






 本文介绍了作者尝试编写一个简单且高性能的JSON解析器的过程,从错误的做法开始,如使用栈解析导致的问题,然后转向词法分析和语法分析。作者通过优化避免了字符串拷贝,利用Unsafe和MethodHandle提高性能,以及选择了LinkedList和HashMap作为数据结构。对于UTF16编码的处理和内存管理是挑战,作者进行了针对性的优化。测试结果显示性能接近fastjson。
本文介绍了作者尝试编写一个简单且高性能的JSON解析器的过程,从错误的做法开始,如使用栈解析导致的问题,然后转向词法分析和语法分析。作者通过优化避免了字符串拷贝,利用Unsafe和MethodHandle提高性能,以及选择了LinkedList和HashMap作为数据结构。对于UTF16编码的处理和内存管理是挑战,作者进行了针对性的优化。测试结果显示性能接近fastjson。
1.前言
搞计算机很长时间了,接触JSON也很久了,只不过一直都是用第三方库来进行解析,所以现在下定决定,准备自己写一个JSON解析器,首先就是第一个,简单易用,最好几百行就能够解决。其次就是尽量高性能,不能太慢。
2.正文
我首先说一种错误做法的解析办法,是的,你没有听错,错误的解析办法,我自己看到json数据的第一反应。
最开始的时候我是准备使用rust语言来写这个json解析器,但是很久没有用了,看到的一瞬间感觉已经忘完了,所以默默的又用回了Java语言。我下面这个json example就来自rust写的json解析器(Serde Json)
{
"name": "John Doe",
"age": 43,
"address": {
"street": "10 Downing Street",
"city": "London"
},
"phones": [
"+44 1234567",
"+44 2345678"
]
}我们可以看到一个{},里面还可以嵌套{},看到这里我的第一想法就是使用stack。这样子就可以当读取'}'的时候就取数据,直到取到'{'字符。但是这样子那么就只能取到相反的数据。
{"name":"yymjr"}
}"rimyy":"eman"{那么我们就需要对""里面的字符串进行倒序,如此一来那么就会极大的浪费性能,这就是为什么我会说这是一个错误的做法。
在我查询相关资料后(实在是没有找到原文,手写了一个简单的JSON解析器,网友直乎:牛!),原来是使用词法分析后进行分词,然后再语法分析(题外话:词法分析是Tokenizer,分出来的东西叫做Token,原本我还以为是word,后来查询资料才知道原来是表达标记的含义。tokenize和tokenizer到底怎么翻译?)这当中没有什么太好说的,思路大家一看就能明白,但是关键是性能太低啦!!!
于是我就开始优化啦,首先就是第一个想法,零拷贝。首先就是第一个我们在不断的创造String,但是我们创造的String中的字符其实是在原本的json数据中,所以第一步就是词法分析的字符串不能去拷贝。我使用的openJDK 18,在这个版本上,String类相比于已经有很大的变化了。首先就是第一个原来的value的类型由char[]变成byte[];其次就是编码问题,原本是只有UTF16编码,后面就引入了LATIN1编码。于是我就是Unsafe直接进行获取了。
private static final Unsafe UNSAFE;
private static long FIELD_STRING_VALUE_OFFSET;
private static long FIELD_STRING_CODER_OFFSET;
static {
Unsafe unsafe = null;
try {
Field theUnsafeField = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafeField.setAccessible(true);
unsafe = (Unsafe) theUnsafeField.get(null);
Field field = String.class.getDeclaredField("value");
FIELD_STRING_VALUE_OFFSET = unsafe.objectFieldOffset(field);
field = String.class.getDeclaredField("coder");
FIELD_STRING_CODER_OFFSET = unsafe.objectFieldOffset(field);
} catch (Throwable ignored) {
}
UNSAFE = unsafe;
}
public static Map<String, Object> toJsonObject(String src) {
byte[] value = (byte[]) UNSAFE.getObject(src, FIELD_STRING_VALUE_OFFSET);
byte codec = UNSAFE.getByte(src, FIELD_STRING_CODER_OFFSET);
}其中编码LATIN1是可以使用的,没有什么大问题。关键就是在于UTF16,他是固定2byte,为了兼容ASCII,直接后面添加了一个值为0的byte。无法处理,所以我是转成了UTF8编码,只不过String自带的getBytes方法会出一次Arrays.copyOf方法的消耗。相关资料(提升 Java 字符串编码解码性能的技巧)
private static byte[] encodeUTF8_UTF16(byte[] val, boolean doReplace) {
int dp = 0;
int sp = 0;
int sl = val.length >> 1;
byte[] dst = new byte[sl * 3];
while (sp < sl) {
// ascii fast loop;
char c = StringUTF16.getChar(val, sp);
if (c >= '\u0080') {
break;
}
dst[dp++] = (byte)c;
sp++;
}
while (sp < sl) {
char c = StringUTF16.getChar(val, sp++);
if (c < 0x80) {
dst[dp++] = (byte)c;
} else if (c < 0x800) {
dst[dp++] = (byte)(0xc0 | (c >> 6));
dst[dp++] = (byte)(0x80 | (c & 0x3f));
} else if (Character.isSurrogate(c)) {
int uc = -1;
char c2;
if (Character.isHighSurrogate(c) && sp < sl &&
Character.isLowSurrogate(c2 = StringUTF16.getChar(val, sp))) {
uc = Character.toCodePoint(c, c2);
}
if (uc < 0) {
if (doReplace) {
dst[dp++] = '?';
} else {
throwUnmappable(sp - 1);
}
} else {
dst[dp++] = (byte)(0xf0 | ((uc >> 18)));
dst[dp++] = (byte)(0x80 | ((uc >> 12) & 0x3f));
dst[dp++] = (byte)(0x80 | ((uc >> 6) & 0x3f));
dst[dp++] = (byte)(0x80 | (uc & 0x3f));
sp++; // 2 chars
}
} else {
// 3 bytes, 16 bits
dst[dp++] = (byte)(0xe0 | ((c >> 12)));
dst[dp++] = (byte)(0x80 | ((c >> 6) & 0x3f));
dst[dp++] = (byte)(0x80 | (c & 0x3f));
}
}
if (dp == dst.length) {
return dst;
}
return Arrays.copyOf(dst, dp);
}根据我的测试,官方的String的encodeUTF8_UTF16方法之所以会Arrays.copyOf,单纯是因为会超出。UTF8的编码长度是变长的,1byte~3byte之间波动,而UTF16则是2byte固定,那么换句话来说,相同的char,UTF16会用double char length的byte数,而UTF8则是会在一倍和三倍的char length之间波动,为了安全从UTF16转换成UTF8,那么数就会是(src >> 1)*3。但大部分时候都会是用不满的,所以dp==dst.length则是直接返回,否则就copy一次,去掉无用的byte。于是我改造成下面这样子。
private static int encodeUTF8_UTF16(byte[] val, byte[] dst) throws Throwable {
int dp = 0;
int sp = 0;
int sl = val.length >> 1;
while (sp < sl) {
// ascii fast loop;
char c = (char) getChar.invoke(val, sp);
if (c >= '\u0080') {
break;
}
dst[dp++] = (byte) c;
sp++;
}
while (sp < sl) {
char c = (char) getChar.invoke(val, sp++);
if (c < 0x80) {
dst[dp++] = (byte) c;
} else if (c < 0x800) {
dst[dp++] = (byte) (0xc0 | (c >> 6));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (Character.isSurrogate(c)) {
int uc = -1;
char c2;
if (Character.isHighSurrogate(c) && sp < sl &&
Character.isLowSurrogate(c2 = (char) getChar.invoke(val, sp))) {
uc = Character.toCodePoint(c, c2);
}
if (uc < 0) {
dst[dp++] = '?';
} else {
dst[dp++] = (byte) (0xf0 | ((uc >> 18)));
dst[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dst[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (uc & 0x3f));
sp++; // 2 chars
}
} else {
// 3 bytes, 16 bits
dst[dp++] = (byte) (0xe0 | ((c >> 12)));
dst[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dst[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
return dp;
}直接返回到有用的dp offset用来做长度。
if (codec == UTF16) {
byte[] utf8Val;
int dp;
try {
utf8Val = new byte[(value.length >> 1) * 3];
dp = encodeUTF8_UTF16(value, utf8Val);
} catch (Throwable ignored) {
utf8Val = src.getBytes(StandardCharsets.UTF_8);
dp = utf8Val.length;
}
return toJsonObject(utf8Val, codec, dp);
} else if (codec == LATIN1) {
return toJsonObject(value, codec, value.length);
} else {
throw new IllegalArgumentException();
}这就是第一个优化,第二个就是构造String字符串了,我们自己手动copy然后构造,比官方更快。
private static String quickCreateString(byte[] value, int from, int to, byte coder) {
try {
if (coder == LATIN1) {
byte[] copy = Arrays.copyOfRange(value, from, to);
String dst = (String) UNSAFE.allocateInstance(String.class);
UNSAFE.putObject(dst, FIELD_STRING_VALUE_OFFSET, copy);
UNSAFE.putByte(dst, FIELD_STRING_CODER_OFFSET, LATIN1);
return dst;
} else if (coder == UTF16) {
if (!(boolean) hasNegatives.invoke(value, from, to - from)) {
byte[] copy = Arrays.copyOfRange(value, from, to);
String dst = (String) UNSAFE.allocateInstance(String.class);
UNSAFE.putObject(dst, FIELD_STRING_VALUE_OFFSET, copy);
UNSAFE.putByte(dst, FIELD_STRING_CODER_OFFSET, LATIN1);
return dst;
}
return new String(value, from, to - from, StandardCharsets.UTF_8);
}
} catch (Throwable ignored) {
}
return new String(value, from, to - from);
}这上面两个方法都用到了String内部里面private的方法,一个是hasNegatives,另一个是getChar。我在这里用到了比反射更快的方法:MethodHandle。实际上这个也是有限制的,我使用了Unsafe绕过了限制。
private static MethodHandle hasNegatives;
private static MethodHandle getChar;
static{
field = MethodHandles.Lookup.class.getDeclaredField("IMPL_LOOKUP");
long fieldImplLookUpOffset = unsafe.staticFieldOffset(field);
MethodHandles.Lookup implLoopUp = (MethodHandles.Lookup)
unsafe.getObject(MethodHandles.Lookup.class, fieldImplLookUpOffset);
Class<?> StringCodingClazz = Class.forName("java.lang.StringCoding");
hasNegatives = implLoopUp.findStatic(StringCodingClazz, "hasNegatives",
MethodType.methodType(boolean.class, byte[].class, int.class, int.class));
Class<?> StringUTF16Clazz = Class.forName("java.lang.StringUTF16");
getChar = implLoopUp.findStatic(StringUTF16Clazz, "getChar",
MethodType.methodType(char.class, byte[].class, int.class));
}这当中的关键就是IMPL_LOOKUP,这个可以任意使用任何的private method,所以直接通过unsafe给拿了出来。
第三个优化点就是List和HashMap的选用。最开始的版本是使用ArrayList,但是DEFAULT_CAPACITY是10,在我做github上一份twitter.json(632KB大小)基准测试的时候频繁触法grow方法。
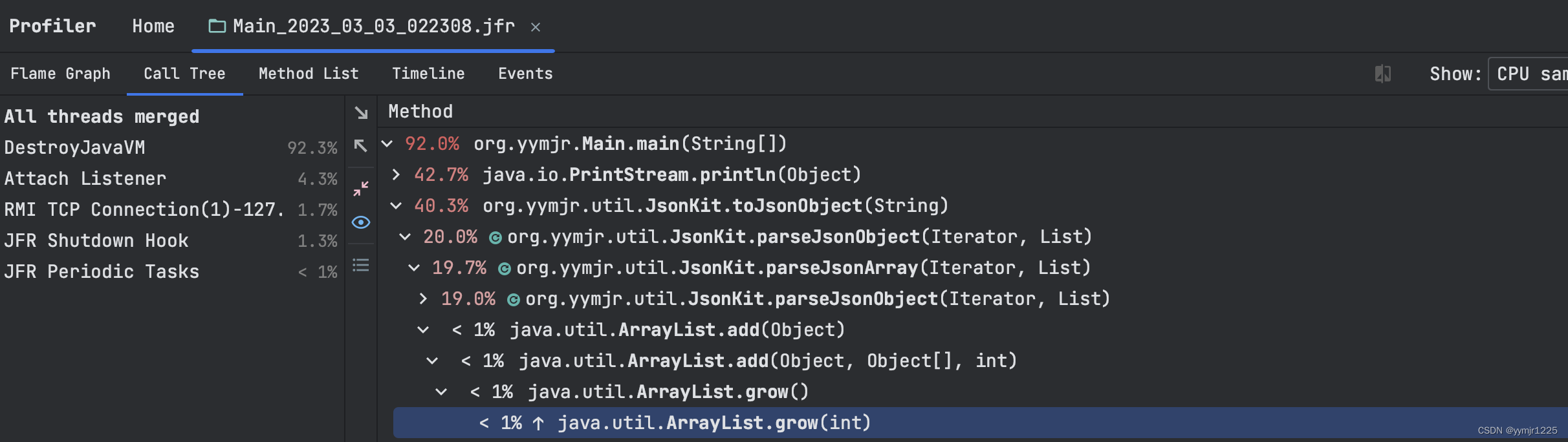
不能为了测试,而直接设置一个不符合常理的capacity,所以最后选用了LinkedList,当然不仅仅是这个只有这个原因,还有第二个。
在对tokens进行语法分析的时候,对STRING类型的token,需要获取上一个token进行判断是key还是value。这是原本的代码。
case STRING -> {
checkExpectToken(tokenType, expectToken);
int index = tokens.indexOf(token);
if (index < 1) {
throw new RuntimeException("Parse error, invalid Token.");
}
Token previousToken = tokens.get(index - 1);
if (previousToken.tokenType() == TokenType.SEP_COLON) {
jsonObject.put(key, token.value());
expectToken = TokenType.SEP_COMMA.getTokenCode() | TokenType.END_OBJECT.getTokenCode();
} else {
key = token.value();
expectToken = TokenType.SEP_COLON.getTokenCode();
}
}因为ArrayList使用的是数组,好查找和直接获取上一个,但是却非常拉低性能。
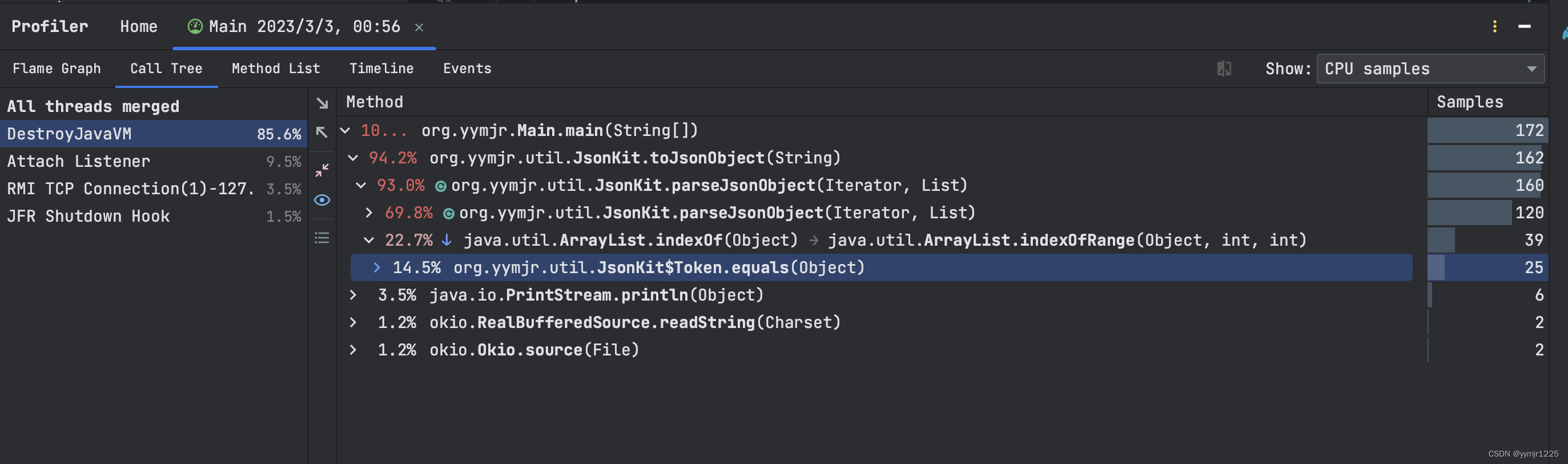
所以最后还是都选用链表数据结构的List和HashMap,毕竟绝大多数都是一个一个的来接着来处理的。
在这里我选用的是AWS的1G1H的免费云服务器来进行基准测试,其性能已经和fastjson差不太多了。
JsonBenchmark.fastJsonLatin1 10 avgt 5 9788984.071 ± 193277.199 ns/op
JsonBenchmark.fastJsonLatin1 100 avgt 5 9603627.329 ± 155930.828 ns/op
JsonBenchmark.fastJsonLatin1 1000 avgt 5 9606971.635 ± 212057.768 ns/op
JsonBenchmark.fastJsonLatin1 10000 avgt 5 9594331.713 ± 223208.279 ns/op
JsonBenchmark.fastJsonUtf16 10 avgt 5 767293101.160 ± 9073399.270 ns/op
JsonBenchmark.fastJsonUtf16 100 avgt 5 759272245.547 ± 18792641.022 ns/op
JsonBenchmark.fastJsonUtf16 1000 avgt 5 759646538.525 ± 14534378.110 ns/op
JsonBenchmark.fastJsonUtf16 10000 avgt 5 756438317.685 ± 6898206.062 ns/op
JsonBenchmark.jsonKitLatin1 10 avgt 5 6727534.304 ± 78733.867 ns/op
JsonBenchmark.jsonKitLatin1 100 avgt 5 6839250.111 ± 1016272.711 ns/op
JsonBenchmark.jsonKitLatin1 1000 avgt 5 6747038.955 ± 329687.366 ns/op
JsonBenchmark.jsonKitLatin1 10000 avgt 5 6854141.047 ± 118620.378 ns/op至于为什么没有Utf16的jsonKit数据是因为内存只有1G,我所使用的办法直接干出OOM了(测试数据使用fgo.json,有48.8MB大小,又是一个忘记从哪里弄来的测试数据)。
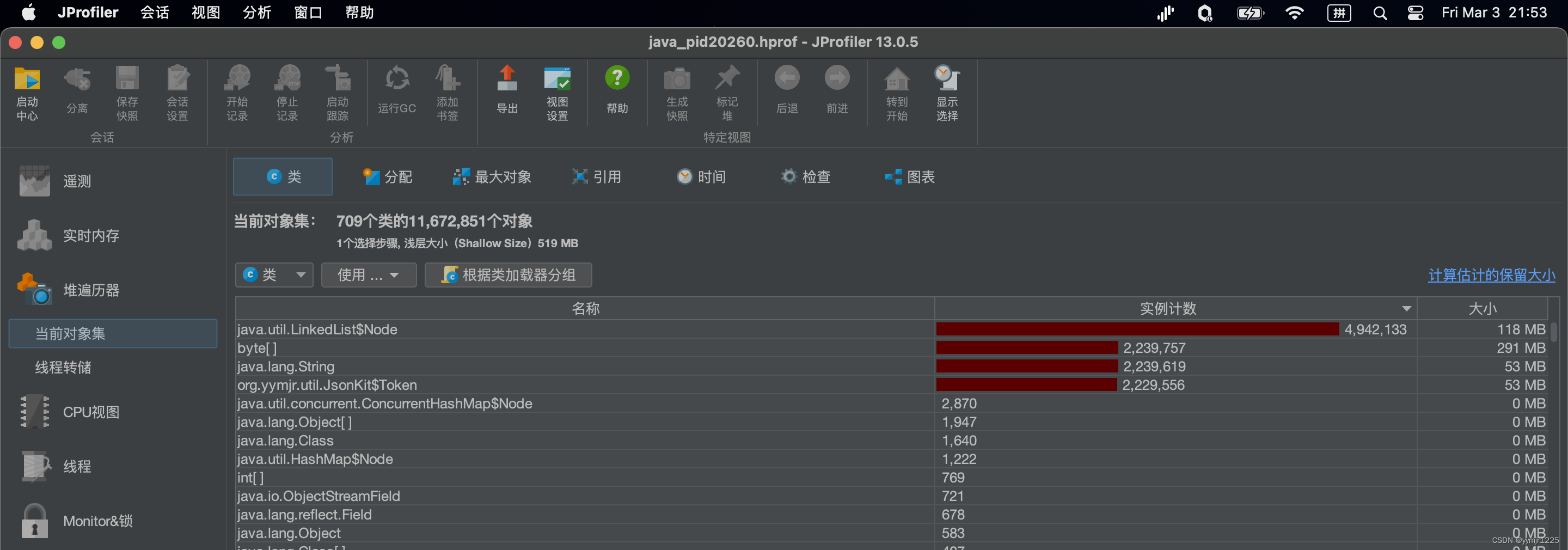
其实原本的json数据(utf8格式,48.8MB),转换成UTF16的String后,就变成了90多MB的byte[]了,而我再转成UTF8数据(还记得上面那个 (src.length>>1)*3公式嘛?),直接干到140MB大小,加起来就是差不多250MB了...
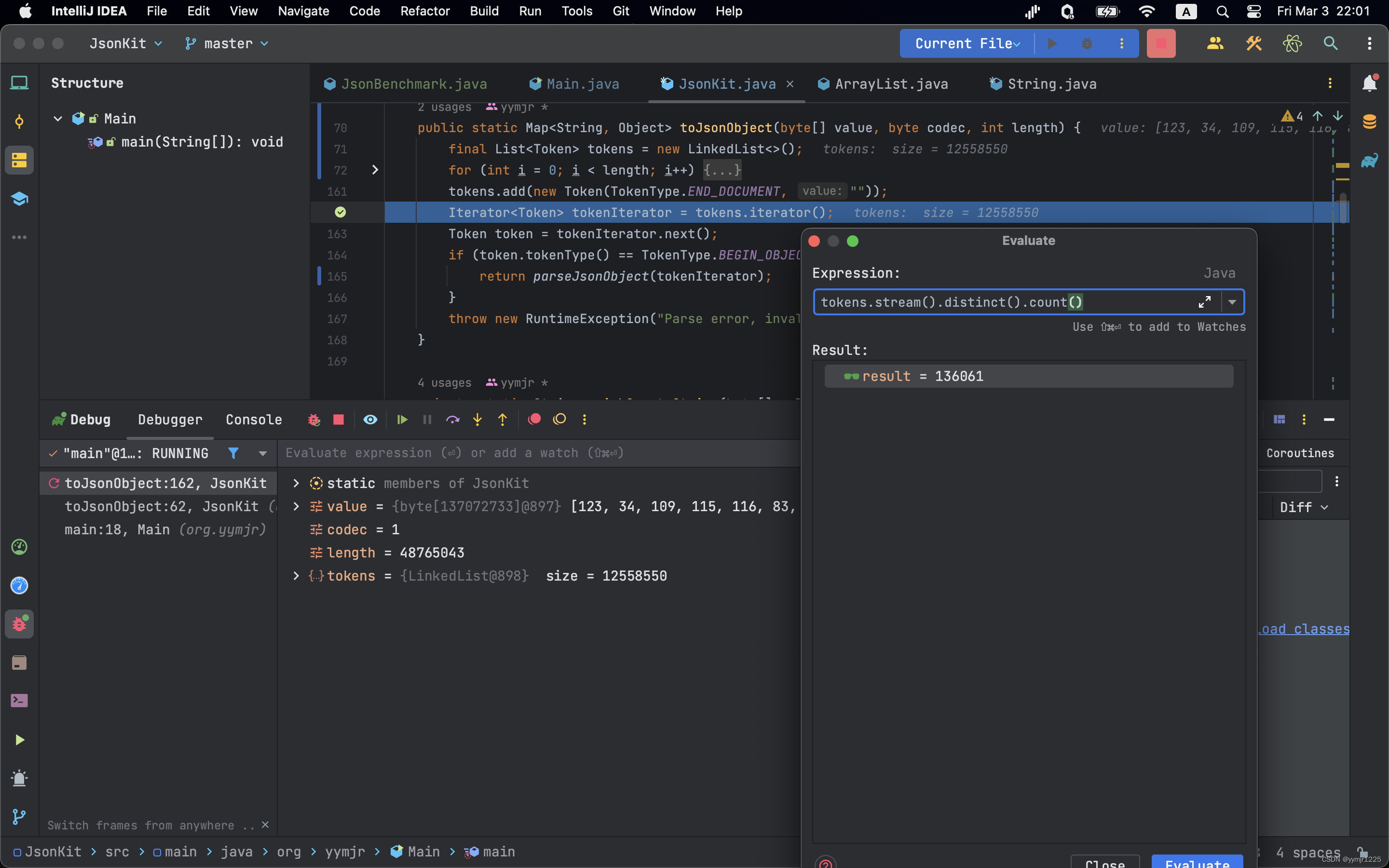
如果完整的运行下来ListNode有12558550个,接近于50MB的json,理解万岁!!!在使用静态的token后,真正动态的token有136061个。
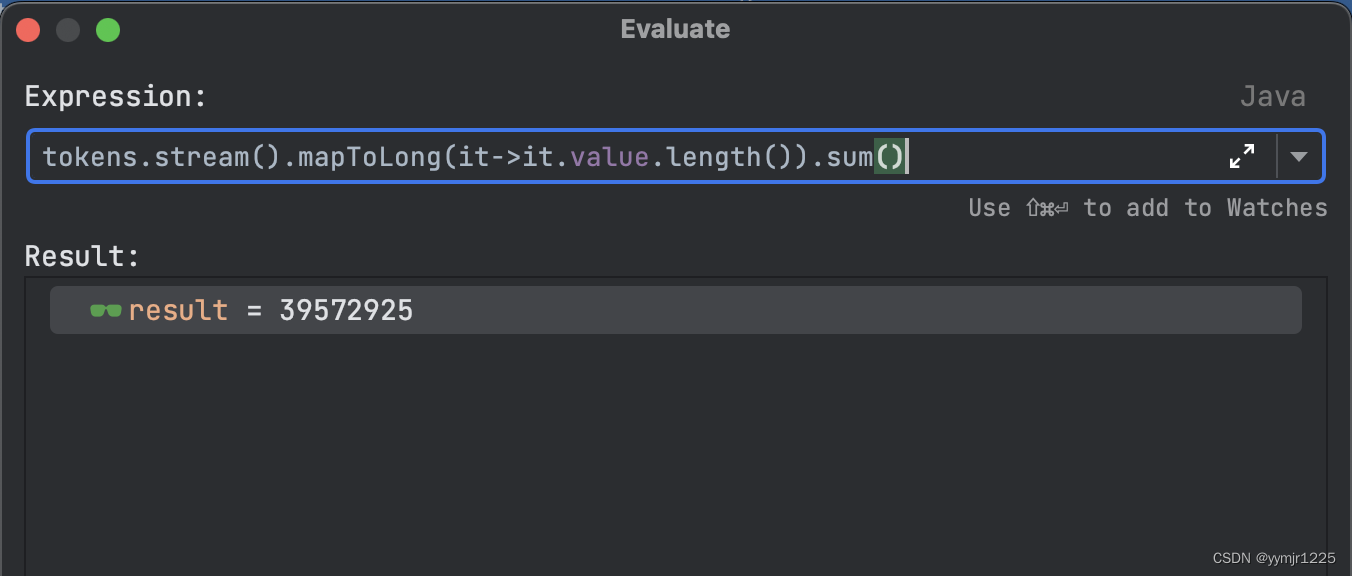
写文章的时候我突发奇想想要计算一下大概能使用多少MB,完整的。12558550*24byte+39572925byte=340978125byte=332986KB=326MB左右,0.0其中真正有用的就是那39572925byte9(tokentype至少需要100MB),value实际的利用率居然只有10%....看来下一步需要改进这个tokenType,一个就是24byte,实在是太费memory了。
接下来的是重点,接下来的是重点,接下来的是重点,重要的是说三遍!!!
值得讨论的就是第一个String.intern()方法(深入解析String#intern),这个方法会从常量池查询有没有该字符串,如果有就使用这个地址,如果没有,那么就会把这个字符串加进常量池中。但是请注意,String Pool是有大小限制,而且说到底他也是list形式,一旦加入过多的字符串会导致查找速度过慢,拖慢运行速度..在这里,我想的是要用热点数据来加进去这个intern,但是我想要简洁,争取整个jsonKit就几百行代码,所以很纠结,我更想的是给一个接口,让用户extends,让用户自己测试然后通过接口来判断要不要intern。
第二个就是json反序列化成JavaBean对象,根据资料来看,使用反射速度太慢,不如自己动手写,所以我想的就是使用注解,字节码来自动生成,既省力效率还好...哎,到时候再说吧,这应该就是我的理想方案。
最后就是关于UTF16编码格式的解决方案了,争取后续commit上GitHub。
最后附上该项目的地址吧:GitHub - yymjr/JsonKit


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









