










 本文详细介绍使用TensorFlow实现多层卷积神经网络在MNIST数据集上的应用,包括网络结构设计、参数调试及结果提交流程。
本文详细介绍使用TensorFlow实现多层卷积神经网络在MNIST数据集上的应用,包括网络结构设计、参数调试及结果提交流程。
在kaggle上的Digit Recognizer[MNIST]比赛中用Tensorflow实现多层卷积神经网络算法
前言
在kaggle竞赛中,有不少给大家练习的入门级别的比赛,分别是:
- Titanic: Machine Learning from Disaster
- House Prices: Advanced Regression Techniques
- Digit Recognizer
其中,Titanic是适合机器学习以及神经网络入门的比赛;House Prices是适合练习特征提取的比赛,因为其特征种类繁多;Digit Recognizer使用的是MNIST数据集,是一个在科研界都被广泛使用的数据集,其由Yann LeCun, Courant Institute, NYU、Corinna Cortes, Google Labs, New York和Christopher J.C. Burges, Microsoft Research, Redmond共同维护,该数据集比较适合用来练习卷积神经网络以及其它各种神经网络,官网网址为:MNIST官网,上面有不同文章不同算法得到的对于MNIST的最优的结果。kaggle上该比赛的超链接为:Digit Recognizer
若想看在MNIST数据集上用Tensorflow实现多层卷积神经网络算法,请点击右侧超链接:请点我。
若想看更为基础的在kaggle上的Digit Recognizer(MNIST)比赛中用Tensorflow实现多层神经网络算法,请点击右侧超链接:请点我。
若想看更为基础的在MNIST数据集上用Tensorflow实现多层神经网络算法,请点击右侧超链接:请点我。
该代码是3层卷积加2层全连接层的神经网络,且隐藏层都加入了dropout,若想了解dropout,请点击dropout解说博客
由于kaggle未使用所有的原始的MNIST测试集来测试准确率,因此需要自行提交预测结果进入kaggle的服务器以获得最终的准确率,在kaggle上,每天能提交5次,本博客主要分为两部分:
- 用于调试参数的代码;
- 用于提交结果的代码。
需要下载的东西(数据和代码)
训练集、测试集以及相关代码都在如下的百度云盘中:
链接:https://pan.baidu.com/s/1WNiRDdFWXju0rdCiv4YJ7w
提取码:cb9f
用于调试参数的代码讲解
首先需要先导入一些库
# 数据分析库
import pandas as pd
# 科学计算库
import numpy as np
# 导入tensorflow
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.python.framework import ops
然后导入数据集(在上方的百度网盘中可以下载)
data_train = pd.read_csv("train.csv")
data_test = pd.read_csv("test.csv")
通常来说,若是第一次遇见这些数据集,应该先简略的看看其中的数据的详情
data_train.head()
运行上述代码后,会出现
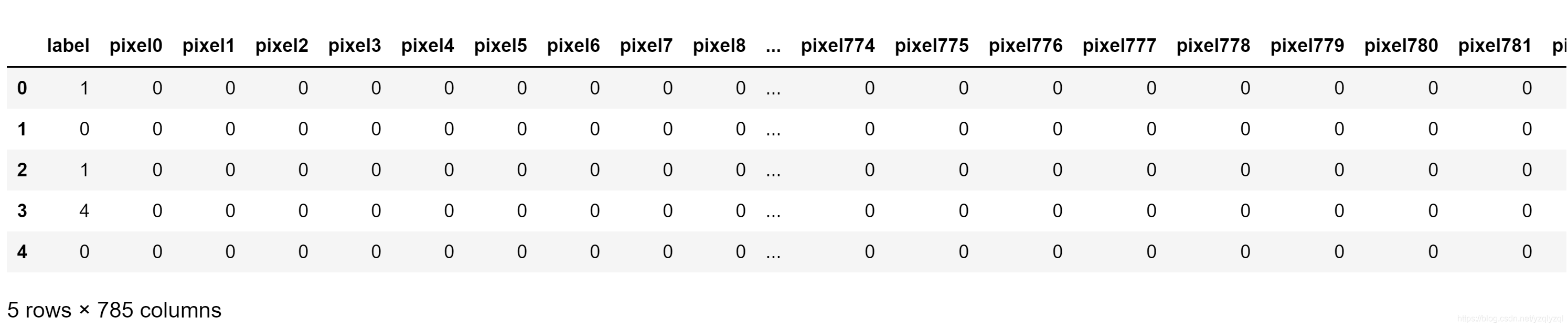
该代码的意思是查看data_train的前五行数据,可以发现,第一列是label,即该行是什么数字,后面pixel0到pixel783为[0,255]的像素值,每一张数字图片都是
28
×
28
28\times28
28×28的尺寸,此处是将其拉长一行向量,因此有
28
×
28
=
784
28\times28=784
28×28=784个元素。
接下来
data_train.info()
运行后出现以下结果:

由上可知,训练集共有42000组数据,每组数据都是一张图片,每组数据都有785列,其中第一列为label,剩下的784列则由图片拉成向量组成。
虽然改代码不使用训练集,但还是顺便输出出来看一下
data_test.head()
结果如下:

可以轻松的发现,测试集理所当然的少了label,因为在提交结果时就是要来预测测试集中的label。
接下来看一下测试集的属性
data_test.info()
结果如下:

其中,测试集只有28000组数据,少于训练集的42000组。测试集只有784列,因为没有label。
还原前几张图片出来看看(前5张)
for i in np.arange(5):
num=data_train.iloc[i]
pic=np.array(num)
pic=pic[1:785]
pic=pic.reshape(28,28)
plt.title(str(num.label))
plt.imshow(pic,cmap="gray")
plt.show()
结果如下:



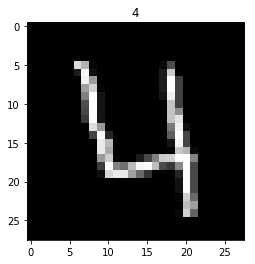

对照之前输出的训练集的前5行数据的label可以发现这5张图片确实对应的是数字1、0、1、4、0。
接下来需要去掉标签特征的相关性,将标签进行独热编码,因为例如数字1和数字5是没有谁优谁劣的,如果直接用1和5来作为标签,则会误导计算机数字5比数字1要好\坏5倍的潜在含义。
label_dummies = pd.get_dummies(data_train['label'])
data_train = data_train.join(label_dummies)
接下来再看一下数据集当前是什么样的
data_train.head()
结果如下所示:

可以发现,在训练集中的最后10列增加了10个特征,此时这10个特征中1位于10个特征中的第几列,那该行数据的label就是几。
使用神经网络算法进行训练,此处设计简单的双层神经网络
# 初始化一个 Session
ops.reset_default_graph()
sess = tf.Session()
# 调参时固定随机种子
seed = 1
tf.set_random_seed(seed)
np.random.seed(seed)
分割数据集来调试参数
predictors=data_train.columns.values.tolist()[1:785]
x_vals=data_train[predictors]
label_dum=data_train.columns.values.tolist()[785:]
y_vals=data_train[label_dum]
# 分割训练集 train/test = 80%/20%
train_indices = np.random.choice(len(x_vals), round(len(x_vals)*0.8), replace=False)
test_indices = np.array(list(set(range(len(x_vals))) - set(train_indices)))
x_vals_train = x_vals.loc[train_indices]
x_vals_test = x_vals.loc[test_indices]
y_vals_train = y_vals.loc[train_indices]
y_vals_test = y_vals.loc[test_indices]
将所有数据都转化为 28 × 28 28\times28 28×28的图片的形式:
x_vals_train=x_vals_train.values
x_vals_train=x_vals_train.reshape(-1,28,28,1)
x_vals_test=x_vals_test.values
x_vals_test=x_vals_test.reshape(-1,28,28,1)
y_vals_train=y_vals_train.values
y_vals_test=y_vals_test.values
定义权重和偏置以及输出输出占位符:
# 定义变量函数 (weights and bias)
def init_weight(shape, st_dev):
weight = tf.Variable(tf.random_normal(shape, stddev=st_dev))
return(weight)
def init_bias(shape, st_dev):
bias = tf.Variable(tf.random_normal(shape, stddev=st_dev))
return(bias)
# 创建占位符(Placeholders)
x_data = tf.placeholder(shape=[None,28,28,1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 10], dtype=tf.float32)
构建卷积神经网络
p_keep_conv=tf.placeholder('float')
p_keep_hidden=tf.placeholder('float')
rand_st_dev=0.01
w=init_weight([3,3,1,32], st_dev=rand_st_dev)
w2=init_weight([3,3,32,64], st_dev=rand_st_dev)
w3=init_weight([3,3,64,128], st_dev=rand_st_dev)
w4=init_weight([128*4*4,1024], st_dev=rand_st_dev)
w_o=init_weight([1024,10], st_dev=rand_st_dev)
#定义第一组卷积层和池化层,最后dropout掉一些神经元
l1a=tf.nn.relu(tf.nn.conv2d(x_data,w,strides=[1,1,1,1],padding='SAME'))
l1=tf.nn.max_pool(l1a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
l1=tf.nn.dropout(l1,p_keep_conv)
#定义第二组卷积层和池化层,最后dropout掉一些神经元
l2a=tf.nn.relu(tf.nn.conv2d(l1,w2,strides=[1,1,1,1],padding='SAME'))
l2=tf.nn.max_pool(l2a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
l2=tf.nn.dropout(l2,p_keep_conv)
#定义第三组卷积层和池化层,最后dropout掉一些神经元
l3a=tf.nn.relu(tf.nn.conv2d(l2,w3,strides=[1,1,1,1],padding='SAME'))
l3=tf.nn.max_pool(l3a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
l3=tf.reshape(l3,[-1,w4.get_shape().as_list()[0]])
l3=tf.nn.dropout(l3,p_keep_conv)
#全连接层,最后dropout掉一些神经元
l4=tf.nn.relu(tf.matmul(l3,w4))
l4=tf.nn.dropout(l4,p_keep_hidden)
#输出层
final_output=tf.matmul(l4,w_o)
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=final_output,labels=y_target))
train_step=tf.train.RMSPropOptimizer(0.001,0.9).minimize(loss)
predict_step=tf.argmax(final_output,1)
定义计算准确率的op
predictions=tf.placeholder(shape=[None,10], dtype=tf.int32)
train_correct_prediction = tf.equal(tf.argmax(y_vals_train,1),
tf.argmax(predictions,1))
train_accuracy_op = tf.reduce_mean(tf.cast(train_correct_prediction, tf.float32))
test_correct_prediction = tf.equal(tf.argmax(y_vals_test,1),
tf.argmax(predictions,1))
test_accuracy_op = tf.reduce_mean(tf.cast(test_correct_prediction, tf.float32))
用训练集和验证集来调参
# 训练循环
loss_vec = []
test_loss = []
train_acc=[]
test_acc=[]
# 定义批量大小
batch_size = 1024
#在会话中启动图,开始训练和测试
with tf.Session() as sess:
tf.global_variables_initializer().run()
k=0
for i in range(100):
training_batch=zip(range(0,len(x_vals_train),batch_size),
range(batch_size,len(x_vals_train)+1,batch_size))
for star,end in training_batch:
sess.run(train_step, feed_dict={x_data: x_vals_train[star:end],
y_target: y_vals_train[star:end],
p_keep_conv:0.6,p_keep_hidden:0.5})
k=k+1
temp_loss = sess.run(loss, feed_dict={x_data: x_vals_train[star:end],
y_target: y_vals_train[star:end],
p_keep_conv:0.6,p_keep_hidden:0.5})
loss_vec.append(np.sqrt(temp_loss))
predictions_train=sess.run(final_output,feed_dict={x_data: x_vals_train,
p_keep_conv:1.0,p_keep_hidden:1.0})
train_accuracy=sess.run(train_accuracy_op,feed_dict={predictions:predictions_train})
train_acc.append(train_accuracy)
test_temp_loss = sess.run(loss, feed_dict={x_data: x_vals_test,
y_target:y_vals_test,
p_keep_conv:0.6,p_keep_hidden:0.5})
test_loss.append(np.sqrt(test_temp_loss))
predictions_test=sess.run(final_output,feed_dict={x_data: x_vals_test,
p_keep_conv:1.0,p_keep_hidden:1.0})
test_accuracy=sess.run(test_accuracy_op,feed_dict={predictions:predictions_test})
test_acc.append(test_accuracy)
print('第'+str(i+1)+"轮训练")
print('迭代次数为: ' + str(k+1) + '. 训练误差为 = ' + str(temp_loss)+
'. 测试误差为 = ' + str(test_temp_loss))
print("训练集准确率为: " + str(train_accuracy) + " . 测试集准确率为: " + str(test_accuracy))
print(" ")
最后几行的输出为:
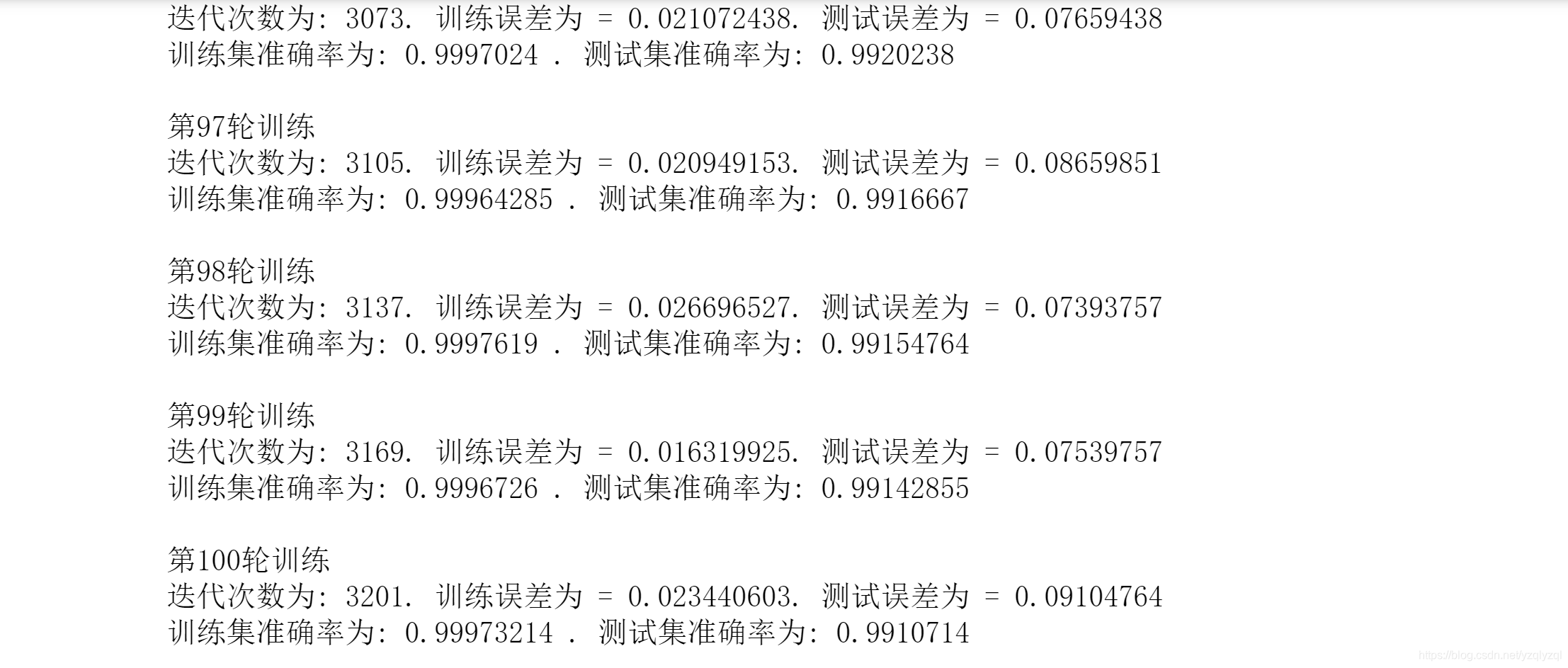
可知,经过100轮训练后,测试集误差为
99.2
%
99.2\%
99.2%左右。
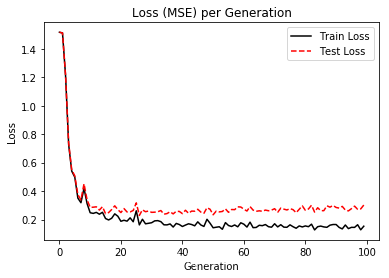
最后画个图来看看损失函数和误差的趋势:
%matplotlib inline
# Plot loss (MSE) over time
plt.plot(loss_vec, 'k-', label='Train Loss')
plt.plot(test_loss, 'r--', label='Test Loss')
plt.title('Loss (MSE) per Generation')
plt.legend(loc='upper right')
plt.xlabel('Generation')
plt.ylabel('Loss')
plt.show()
# Plot train and test accuracy
plt.plot(train_acc, 'k-', label='Train Set Accuracy')
plt.plot(test_acc, 'r--', label='Test Set Accuracy')
plt.title('Train and Test Accuracy')
plt.xlabel('Generation')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
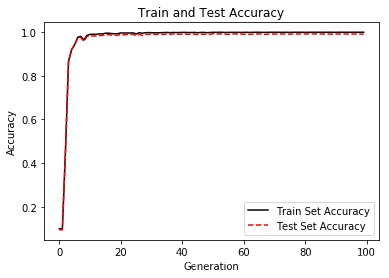
至此,用于调试参数的代码讲解结束,完整的代码请参照开头百度云盘中的MNIST_ConvNet_update_parameters.ipynb或MNIST_ConvNet_update_parameters.py。
用于提交结果的代码讲解
通常来说,用于提交结果的代码是用用于调试参数的代码来修改得来的,这样比较方便且会减少未知bug的发生。此时使用调好的参数和所有训练数据来训练网络。
首先,依然是先导入所需的库
# 数据分析库
import pandas as pd
# 科学计算库
import numpy as np
# 导入tensorflow
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.python.framework import ops
然后导入训练集合测试集
data_train = pd.read_csv("train.csv")
data_test = pd.read_csv("test.csv")
去掉训练集标签(label)特征的相关性
label_dummies = pd.get_dummies(data_train['label'])
data_train = data_train.join(label_dummies)
使用神经网络算法进行训练,此处按卷积神经网络的结构来设计网络
# 初始化一个 Session
ops.reset_default_graph()
sess = tf.Session()
# 调参时固定随机种子
seed = 1
tf.set_random_seed(seed)
np.random.seed(seed)
预处理数据集
predictors=data_train.columns.values.tolist()[1:785]
x_train=data_train[predictors]
label_dum=data_train.columns.values.tolist()[785:]
y_train=data_train[label_dum]
x_test=data_test[predictors]
将数据集重构为 28 × 28 28\times28 28×28的图像:
x_train=x_train.values
x_train=x_train.reshape(-1,28,28,1)
x_test=x_test.values
x_test=x_test.reshape(-1,28,28,1)
y_train=y_train.values
定义权重和偏置函数
# 定义变量函数 (weights and bias)
def init_weight(shape, st_dev):
weight = tf.Variable(tf.random_normal(shape, stddev=st_dev))
return(weight)
def init_bias(shape, st_dev):
bias = tf.Variable(tf.random_normal(shape, stddev=st_dev))
return(bias)
# Create Placeholders
x_data = tf.placeholder(shape=[None,28,28,1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 10], dtype=tf.float32)
构建卷积神经网络
p_keep_conv=tf.placeholder('float')
p_keep_hidden=tf.placeholder('float')
rand_st_dev=0.01
w=init_weight([3,3,1,32], st_dev=rand_st_dev)
w2=init_weight([3,3,32,64], st_dev=rand_st_dev)
w3=init_weight([3,3,64,128], st_dev=rand_st_dev)
w4=init_weight([128*4*4,1024], st_dev=rand_st_dev)
w_o=init_weight([1024,10], st_dev=rand_st_dev)
#定义第一组卷积层和池化层,最后dropout掉一些神经元
l1a=tf.nn.relu(tf.nn.conv2d(x_data,w,strides=[1,1,1,1],padding='SAME'))
l1=tf.nn.max_pool(l1a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
l1=tf.nn.dropout(l1,p_keep_conv)
#定义第二组卷积层和池化层,最后dropout掉一些神经元
l2a=tf.nn.relu(tf.nn.conv2d(l1,w2,strides=[1,1,1,1],padding='SAME'))
l2=tf.nn.max_pool(l2a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
l2=tf.nn.dropout(l2,p_keep_conv)
#定义第三组卷积层和池化层,最后dropout掉一些神经元
l3a=tf.nn.relu(tf.nn.conv2d(l2,w3,strides=[1,1,1,1],padding='SAME'))
l3=tf.nn.max_pool(l3a,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
l3=tf.reshape(l3,[-1,w4.get_shape().as_list()[0]])
l3=tf.nn.dropout(l3,p_keep_conv)
#全连接层,最后dropout掉一些神经元
l4=tf.nn.relu(tf.matmul(l3,w4))
l4=tf.nn.dropout(l4,p_keep_hidden)
#输出层
final_output=tf.matmul(l4,w_o)
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=final_output,labels=y_target))
train_step=tf.train.RMSPropOptimizer(0.001,0.9).minimize(loss)
predict_step=tf.argmax(final_output,1)
在此处声明计算准确率的op
predictions=tf.placeholder(shape=[None,10], dtype=tf.int32)
train_correct_prediction = tf.equal(tf.argmax(y_train,1),
tf.argmax(predictions,1))
train_accuracy_op = tf.reduce_mean(tf.cast(train_correct_prediction, tf.float32))
训练网络,预测并写入结果
# 训练循环
loss_vec = []
train_acc=[]
# 定义批量大小
batch_size = 1024
#在会话中启动图,开始训练和测试
with tf.Session() as sess:
tf.global_variables_initializer().run()
k=0
for i in range(200):
training_batch=zip(range(0,len(x_train),batch_size),
range(batch_size,len(x_train)+1,batch_size))
for star,end in training_batch:
sess.run(train_step, feed_dict={x_data: x_train[star:end],
y_target: y_train[star:end],
p_keep_conv:0.8,p_keep_hidden:0.5})
k=k+1
temp_loss = sess.run(loss, feed_dict={x_data: x_train,
y_target: y_train,
p_keep_conv:0.8,p_keep_hidden:0.5})
loss_vec.append(np.sqrt(temp_loss))
predictions_now=sess.run(final_output,feed_dict={x_data: x_train,
p_keep_conv:1.0,p_keep_hidden:1.0})
train_accuracy=sess.run(train_accuracy_op,feed_dict={predictions:predictions_now})
train_acc.append(train_accuracy)
print('第'+str(i+1)+"轮训练")
print('迭代次数为: ' + str(k+1) + '. 训练误差为 = ' + str(temp_loss))
print("训练集准确率为: " + str(train_accuracy))
print(" ")
# 预测并写入结果
data_test_predictions=sess.run(final_output,feed_dict={x_data: x_test,p_keep_conv:1.0,p_keep_hidden:1.0})
predictions=sess.run(tf.argmax(data_test_predictions,1))
Submission = pd.DataFrame({'ImageId':np.arange(1,28001),'Label':predictions})
Submission.to_csv('20190814_1.csv',index=False,sep=',')
上述代码输出为:

可见在训练集上已经接近于完美拟合了。
最后绘制损失函数和误差率趋势图:
%matplotlib inline
# Plot loss (MSE) over time
plt.plot(loss_vec, 'k-', label='Train Loss')
plt.title('Loss (MSE) per Generation')
plt.legend(loc='upper right')
plt.xlabel('Generation')
plt.ylabel('Loss')
plt.show()
# Plot train and test accuracy
plt.plot(train_acc, 'k-', label='Train Set Accuracy')
plt.title('Train and Test Accuracy')
plt.xlabel('Generation')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
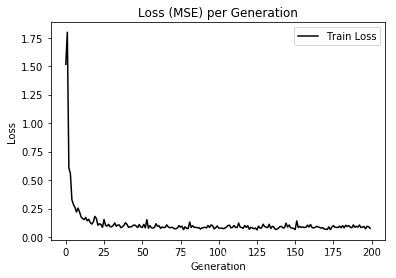
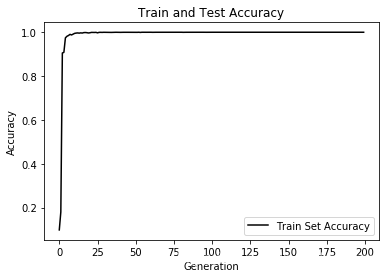
至此,用于提交结果的代码讲解结束,完整的代码请参照开头百度云盘中的MNIST_ConvNet_submit.ipynb或MNIST_ConvNet_submit.py。
提交文件 20190814_1.csv 至kaggle后得到了0.99342的成绩,即
99.342
%
99.342\%
99.342%的准确率。
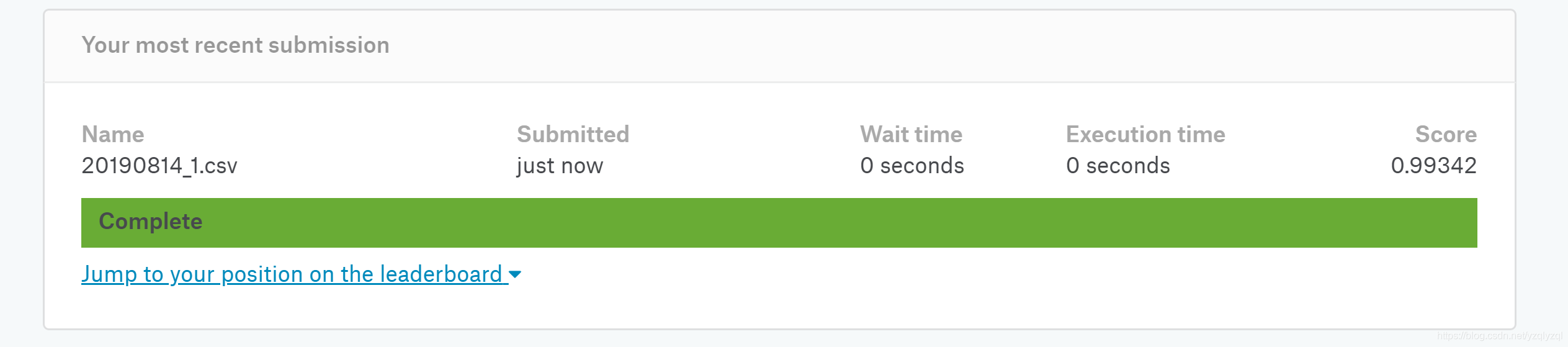

















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









