




 本文深入浅出地介绍了K-means聚类算法的工作原理,包括如何通过迭代过程找到最优质心,以及算法的优缺点。同时,提供了详细的Python代码实现,演示了如何从随机生成的数据点中进行聚类。
本文深入浅出地介绍了K-means聚类算法的工作原理,包括如何通过迭代过程找到最优质心,以及算法的优缺点。同时,提供了详细的Python代码实现,演示了如何从随机生成的数据点中进行聚类。
K-means算法介绍
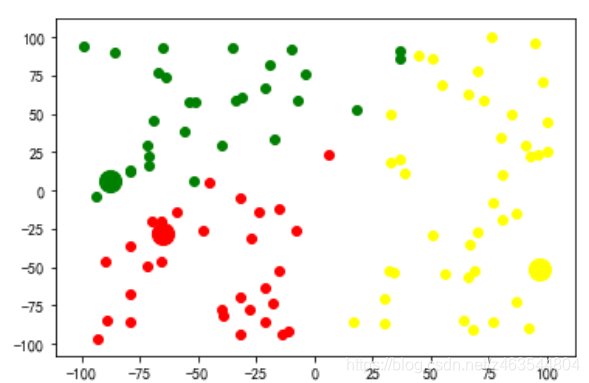
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
算法过程如下:
1)从N个文档随机选取K个文档作为中心点;
2)对剩余的每个文档测量其到每个中心点的距离,并把它归到最近的质心的类;
3)重新计算已经得到的各个类的中心点;
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束。
算法优缺点:
优点:
- 原理简单
- 速度快
- 对大数据集有比较好的伸缩性
缺点:
- 需要指定聚类 数量K
- 对异常值敏感
- 对初始值敏感
代码实现:
首先我们随机生成200个点,就取(0,2000)之间的,并确定质心个数,这里就取个3个质心,也是随机生成(可以根据需求改变)如下:
import random
import matplotlib.pyplot as plt
random_x = [random.randint(0,2000) for _ in range(200)]
random_y = [random.randint(0,2000) for _ in rang 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4132
4132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









