






老板说要支持70万QPS?一位数据魔芋师的咸鱼翻身记
“老板,我们的查询被打爆了!”
“产品说要支持70万QPS!”
“运维说数据库要被薅死了!”
每当听到这些呼救声,你是不是也和我一样,陷入了沉思?作为一名资深数据魔芋师,这些场景简直太熟悉了!
还记得那个周一早上,产品经理神秘兮兮地拉住我:“听说你很懂数据库?我们的用户画像查询要扛住每秒70万次访问…”
我差点没把刚喝进去的咖啡喷出来!
不过,经历过最初的惊讶后,我决定迎难而上。在深入研究和实践后,我找到了破局之道-Doris 高并发点查。
![[tu]](https://i-blog.csdnimg.cn/direct/5d38e2f16bda4939b0e18d706dd8944a.png)
玩转Doris高并发点查:70W QPS背后的故事
高并发点查,听起来是个老生常谈的话题。作为一名数据从业者,你一定遇到过这样的场景:产品经理兴冷得来找你,说咱们的用户画像查询要扛住每秒70万次的访问量。你先是一愣,随后陷入沉思 - 这可不是一个简单的需求啊!
不过别担心,今天我们就来聊聊Apache Doris是如何玩转高并发点查的。作为一款MPP数据库,Doris不仅能做OLAP分析,在高并发场景下的表现同样亮眼。
![[tu]](https://i-blog.csdnimg.cn/direct/b1573cf85d2048f1b23723e7e09a158f.png)
高并发点查的痛点
故事要从一个真实的业务场景说起。某电商平台的订单分析系统,每天面临着海量数据的并发请求。用户要查询下单结果,客服需要查订单详情,商家要查付款信息…这些看似简单的查询,背后都是对数据库的考验。
传统的列式存储在这类场景下会遇到哪些问题呢?一张订单表通常有至少几十上百个字段,用户每次查询都需要获取完整的订单信息。如果使用列存,就要读取所有列的数据,这意味着大量的随机IO。更糟糕的是,每次查询都要经过SQL解析、生成执行计划、调度执行等一系列复杂的步骤。在高并发场景下,这些开销会被成倍放大。
Doris的破局之道
面对这些挑战,Doris团队提出了一套完整的解决方案。这套方案的精妙之处在于:它不是简单地对某个环节进行优化,而是从数据存储、查询执行、SQL解析等多个维度进行全方位的改造。
![[tu]](https://i-blog.csdnimg.cn/direct/d8b4a981ec824eb4becc31fff3c409ac.png)
上面的架构图展示了Doris高并发点查的核心组件。从下往上看:在存储层,引入了行存格式与行缓存机制;在查询层,实现了短路径优化;在接入层,提供了预编译语句支持。这些组件互相配合,形成了一个高效的查询链路。
让我们先来看看这套方案最基础的部分 - 存储层的优化。在Doris 2.0中,用户可以在建表时通过设置store_row_column属性来启用行存。这意味着除了传统的列存之外,数据还会按行组织存储一份。虽然这会带来一定的存储开销,但在点查场景下,一次IO就能读取一行完整的数据,大大提升了查询效率。下面是点查结合行存在 在 Unique 模型下开启 Merge-On-Write 策略的一个例子:
CREATE TABLE `tbl_point_query` (
`key` int(11) NULL,
`v1` decimal(27, 9) NULL,
`v2` varchar(30) NULL,
`v3` varchar(30) NULL,
`v4` date NULL,
`v5` datetime NULL,
`v6` float NULL,
`v7` datev2 NULL
) ENGINE=OLAP
UNIQUE KEY(`key`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`key`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"store_row_column" = "true"
);
结合行存,Doris还引入了专门的行缓存机制。这个缓存基于LRU(最近最少使用)算法,可以自动淘汰不常用的数据。通过合理设置缓存大小,热点数据的查询可以直接从内存中返回,进一步提升查询性能。通过指定下面的的 BE 配置来开启:
disable_storage_row_cache 是否开启行缓存,默认不开启
row_cache_mem_limit 指定 Row cache 占用内存的百分比,默认 20% 内存
应用实践优化
Doris高并发点查原理和实践全析可查阅以往的文章:【Apache Doris】如何实现高并发点查?(原理+实践全析)
一个有趣的类比:如果把传统的查询过程比作"坐火车",需要买票、安检、候车、经过多个站点,那么Doris的短路径优化就像是"直升机"模式 - 直接起飞,到达目的地。
这个短路径优化是怎么实现的呢?在Doris中,发现一个查询满足以下条件时:
- 数据表开启了行存模式
- 查询目标是UNIQUE KEY模型的表
- WHERE条件包含所有Key列的等值条件
- 没有复杂的JOIN或子查询
它会立即生成一个轻量级的执行计划,绕过传统的优化器,直接定位到目标数据。这就像是给查询开了一条"专用通道"。通过EXPLAIN命令,你会在执行计划中看到SHORT-CIRCUIT标记,这就是短路径优化的标志。
让我们再回到缓存优化。除了前面提到的行缓存,Doris还在SQL解析层面做了优化。通过PreparedStatement机制,将SQL模板和执行计划缓存在会话级别。这种优化特别适合那些"查询模式固定,只是参数不同"的场景。
打个比方:如果把SQL查询比作点餐,传统模式就像每次都要从头点餐、厨师看菜单、准备食材。而使用PreparedStatement就像是"老顾客点老套餐",报个编号就行,既省时又高效。
实战小结
光说不练假把式。在一个真实的业务场景中,我们对Doris的高并发点查进行了压测。测试环境如下:
- 16核CPU,32G内存
- SSD存储
- 单节点部署
- 3200万测试数据
调优前的准备工作:
-- 创建优化表
CREATE TABLE `row_part` (
`p_partkey` int(11) NULL,
`p_name` varchar(69) NULL,
...
) ENGINE=OLAP
UNIQUE KEY(`p_partkey`, `p_name`)
PROPERTIES (
"store_row_column" = "true",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true"
);
JDBC连接配置:
jdbc:mysql:loadbalance://fe_ip:9030/db?characterEncoding=utf8&useSSL=false&useServerPrepStmts=true;cachePrepStmts=true&prepStmtCacheSqlLimit=1024
这套配置组合下,系统轻松上万QPS,而CPU使用率仅为50%左右。
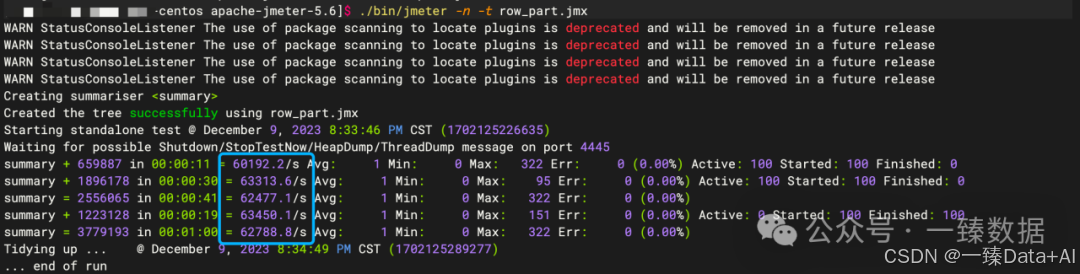
是不是很惊艳?你现在可能跃跃欲试了。
不过在开始之前,可以注意以下几点:
- 数据分布要均衡,避免热点问题
- 建表时合理设置分桶数,不要太大也不要太小
- PreparedStatement参数值要足够分散
- 适当调整FE最大连接数和用户最大连接数
- 确保所有查询条件都包含在Key列中。漏掉一个条件,可能就走不了短路径了
- 监控BE节点的内存使用情况,适时调整行缓存的比例
- 在多FE部署场景下,建议通过Observer角色来分担查询压力
别担心失败,正如一位前辈说过:“优化就像探索迷宫,每次碰壁都是在为成功积累经验。”
看到这里,相信你对Doris的高并发点查已经有了深入的了解。当然,技术在不断发展,Doris团队也在持续优化这个特性。
还记得那个让你发愁的70万QPS需求吗?现在你是不是已经胸有成竹了?欢迎在评论区或私信分享你的实践经验,我们下期再见!


















 9800
9800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









