






本文提到的忽略类别和检测中的忽略类别不一样,前者是在训练中加入忽略类,后者是在检测中仅检测想要的类。
ignore class的定义
我们在标注数据集的时候都是标注的正样本,训练过程中也是这样训练,让网络对正样本计算loss。但我们也遇到过这样的目标,这个目标即不属于正样本,也不属于负样本,比如正样本是person,那么人形雕塑或者人的影子,这类物体他并不是正样本,但如果直接归为负样本也是不严谨的,因此就可以将这类物体标注为“忽略类”,这类物体在标注的时候是有标签和box信息的,比如给这类物体的标签是"-2"。又或者说在训练中,希望对某些像素大小目标设置为ignore,比如训练中忽略20x20的目标
ignore训练
ignore训练并不是说把该类目标丢弃,如果你是把该类目标从label中删除,那么不就相当于把这个目标作为负样本进行训练了嘛,这是不对的。
但如果将ignore作为一个正常的类进行训练,参与loss,那么相当于将该类作为正样本进行训练了。因此这样也是不对的。我们需要时刻记得ignore class既不是正样本,也不是负样本,是一种夹在两者之间的样本。
那么问题就是如何正确对待ignore class。
对于ignore class的训练,其实是希望不对其进行反向传播,仅前向传播即可。这是因为不进行反向传播就不用当正样本进行学习,而且也不会因为直接丢弃而变成负样本。
想法很简单,但做起来还是有难度的。首先第一个问题就是如果做ignore class的样本匹配。我最初的想法是在做样本匹配的时候将忽略类样本与正样本分开,比如下面的代码,通过对class_id进行类别的筛选。【在yolov5的utils/loss.py中的build_targets函数中修改】
这里的t和t_ign shape含义是一样的,【image_id,class_id,x,y,w,h,anchor_id】
t = targets * gain # 将Box缩放到对应的特征层上
t_ign = t[t[..., 1] < 0].view(t.shape[0], -1, t.shape[2]) # 忽略类
t = t[t[..., 1] >= 0].view(t.shape[0], -1, t.shape[2]) # 正样本
image_id = torch.as_tensor(t_ign[..., 0]) # [3, num_classes] 记录每个anchor对应的image id然后按原yolov5的方法对这两个部分分别进行anchor的宽高匹配,然后仅把正样本的结果送入后面的三个loss计算。但这是有问题的,因为在yolov5中anchor是通过宽高匹配,虽然可以分别对两个部分进行匹配,但如何判断忽略类的匹配到的anchor也会被正样本匹配到呢?因为后面需要进行一个去重工作,就是将忽略类与正样本匹配到的相同anchor去除掉。
第二个问题就是,针对ignore class的训练,loss部分怎么处理?我最初想这个问题的时候,就仅仅是觉得不需要对三个loss进行处理,这显然不对,如果不对loss进行处理,那前面只做样本匹配其实是没有意义的。
ignore class样本匹配
针对第一个问题:
为了可以获得更多的anchor框与ignore class的匹配,以减小对于正样本的影响,我们需要做的是在当前特征图上生成网格,并将特征图所有网格中的anchor box与ignore class进行匹配,你可以用iou,但我这里用的是ioa匹配。
在特征层上生成网格并生成anchor box代码如下:
# 生成网格,anchor中心
grid_y, grid_x = torch.meshgrid([torch.arange(p[i].shape[3],device=targets.device), torch.arange(p[i].shape[2], device=targets.device)])
grid = torch.stack((grid_x, grid_y), 2).view((1, 1, p[i].shape[3], p[i].shape[2], 2)).float()
# plot_anchor(grid_x, grid_y, gain)
# 在网格上生成anchor
anchors_boxes = torch.zeros(3, p[i].shape[3], p[i].shape[2], 4) # [3,80,80,4]
anchors_boxes[..., :2] = grid[..., :2] # 给所有anchor分配中心点
anchors_boxes[0, :, :, 2:] = anchors[0, :]
anchors_boxes[1, :, :, 2:] = anchors[1, :]
anchors_boxes[2, :, :, 2:] = anchors[2, :] # 将所有anchor的w,h传入
# 此刻的anchors_boxes为所有batch下三种anchor对应的x,y,w,h shape[batch_size,3,feat_w,feat_h,4]
# xywh->x1y1x2y2
an_box = torch.zeros_like(anchors_boxes) # [3,80,80,4]
an_box[..., :2] = anchors_boxes[..., :2] - anchors_boxes[..., 2:] / 2
an_box[..., 2:] = anchors_boxes[..., :2] + anchors_boxes[..., 2:] / 2获得t_ign的所有box,用于后面的anchor匹配,获得box代码:
# 获得t_ign的box框
center_xy = t_ign[..., 2:4] # 取gt box的中心点
gt_wh = t_ign[..., 4:6] # 取gt的w和h
t_ign_box = torch.zeros(3, t_ign.shape[1], 4) # 用于存储框shape[3,num_obj,4]
t_ign_box[..., :2] = center_xy - gt_wh / 2 # 左上角
t_ign_box[..., 2:] = center_xy + gt_wh / 2 # 右下角然后是遍历当前head中所有cell中的anchor box与忽略类的box进行ioa匹配。image_id是之前定义的用于记录anchor对应的目标image id[或者说是batch id]。因为在前面我们已经给t_ign中的每个目标均分配了三种anchor,而且给每个目标记录了所在的image id【t_ign[...,0]就是image id,最后一个维度是anchor id了】。anchor_id用于记录匹配到的anchor id【每个head上设置了三种anchor】,ign_gi和ign_gj是记录满足ioa阈值的anchor的中心点坐标。
anchor_id = []
ign_gi = []
ign_gj = []
image_id_list = []
#plot_ign_cls_box(t_ign_box, gain)
for an_idx in range(an_box.shape[0]): # 遍历3种anchor
for i in range(an_box.shape[1]): # 遍历每个网格获得每个anchor的box 行遍历
for j in range(an_box.shape[2]): # 列遍历
# 将所有目标box与grid中的所有anchor计算ioa,输入shape[num_obj],得到每个目标ioa
ioa = compute_ioa(box1=t_ign_box[an_idx], box2=an_box[an_idx, i, j])
mask = ioa > ioa_thre
if mask.shape[0] and torch.max(mask): # 所有batch中表示匹配到
image_id_list.append(image_id[an_idx][mask])
anchor_id.append(an_idx)
ign_gi.append(j) # x坐标
ign_gj.append(i) # y坐标最后将上面几个列表存储在ign_match_anchor列表中。shape为【batch,anchor,x,y】。
ign_match_anchor.append((
torch.IntTensor([val[0] for val in image_id_list]),
torch.IntTensor(anchor_id),
torch.IntTensor(ign_gj),
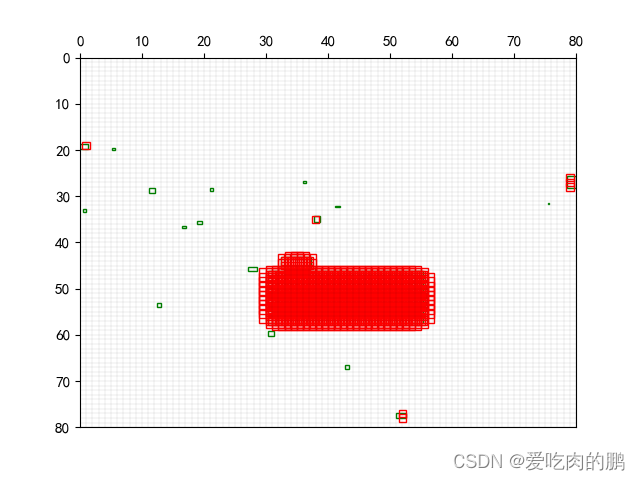
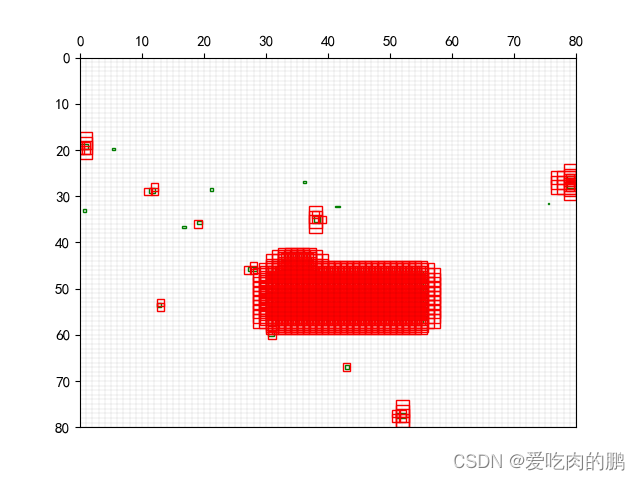
torch.IntTensor(ign_gi)))通过设置的ioa阈值的不同,匹配到的anchor数量也不同。下图分别是阈值为0.5和0.2时在80x80特征图上匹配示意图,绿色框为ignore class的gt,红色框为anchor box。阈值为>0.2的有更多的ign_class被anchor匹配到。
loss设计
代码中的indices记录了正样本的[image_id,anchor_id,x,y],ign_anchors则记录了与忽略类匹配到的【image_id,anchor_id,anchor_x,anchor_y】.
if self.ignore_class:
tcls, tbox, indices, anchors, ign_anchors = self.build_targets(p, targets) # targets
for i, pi in enumerate(p): # layer index, layer predictions pi shape [batch_size,3,feat_w,feat_h,5+classes]
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
if self.ignore_class:
b_ign, a_ign, gj_ign, gi_ign = ign_anchors[i]
b_ign = b_ign.type_as(b)
a_ign = a_ign.type_as(a)
gj_ign = gj_ign.type_as(gj)
gi_ign = gi_ign.type_as(gi)
n_ign = b_ign.shape[0]
tobj_ign = torch.zeros_like(pi[..., 0], device=device)
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj在yolo中的三个损失函数中,box_loss,cls_loss其实对于忽略类可以不用,而obj_loss怎么算呢?因为通过前面的操作其实可以知道和忽略类匹配到的anchor框,然后我们需要在正样本以及预测pred中去重,也就是看正样本obj和pred哪些地方和忽略类anchor是重叠的,去除点,然后将这个像素点作为负样本【也就是将重复的坐标置0即可,这样该点就不反向传播了】。
if self.ignore_class:
tobj_ign[b_ign, a_ign, gj_ign, gi_ign] = 1
# 去重
mask = (tobj != 0) & (tobj_ign != 0) # 相同位置不为0的地方
tobj[mask] = 0 # 正样本与ign相同位置不为0的地方置0【正样本去重成功】
pi[..., 4][mask] = 0 # 预测中正样本与ign相同位置不为0的地方置0【预测类正样本去重成功】
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss 通过以上的样本匹配和loss设计就完成了忽略训练的设计。


















 3857
3857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











