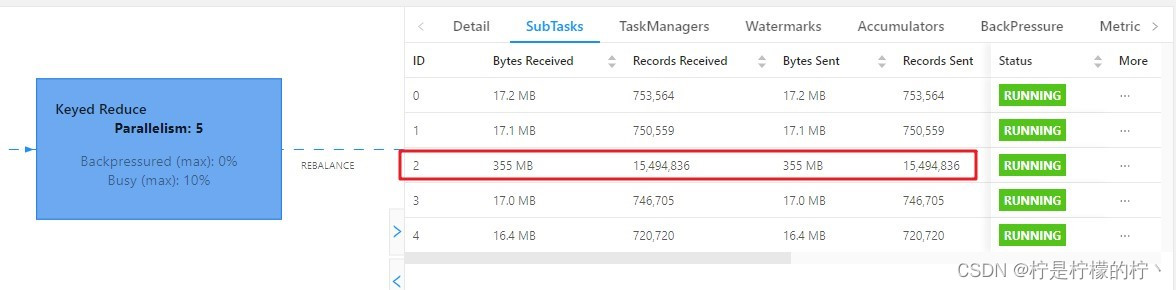
另外, 有时 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾
斜的有用指标。
4.2 数据倾斜的解决
4.2.1 keyBy 后的聚合操作存在数据倾斜
提交案例:
| bin/flink run \ -t yarn-per-job \ -d \ -p 5 \ -Drest.flamegraph.enabled=true \ -Dyarn.application.queue=test \ -Djobmanager.memory.process.size=1024mb \ -Dtaskmanager.memory.process.size=2048mb \ -Dtaskmanager.numberOfTaskSlots=2 \ -c com.atguigu.flink.tuning.SkewDemo1 \ /opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar \ --local-keyby false |
查看 webui:
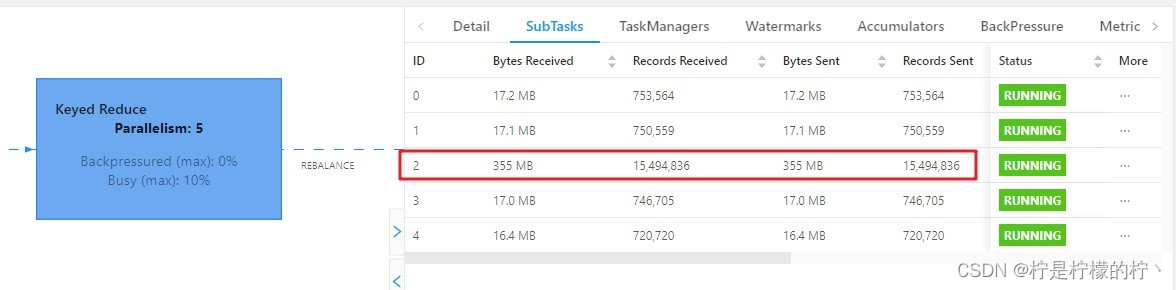
1)为什么不能直接用二次聚合来处理
Flink 是实时流处理,如果 keyby 之后的聚合操作存在数据倾斜,且没有开窗口(没攒
批)的情况下,简单的认为使用两阶段聚合,是不能解决问题的。因为这个时候 Flink 是来
一条处理一条,且向下游发送一条结果,对于原来 keyby 的维度(第二阶段聚合)来讲,
数据量并没有减少,且结果重复计算(非 FlinkSQL,未使用回撤流),如下图所示:
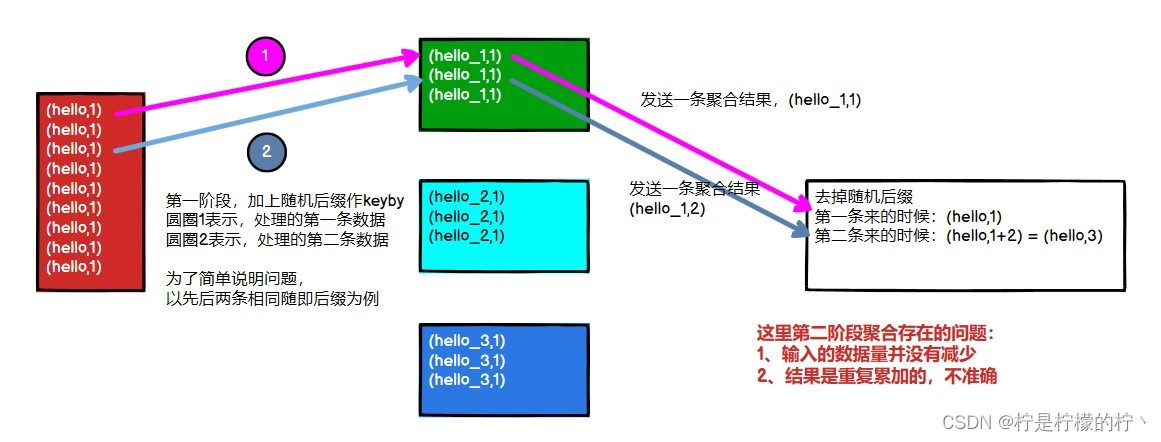
2)使用 LocalKeyBy 的思想在 keyBy 上游算子数据发送之前,首先在上游算子的本地对数据进行聚合后,再发送到下游,使下游接收到的数据量大大减少,从而使得 keyBy 之后的聚合操作不再是任务的瓶颈。类似 MapReduce 中 Combiner 的思想,但是这要求聚合操作必须是多条数据或者一批数据才能聚合,单条数据没有办法通过聚合来减少数据量。从 Flink LocalKeyBy 实现原理来讲,必然会存在一个积攒批次的过程,在上游算子中必须攒够一定的数据量,对这些数据聚合后再发送到下游。
实现方式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









