



 文章介绍了清华大学KEG实验室开发的CodeGeeX,这是一个130亿参数的代码生成模型,可免费替代GitHub的Copilot。CodeGeeX基于transformers架构,训练数据包括开源代码,提供VSCode和JetbrainsIDEs的插件,并在HumanEval-X基准上表现出色。
文章介绍了清华大学KEG实验室开发的CodeGeeX,这是一个130亿参数的代码生成模型,可免费替代GitHub的Copilot。CodeGeeX基于transformers架构,训练数据包括开源代码,提供VSCode和JetbrainsIDEs的插件,并在HumanEval-X基准上表现出色。
从Copilot说起
很多人都听说过使用过Copilot。Copilot是GitHub于2021年推出的一款AI编程工具。它可以为用户在各种开发环境中写代码时自动提供建议,支持Python、JavaScript、Java和Go等编程语言。它可以根据上下文自动写代码,包括文档字符串、注释、函数名称、代码,只要用户给出提示,就可以写出完整的函数。这项产品从2022年6月起正式向用户收费,每个月需要支付10美元。虽然受到许多质疑,但也收获了很多好评,因为它实在是太智能了。
Copilot背后,是OpenAI的大模型Codex。它使用了大量的高质量开源代码作为训练数据,基于GPT-3的框架进行训练。
今天要介绍的这个工作,则是来自于清华的KEG实验室。他们不仅利用公开的代码数据训练了一个130亿参数的代码生成模型(名为CodeGeeX),还将所有代码全部开源。并且,也像Copilot一样开发了VS Code和Jetbrains IDEs的插件,任何人都可以免费使用。如果不想为Copilot支付每月10刀的费用,不如来试试这款国产的“平替”。
CodeGeeX模型
CodeGeeX是一个基于transformers的大规模预训练编程语言模型。它是一个从左到右生成的自回归解码器,将代码或自然语言标识符(token)作为输入,预测下一个标识符的概率分布。CodeGeeX含有40个transformer层,每层自注意力块的隐藏层维数为5120,前馈层维数为20480,总参数量为130亿。模型支持的最大序列长度为2048。
CodeGeeX的训练语料由两部分组成。第一部分是开源代码数据集,The Pile与CodeParrot。The Pile包含GitHub上拥有超过100颗星的一部分开源仓库,在训练时使用了其中23种语言的代码。第二部分是补充数据,直接从GitHub开源仓库中爬取Python、Java、C++代码,并按一定条件进行一筛选。
CodeGeeX模型的训练基于华为Mindspore 1.7框架。在训练过程中使用了1536个昇腾910 AI处理器(32GB),历经两个月的时间。除了Layer-norm与Softmax使用FP32格式以获得更高的精度与稳定性,模型参数整体使用FP16格式,最终整个模型需要占用约27GB显存。为了增加训练效率,使用8路模型并行和192路数据并行的训练策略,微批大小为16、全局批大小为3072,并采用ZeRO-2优化器降低显存占用。
模型评价
为了更好地评测代码生成模型的多语言生成能力,清华实验室的团队还构建了一个新的评价基准HumanEval-X。此前的多语言代码生成能力评价大多是基于代码的语义相似度来衡量的。这种衡量方式对于自然语言生成问题不大,但是对于代码生成就显得不够科学了。而新提出的评价基准HumanEval-X则可用于衡量生成代码的功能正确性。覆盖Python、C++、Java、JavaScript、Go五种语言,可用于多种任务。
将CodeGeeX与另外两个开源代码生成模型进行比较,分别为Meta的InCoder与Salesforce的CodeGen,选取InCoder-6.7B、CodeGen-Multi-6B 与 CodeGen-Multi-16B。CodeGeeX能获得最佳的平均性能,显著超越了参数量更小的模型(7.5%~16.3%的提升),与参数量更大的模型CodeGen-Multi-16B表现相当(平均性能 54.76% vs. 54.39%)。
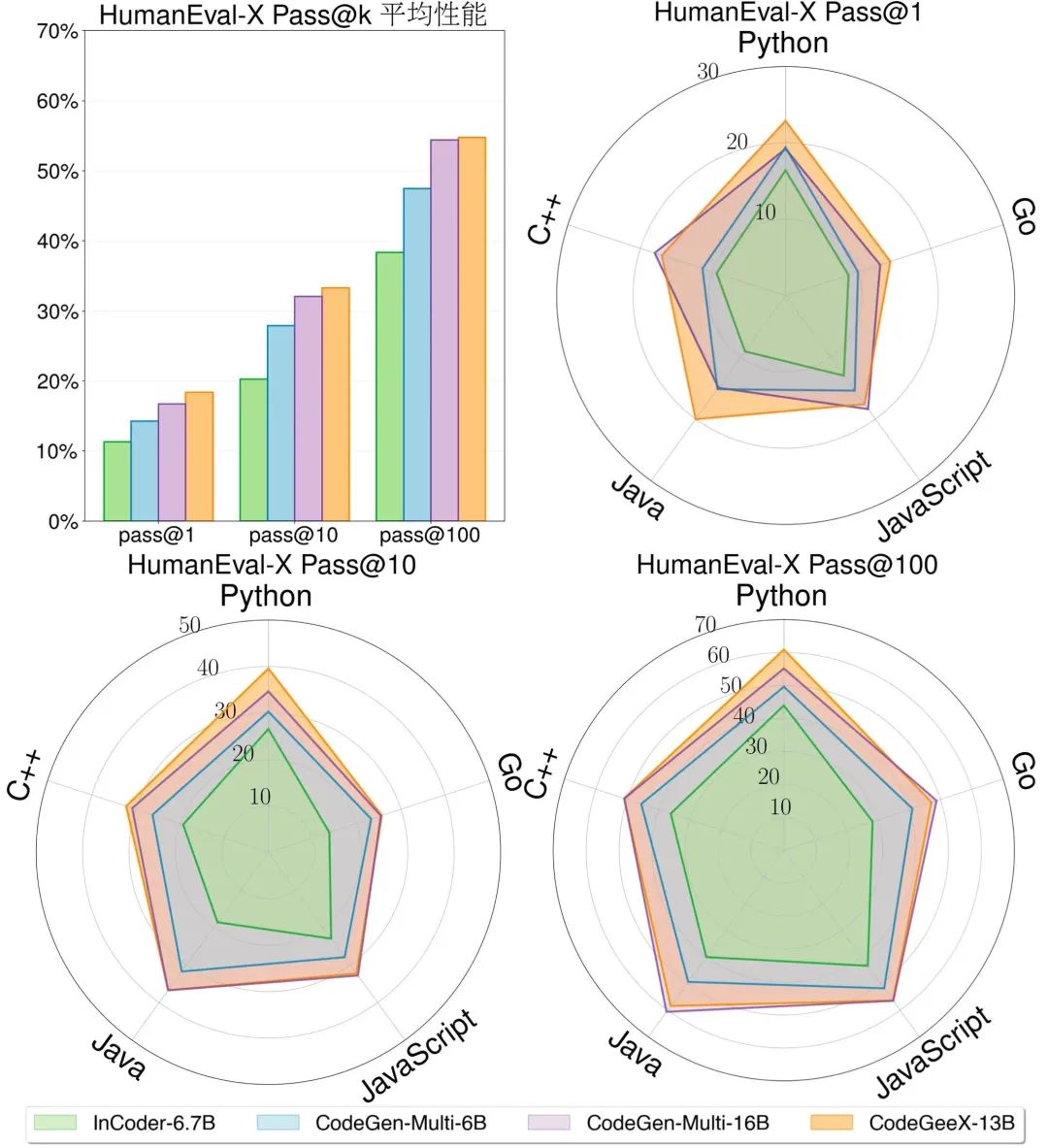
(左上:在HumanEval-X的代码生成任务中,模型在所有语言上的平均表现。其他:在五种语言上具体的pass@k(k=1,10,100)性能。CodeGeeX的平均表现优于InCoder-6.7B和CodeGen-Multi-6B/16B。)
CodeGeeX插件
清华实验室不仅发布了CodeGeeX模型,还顺带提供了用于VS Code和Jetbrains IDEs(IntelliJ IDEA、PyCharm等)的辅助编程插件,都可以在相应的插件市场里搜索“codegeex”下载并免费使用。
在CodeGeeX的VS Code插件中,提供了四种使用模式:
1、自动模式
在编写代码的过程中,插件可以根据前文的代码或注释自动给出补全提示,按tab键后补全提示就会自动上屏。
2、交互模式
通过“Ctrl+Enter”激活交互模式,CodeGeeX将根据当前已有的代码,为后续生成多段代码候选,并显示在右侧窗口中。点击候选代码上方的“use code”即可插入结果到为当前光标位置。
3、翻译模式
可以在IDE中粘贴一段其他语言代码,选中并按“Ctrl+Alt+T”激活翻译模式。选择当前选中代码的语言,CodeGeeX将会把代码翻译成IDE当前编写的语言,点击翻译结果上方的“use code”即可将翻译结果插入文件。
4、提示模式
提示模式的原理是利用CodeGeeX强大的少样本生成能力,可以在输入中添加额外的提示来实现一些有趣的功能,包括且并不限于代码解释、概括、以特定风格生成等。这部分算是深度利用了大模型的能力,感兴趣的朋友可以自己研究一下,就不在这里过多展开了。
Jetbrains IDE插件目前只有前两种模式,也覆盖了日常使用的大部分场景了。


















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











