




这里直接利用上一篇文章实现的Transformer架构来完成一个英语翻译法语的任务
导入模块:
# 导入open方法
from io import open
# 用于字符规范化
import unicodedata
# 导入正则表达式的包
import re
# 导入随机处理数据的包
import random
# 导入torch相关的包
import torch
import torch.nn as nn
import torch.optim as optim
#这里会用到上篇文章代码中的函数
from transformer import make_model, create_padding_mask, subsequent_mask1. 数据预处理模块(Data Preparation)
目的: 将原始文本语言对处理为适合模型训练的数据格式。
功能点:
-
Unicode → ASCII 规范化(
unicodeToAscii、normalizeString) -
文本清洗与过滤(
filterPairs,MAX_LENGTH限制) -
单词字典构建(
Lang类) -
转换为索引序列(
tensorFromSentence,tensorsFromPair)
结果: 构建出 input_lang, output_lang 两个语言字典,和清洗后的 pairs 语言对数据。
部分样本:

预处理代码:
# 设备的选择, 可以选择在GPU上运行或者在CPU上运行
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义起始标志
SOS_token = 0
# 定义结束标志
EOS_token = 1
PAD_token = 2
# 明确一下数据文件的存放地址
data_path = 'data/eng-fra.txt'
class Lang():
def __init__(self, name):
# name: 参数代表传入某种语言的名字
self.name = name
# 初始化单词到索引的映射字典
self.word2index = {}
# 初始化索引到单词的映射字典, 其中0, 1对应的SOS, EOS已经在字典中了
self.index2word = {0: "SOS", 1: "EOS", 2: "PAD"}
# 初始化词汇对应的数字索引, 从2开始, 因为0, 1已经被开始字符和结束字符占用了
self.n_words = 3
def addSentence(self, sentence):
# 添加句子的函数, 将整个句子中所有的单词依次添加到字典中
# 因为英文, 法文都是空格进行分割的语言, 直接进行分词就可以
for word in sentence.split(' '):
self.addWord(word)
def addWord(self, word):
# 添加单词到类内字典中, 将单词转换为数字
# 首先判断word是否已经在self.word2index字典的key中
if word not in self.word2index:
# 添加的时候, 索引值取当前类中单词的总数量
self.word2index[word] = self.n_words
# 再添加翻转的字典
self.index2word[self.n_words] = word
# 第三步更新类内的单词总数量
self.n_words += 1
# 将unicode字符串转换为ASCII字符串, 主要用于将法文的重音符号去除掉
def unicodeToAscii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
# 定义字符串规范化函数
def normalizeString(s):
# 第一步使字符转变为小写并去除掉两侧的空白符, 再调用上面的函数转换为ASCII字符串
s = unicodeToAscii(s.lower().strip())
# 在.!?前面加一个空格
s = re.sub(r"([.!?])", r" \1", s)
# 使用正则表达式将字符串中不是大小写字符和正常标点符号的全部替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s
# 读取原始数据并实例化源语言+目标语言的类对象
def readLangs(lang1, lang2):
# lang1: 代表源语言的名字
# lang2: 代表目标语言的名字
# 整个函数返回对应的两个类对象, 以及语言对的列表
lines = open(data_path, encoding='utf-8').read().strip().split('\n')
# 对lines列表中的句子进行标准化处理, 并以\t进行再次划分, 形成子列表
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# 直接初始化两个类对象
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs
# 设置组成句子中单词或标点的最多个数
MAX_LENGTH = 10
# 选择带有指定前缀的英文源语言的语句数据作为训练数据
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
# 过滤语言对的具体逻辑函数
def filterPair(pair):
# 当前传入的pair是一个语言对的形式
# pair[0]代表英文源语句, 长度应小于MAX_LENGTH, 并且以指定前缀开始
# pair[1]代表法文源语句, 长度应小于MAX_LENGTH
return len(pair[0].split(' ')) < MAX_LENGTH and \
pair[0].startswith(eng_prefixes) and \
len(pair[1].split(' ')) < MAX_LENGTH
# 过滤语言对的函数
def filterPairs(pairs):
# 函数直接遍历列表中的每个语言字符串并调用filterPair()函数即可
return [pair for pair in pairs if filterPair(pair)]
# 整合数据预处理的函数
def prepareData(lang1, lang2):
# lang1: 代表源语言的名字, 英文
# lang2: 代表目标语言的名字, 法文
# 第一步通过调用readLangs()函数得到两个类对象, 并得到字符串类型的语言对的列表
input_lang, output_lang, pairs = readLangs(lang1, lang2)
# 第二步对字符串类型的列表进行过滤操作
pairs = filterPairs(pairs)
# 对过滤后的语言对列表进行遍历操作, 添加进类对象中
for pair in pairs:
input_lang.addSentence(pair[0])
output_lang.addSentence(pair[1])
# 返回数值映射后的类对象, 以及过滤后的语言对列表
return input_lang, output_lang, pairs
input_lang, output_lang, pairs = prepareData('eng', 'fra')
print(input_lang.n_words,output_lang.n_words)
print(len(pairs))
print(pairs[:5])
def tensorFromSentence(lang, sentence):
# lang: 代表是Lang类的实例化对象
# sentence: 代表传入的语句
indexes = [lang.word2index[word] for word in sentence.split(' ')]
return torch.tensor(indexes, dtype=torch.long, device=device).unsqueeze(0)
def tensorsFromPair(pair):
# pair: 一个语言对 (英文, 法文)
#每个句子结尾都要加入EOS_token,但是在编码器端,不需要SOS_token,也就是input是指编码器端输入
intput_indexes = [input_lang.word2index[word] for word in pair[0].split(' ')]+[EOS_token]
#这里的output是指解码器的输入,以output命名是指翻译的输出。
#解码器端句子需要SOS_token以及EOS_token, 所以在这里需要额外添加
output_indexes = [SOS_token]+[output_lang.word2index[word] for word in pair[1].split(' ')]+[EOS_token]
# 转为tensor,并变为2维的
input_tensor = torch.tensor(intput_indexes, dtype=torch.long, device=device).unsqueeze(0)
output_tensor = torch.tensor(output_indexes, dtype=torch.long, device=device).unsqueeze(0)
return (input_tensor, output_tensor)

可以观察到以我们指定开头的样本有10599条,英语词库大小为2804,法语词库大小为4346
为了方便测试模型可用性,因为我们这里只把开头为:
"i am ", "i m ",
"he is", "he s ",
"she is", "she s ",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
等数据用来训练,你就理解为我们样本只有这些符合条件的样本,而不是整个样本文件,词库也只有这些开头的句子拿来训练,你也可以适当修改代码,把所有样本都拿来训练,并且我指定了源句子和目标句子的最大长度,当然这个长度只是指我们选取的样本的长度,因为最后我们会对句子中加入SOS,PAD,EOS等标识符,长度会变化。
2. 数据加载模块(BatchLoader)
目的: 动态生成 batch,适配 Transformer 的输入格式。
特点:
-
每一批次根据 batch 内最长句子长度进行填充
-
填充发生在
EOS之前(以便更合理的模型收敛)
代码:
class BatchLoader:
def __init__(self, pairs, batch_size):
self.pairs = pairs #传入所有的样本对
self.batch_size = batch_size
self.pad_token = PAD_token #我们会根据每一个批次的最大长度来填充句子,所以需要知道pad_token的索引值
self.index = 0
def __len__(self):
return (len(self.pairs) + self.batch_size - 1) // self.batch_size
def pad_sequence_before_eos(self, seq, max_len):
assert EOS_token in seq, "序列中必须包含EOS_token"
eos_pos = seq.index(EOS_token)
seq_len = len(seq)
pad_len = max_len - seq_len
assert pad_len >= 0, f"目标长度小于序列长度,pad_len={pad_len}"
assert eos_pos == seq_len - 1, "EOS_token必须是序列最后一个token"
return seq[:eos_pos] + [self.pad_token] * pad_len + [EOS_token] #填充的时候注意是在EOS之前填充,不要填充在EOS之后了
def __iter__(self):
self.index = 0
return self
def __next__(self):
if self.index >= len(self.pairs):
raise StopIteration
batch_pairs = self.pairs[self.index:self.index + self.batch_size]
self.index += self.batch_size
input_seqs = []
output_seqs = []
for pair in batch_pairs:
input_idx = [input_lang.word2index[word] for word in pair[0].split(' ')] + [EOS_token]
output_idx = [SOS_token] + [output_lang.word2index[word] for word in pair[1].split(' ')] + [EOS_token]
input_seqs.append(input_idx)
output_seqs.append(output_idx)
max_input_len = max(len(seq) for seq in input_seqs)
max_output_len = max(len(seq) for seq in output_seqs)
input_padded = [self.pad_sequence_before_eos(seq, max_input_len) for seq in input_seqs]
output_padded = [self.pad_sequence_before_eos(seq, max_output_len) for seq in output_seqs]
input_tensor = torch.tensor(input_padded, dtype=torch.long, device=device)
output_tensor = torch.tensor(output_padded, dtype=torch.long, device=device)
return input_tensor, output_tensor3. 训练模块(train_model)
训练过程要点:
-
输入
src和目标tgt被分成tgt_input和tgt_y -
使用
CrossEntropyLoss(ignore_index=PAD)计算多时间步预测损失 -
模型输出
(batch, tgt_len, vocab_size),flatten 后与目标tgt_y对齐
代码:
def train_model(model, loader, num_epochs, lr=1e-4, print_every=100):
model.train()
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.NLLLoss(ignore_index=PAD_token)
step = 0
for epoch in range(1, num_epochs + 1):
total_loss = 0
for batch_idx, (src, tgt) in enumerate(loader):
# 构造输入
src_mask = create_padding_mask(src, PAD_token).to(src.device) # (batch, 1, 1, src_len)
tgt_input = tgt[:, :-1] # 去掉最后一个 EOS
tgt_y = tgt[:, 1:] # 去掉第一个 SOS,作为目标
tgt_mask = create_padding_mask(tgt_input, PAD_token).to(tgt.device) & subsequent_mask(tgt_input.size(1)).to(tgt.device)
# 前向传播
preds = model(src, tgt_input, src_mask, tgt_mask)
# 预测输出维度: (batch, tgt_len, vocab_size) → reshape 成 (batch*tgt_len, vocab_size)
preds_flat = preds.reshape(-1, preds.size(-1))
tgt_y_flat = tgt_y.reshape(-1)
loss = criterion(preds_flat, tgt_y_flat)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
step += 1
if step % print_every == 0:
avg_loss = total_loss / print_every
print(f"Epoch {epoch} | Step {step} | Loss: {avg_loss:.4f}")
total_loss = 0
torch.save(model.state_dict(), 'model.pth')4.推理模块(translate_sentence)
推理采用贪婪解码(greedy decode)策略:
-
输入英文句子后,逐字生成目标法语
-
使用
tgt_input = [SOS_token, ...]递增生成 -
模型每步输出 vocab 上的分布,选择最大值作为下一 token
代码:
def prepare_sentence(sentence, lang):
# 按训练时的流程做分词和索引映射,添加EOS
indexes = [lang.word2index[word] for word in sentence.split(' ')]
indexes.append(EOS_token)
return torch.tensor(indexes, dtype=torch.long, device=device).unsqueeze(0) # (1, seq_len)
def translate_sentence(model, sentence, input_lang, output_lang, max_len=20):
model.eval()
src = prepare_sentence(sentence, input_lang)
src_mask = create_padding_mask(src, PAD_token)
# 解码器输入,起始是SOS_token
tgt_indices = [SOS_token]
for i in range(max_len):
tgt_input = torch.tensor(tgt_indices, dtype=torch.long, device=device).unsqueeze(0) # (1, len)
tgt_mask = create_padding_mask(tgt_input, PAD_token) & subsequent_mask(tgt_input.size(1)).to(device)
out = model(src, tgt_input, src_mask, tgt_mask) # (1, seq_len, vocab_size)
prob = out[:, -1, :] # 取最后一步的预测 (1, vocab_size)
next_word = torch.argmax(prob, dim=-1).item() # 贪心选择概率最高的词
tgt_indices.append(next_word)
if next_word == EOS_token:
break
# 将索引转回单词
output_words = [output_lang.index2word[idx] for idx in tgt_indices[1:]] # 去掉起始符SOS
#去掉EOS
output_words = output_words[:-1]
return ' '.join(output_words)5.训练和推理
if __name__ == '__main__':
#构建模型
model = make_model(
source_vocab=input_lang.n_words,
target_vocab=output_lang.n_words,
N=6,
d_model=512,
d_ff=2048,
head=8,
dropout_rate=0.1
).to(device)
# 构建 loader
loader = BatchLoader(pairs, batch_size=64)
# 开始训练
train_model(model, loader, num_epochs=15, lr=1e-4, print_every=50)
model = make_model(source_vocab=input_lang.n_words, target_vocab=output_lang.n_words)
model.load_state_dict(torch.load('model.pth', map_location=device))
model.to(device)
model.eval() # 切换到评估模式
for i in range(5):
# 随机选择一个英文句子 这里我直接使用样本的来测试了,其实这样的行为不好,只是简单测试一下
pair = random.choice(pairs)
eng_sentence = pair[0]
rel_sentence = pair[1]
# 翻译成法文
fra_sentence = translate_sentence(model, eng_sentence, input_lang, output_lang)
print(f"英文:{eng_sentence},实际翻译:{rel_sentence},预测翻译:{fra_sentence}")
print("--------------------------------")
可以看到,模型基本上是训练成功了的,虽然是在训练集上,但是没有出现其它翻译结果等。
6.以一个批次为例,带你看懂数据流通
from transformer import *
#得到一个数据加载器实例
loader = BatchLoader(pairs, batch_size=64)
#得到一个批次的语言对
src, tgt = next(iter(loader))
#d_model是指经过编码器的输出维度
d_model = 512
#两个语言的词库
src_vocab = input_lang.n_words
tgt_vocab = output_lang.n_words
print("src_vocab:", src_vocab)
print("tgt_vocab:", tgt_vocab)
# 词嵌入 + 位置编码层实例
src_embed = nn.Sequential(Embeddings(src_vocab, d_model), PositionalEncoding(d_model)).to(device)
tgt_embed = nn.Sequential(Embeddings(tgt_vocab, d_model), PositionalEncoding(d_model)).to(device)
# 多头注意力 & 前馈层实例
self_attn = MultiHeadAttention(head_num=8, d_model=d_model).to(device)
src_attn = MultiHeadAttention(head_num=8, d_model=d_model).to(device)
ff = PositionwiseFeedForward(d_model, 2048).to(device)
# 编码/解码层实例
enc_layer = EncoderLayer(d_model, copy.deepcopy(self_attn), copy.deepcopy(ff)).to(device)
dec_layer = DecoderLayer(d_model, copy.deepcopy(self_attn), copy.deepcopy(src_attn), copy.deepcopy(ff), dropout_rate=0.1).to(device)
# 输出层
generator = Generator(d_model, tgt_vocab).to(device)
#编码器我们需要一个mask来屏蔽掉padding的部分
src_mask = create_padding_mask(src, pad_token_id=PAD_token) # shape: (batch, 1, 1, src_len)
#把源语言的句子输入词嵌入+位置编码层,得到输出
src_emb = src_embed(src) # (batch, src_len, d_model)
print("src_emb.shape:", src_emb.shape)
#传入三层编码器
enc_output1 = enc_layer(src_emb, src_mask)
enc_output2 = enc_layer(enc_output1, src_mask)
enc_output3 = enc_layer(enc_output2, src_mask)
enc_output = enc_output3
print("enc_output.shape:", enc_output.shape)
#这里是解码器的输入
tgt_input = tgt[:, :-1] # 去除最后 EOS,作为 decoder 输入
tgt_y = tgt[:, 1:] # 去除第一个 SOS,作为目标,也就是真实值
#解码器端既需要mask掉padding的部分,也需要屏蔽掉未来的部分
tgt_mask = create_padding_mask(tgt_input, PAD_token) & subsequent_mask(tgt_input.size(1)).to(device)
#把目标语言的句子输入词嵌入+位置编码层,得到输出
tgt_emb = tgt_embed(tgt_input) # (batch, tgt_len-1, d_model)
print("tgt_emb.shape:", tgt_emb.shape)
#把上一层的输出作为解码器的输入,传入三层解码器,得到输出
dec_output1 = dec_layer(tgt_emb, enc_output, src_mask, tgt_mask)
dec_output2 = dec_layer(dec_output1, enc_output, src_mask, tgt_mask)
dec_output3 = dec_layer(dec_output2, enc_output, src_mask, tgt_mask)
dec_output = dec_layer(dec_output3, enc_output, src_mask, tgt_mask)
print("dec_output.shape:", dec_output.shape)
#把输出经过输出层,得到预测值
logits = generator(dec_output) # (batch, tgt_len-1, tgt_vocab)
print("logits.shape:", logits.shape)
#并取最大值作为下一个词的预测
predicted = logits.argmax(-1)
print("predicted.shape:",predicted.shape)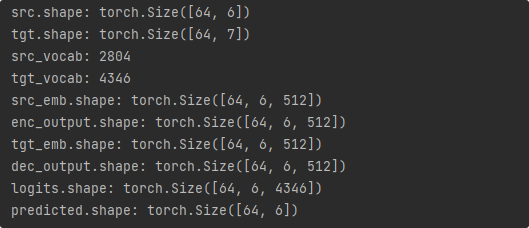
这里shape的第二个参数,只是这一个批次的最长句子长度,如果取另外一个批次的数据,这个6可能还变为7、8、9等。
1.我们拿到一个批次的源语言样本的形状是[64,6],代表有64个样本,这批样本中最长句子长度为6,其中低于6的会用PAD填充。目的语言样本形状是[64,7],代表有7个字,其中低于7的会用PAD填充。总之,一批样本中,源语言长度必须一致、目的语言长度必须一致。
2.将一个批次的数据经过词嵌入和位置编码层后形状变为[64,6,512],代表64个样本,有6个字,每个字被映射为512维的向量
3.把经过词嵌入和位置编码层后的数据传入编码器后,形状不变,但是每个向量经过注意力计算,会变得更加有上下文信息。这里需要传入mask,因为编码器端需要使用mask来屏蔽到PAD词,PAD是对句子不能有影响的。
4.先把一个批次的目的语言样本,复制两份,一份不需要句尾标识符,作为解码器的输入,一份不需要开始标识符作为真实值。传入词嵌入层和位置编码层后从形状[64,7]变为[64,7,512],也就是64个句子,每个句子有7个字,每个字映射为512维样本。
5.经过了词嵌入层和位置编码层后传入解码器,还要把编码器的输出传入解码器,这就是跨注意力层,既然要用到编码器的输出,当然也需要mask掉PAD,对于解码器端的也需要mask掉下文部分和PAD部分。
6.最后把解码器的输出传入输出层,其实就是经过全连接层,把输出形状[64,6,512]变为[64,6,4346] 这里4346就是目的词库的大小,因为对于每个词,都有预测概率值,64个句子,最后会输出6个字,每个字有4346种可能性。
7.取出最后一维的最大值作为预测值,你可以理解为最后每个样本有6个空,需要使用其中概率最大的值来填充,形状是[64,6],也就是64个句子,6个空,这个空对应了一个字的索引,就是我们最终的输出。
整个项目的github地址:https://github.com/yz1qaq/Transformer/tree/main/translator/EngToFra

















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









