






docker storm集群搭建和测试(windows版)
一.搭建storm集群
话不多说,直接利用docker compose一步到位:yml文件如下:
version: '2'
services:
zookeeper1:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk1.cloud
environment:
- SERVER_ID=1
- ADDITIONAL_ZOOKEEPER_1=server.1=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper2:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk2.cloud
environment:
- SERVER_ID=2
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper3:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk3.cloud
environment:
- SERVER_ID=3
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=0.0.0.0:2888:3888
ui:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: ui -c nimbus.host=nimbus
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
restart: always
container_name: ui
ports:
- 8080:8080
depends_on:
- nimbus
nimbus:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: nimbus -c nimbus.host=nimbus
restart: always
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
container_name: nimbus
ports:
- 6627:6627
supervisor:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: supervisor -c nimbus.host=nimbus -c supervisor.slots.ports=[6700,6701,6702,6703]
restart: always
environment:
- affinity:role!=supervisor
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
depends_on:
- nimbus
networks:
default:
external:
name: zk-net
文件命名为dock.yml。
之后打开dockerpower shell 执行下面命令启动配置:
docker-compose -f D:\docker_desktop\dock.yml up -d
关闭配置,运行下面命令:
docker-compose -f D:\docker_desktop\dock.yml stop
这样storm集群便搭建完成了,如下图:
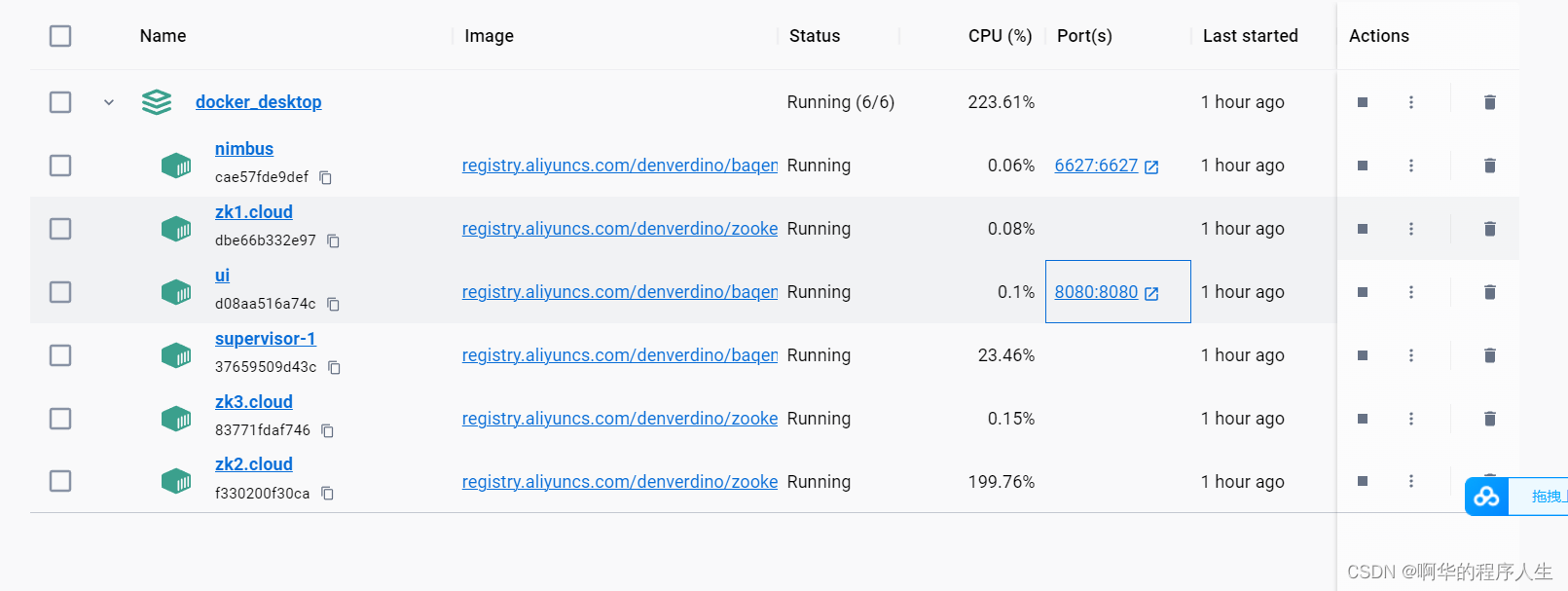
注意:看本教程前先在自己windows上下好docker desktop。
二.java连接storm开发测试
导入依赖:
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.0</version> <!-- 使用你需要的Storm版本 -->
</dependency>
</dependencies>
编写spout类:
创建一个java类名字为CSVReaderSpout,代码如下:
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.InputStreamReader;
import java.util.Map;
public class CSVReaderSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] files = {"H:\\a-storm测试\\股票数据1.csv"}; // 你的CSV文件路径,可以是多个
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
for (String file : files) {
try (BufferedReader br = new BufferedReader(
new InputStreamReader(
new FileInputStream(file),
"GBK"))){
br.readLine();// 跳过第一行
String line;
while ((line = br.readLine()) != null) {
Utils.sleep(1000);//每个1秒发射一次数据,太快会被电脑杀死进程
// 发射每一行数据
collector.emit(new Values(line));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
编写Bolt类:
创建一个java类,名字为StockStatisticsBolt,代码如下:
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
public class StockStatisticsBolt extends BaseRichBolt {
int count=0;
private Map<String, Double> stockTypeVolume = new HashMap<>();
private Map<String, Double> stockTypeAmount = new HashMap<>();
private Map<String, Double> hourVolume = new HashMap<>();
private Map<String, Double> hourAmount = new HashMap<>();
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
}
@Override
public void execute(Tuple tuple) {
String line = tuple.getStringByField("line");
// 解析CSV数据
String[] parts = line.split(",");
String time = parts[0];
String stockCode = parts[1];
String stockName = parts[2];
double price = Double.parseDouble(parts[3]);
double tradeVolume = Double.parseDouble(parts[4]);
String tradeType = parts[5];
String tradePlace = parts[6];
String tradePlatform = parts[7];
String industryType = parts[8];
// 统计不同类型的股票交易量和交易总金额
stockTypeVolume.put(stockCode, stockTypeVolume.getOrDefault(stockCode, 0.0) + tradeVolume);
stockTypeAmount.put(stockCode, stockTypeAmount.getOrDefault(stockCode, 0.0) + (price * tradeVolume));
// 解析时间并获取小时部分
try {
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = dateFormat.parse(time);
String hour = new SimpleDateFormat("HH").format(date);
count++;
// 统计不同小时的交易量和交易总金额
hourVolume.put(hour, hourVolume.getOrDefault(hour, 0.0) + tradeVolume);
hourAmount.put(hour, hourAmount.getOrDefault(hour, 0.0) + (price * tradeVolume));
} catch (Exception e) {
e.printStackTrace();
}finally {
printResults();
System.out.println("文件总数为:"+count);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 不需要发射数据到下一个Bolt,因此这个方法可以为空
}
// 新增的方法,用于打印统计结果
private void printResults() {
System.out.println("Stock Type Statistics:");
for (Map.Entry<String, Double> entry : stockTypeVolume.entrySet()) {
String stockCode = entry.getKey();
double volume = entry.getValue();
double amount = stockTypeAmount.get(stockCode);
System.out.println("Stock Code: " + stockCode + ", Volume: " + volume + ", Amount: " + amount);
}
System.out.println("Hourly Statistics:");
for (Map.Entry<String, Double> entry : hourVolume.entrySet()) {
String hour = entry.getKey();
double volume = entry.getValue();
double amount = hourAmount.get(hour);
System.out.println("Hour: " + hour + ", Volume: " + volume + ", Amount: " + amount);
}
}
}
编写Topology类:
创建一个java类,名字为StockAnalysisTopology,代码如下:
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.utils.Utils;
public class StockAnalysisTopology {
public static void main(String[] args) {
try {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("csv-reader-spout", new CSVReaderSpout());//这里是创建spout类
builder.setBolt("stock-statistics-bolt", new StockStatisticsBolt()).shuffleGrouping("csv-reader-spout");//这里是创建的bolt类,自己看着修改,前面的为名字,随便填
Config config = new Config();//参数配置
config.setDebug(true);
if (args != null && args.length > 0) {
config.setNumWorkers(3); // 设置工作进程数量
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} else {
LocalCluster cluster = null;//本地连接测试
try {
cluster = new LocalCluster();
cluster.submitTopology("stock-analysis-topology", config, builder.createTopology());
// 等待拓扑运行一段时间
Utils.sleep(60000);
}catch (Exception e) {
e.printStackTrace();
}finally {
if (cluster != null) {
cluster.shutdown();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
注意上面代码只是测试,还没有连接自己的storm。
运行StockAnalysisTopology中的main方法,可以看到成功运行:
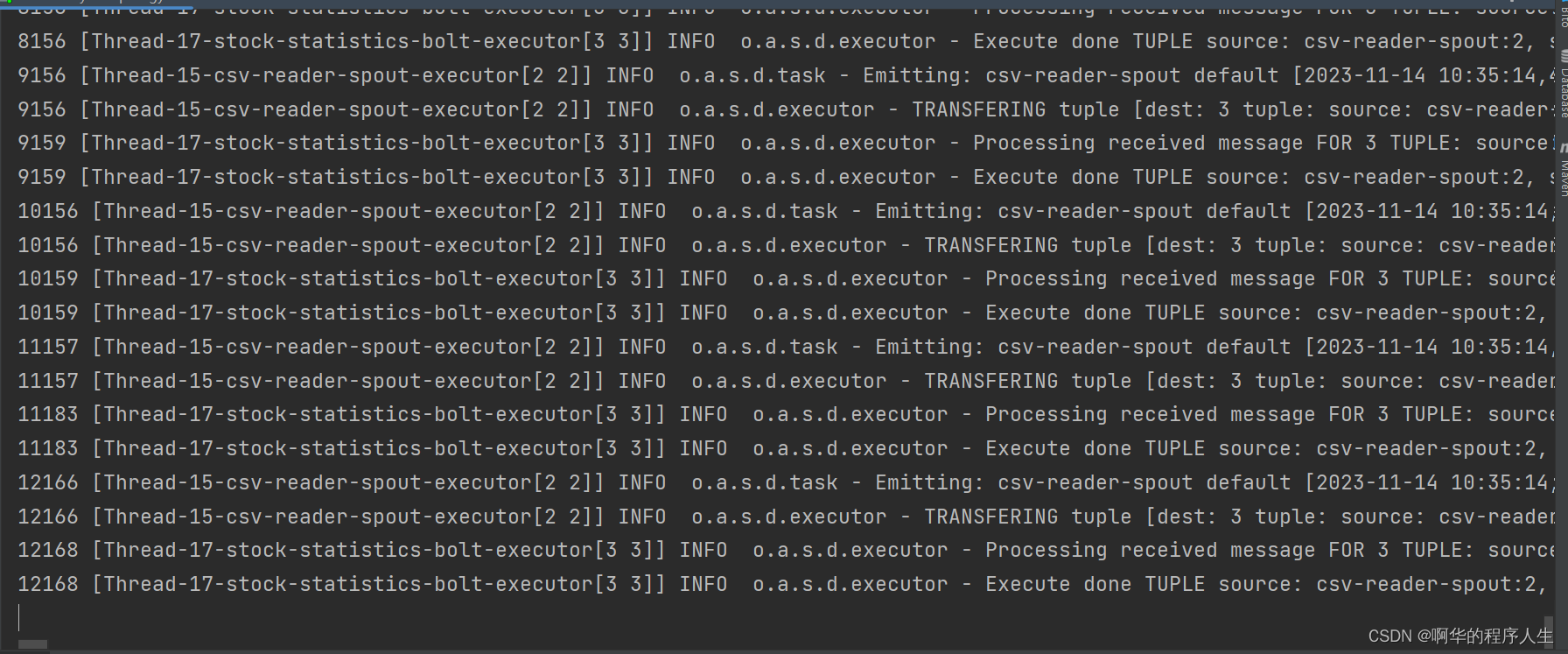
运行到一定数量数据后会报一个下面错误:
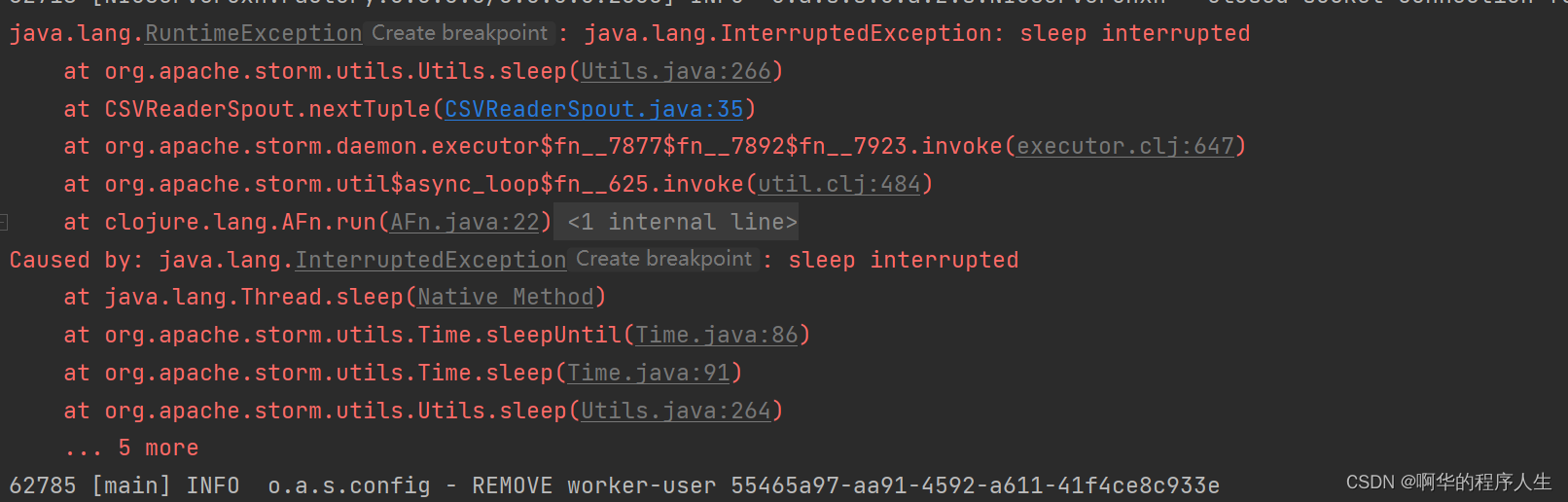
但是程序没有停止,还在运行,数据却不在读取了,如果输出sleep函数又会因为某些原因导致进程被杀死,该问题还没有解决。
三.连接storm集群
下面进行远程连接storm,先将项目打包成jar包,实际只要有spout和bolt俩个类即可。(直接打包就行)
之后修改StockAnalysisTopology代码,如下所示,看情况修改。
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.shade.com.google.common.collect.ImmutableList;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.utils.Utils;
public class StockAnalysisTopology {
public static void main(String[] args) {
String nimbusHost = "127.0.0.1"; // 修改为你的 Nimbus 服务器主机名或 IP 地址
String zookeeperHost = "127.0.0.1"; // 修改为你的 ZooKeeper 服务器主机名或 IP 地址
try {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("csv-reader-spout", new CSVReaderSpout());
builder.setBolt("stock-statistics-bolt", new StockStatisticsBolt()).shuffleGrouping("csv-reader-spout");
Config config = new Config();
config.setDebug(true);
// 设置 Nimbus 主机和 ZooKeeper 服务器
config.put(Config.NIMBUS_SEEDS, ImmutableList.of(nimbusHost));
config.put(Config.STORM_ZOOKEEPER_SERVERS, ImmutableList.of(zookeeperHost));
// 设置拓扑的总任务数(worker 数量),这里设置为 3
//config.setNumWorkers(3);
System.setProperty("storm.jar","D:\\Idea\\java项目\\xxx\\target\\xxx-1.0-SNAPSHOT.jar");//修改为自己的jar包地址
StormSubmitter.submitTopology("remote-topology", config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}
然后运行上面代码即可。
注意:在运行上面代码前需要把zookeeper的ip和storm的ip添加到hosts文件里面,如下图:
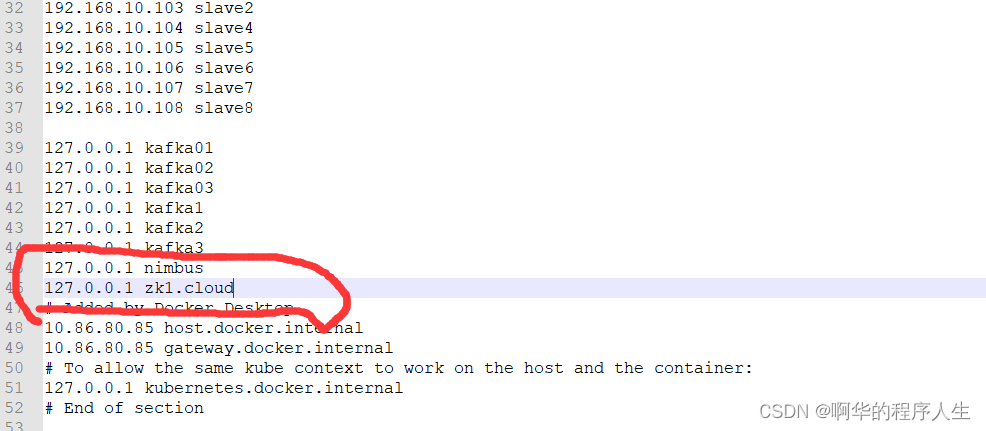
文件地址在C:\Windows\System32\drivers\etc\hosts.
之后打开storm ui可以看到Topology结构,如下图:
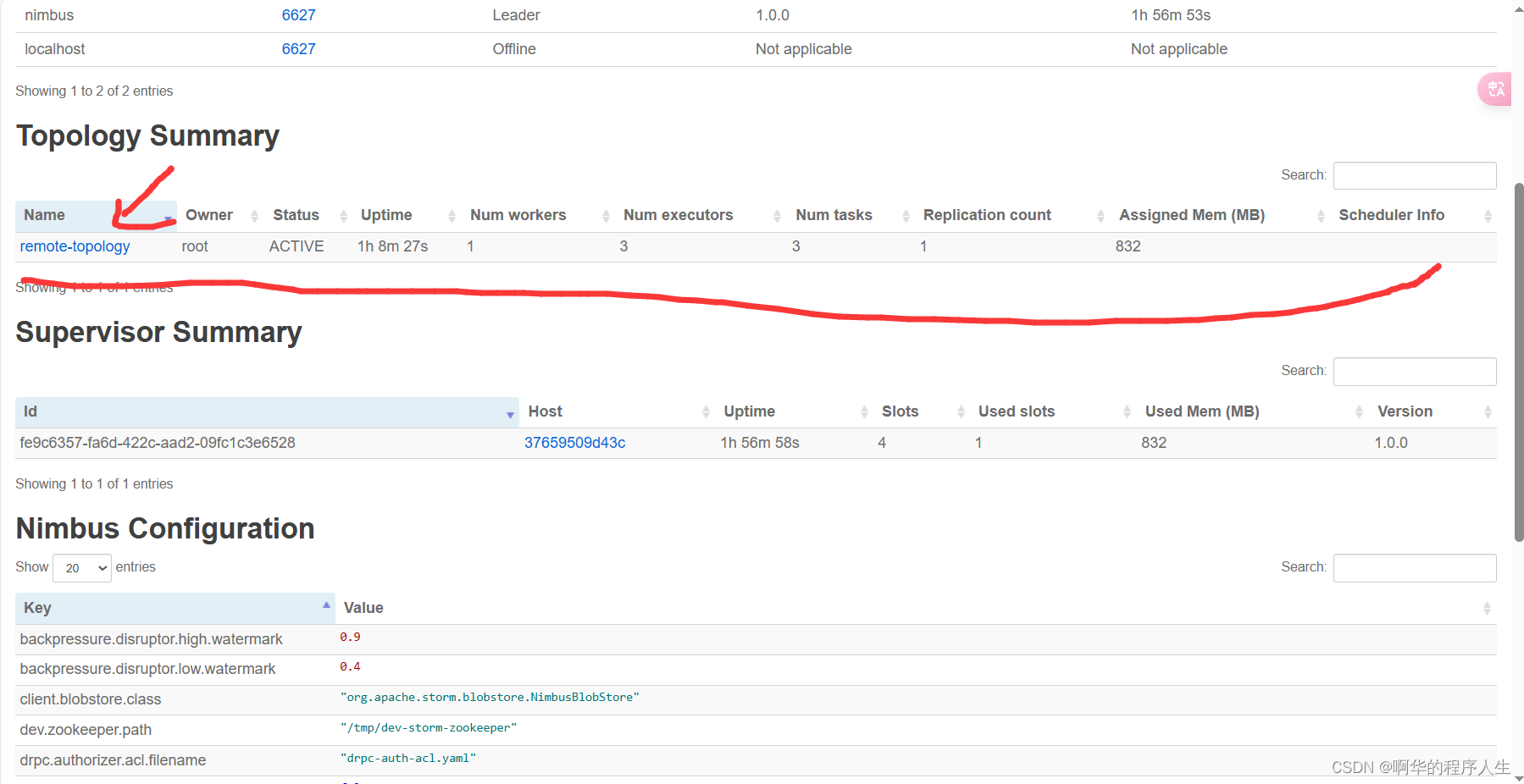
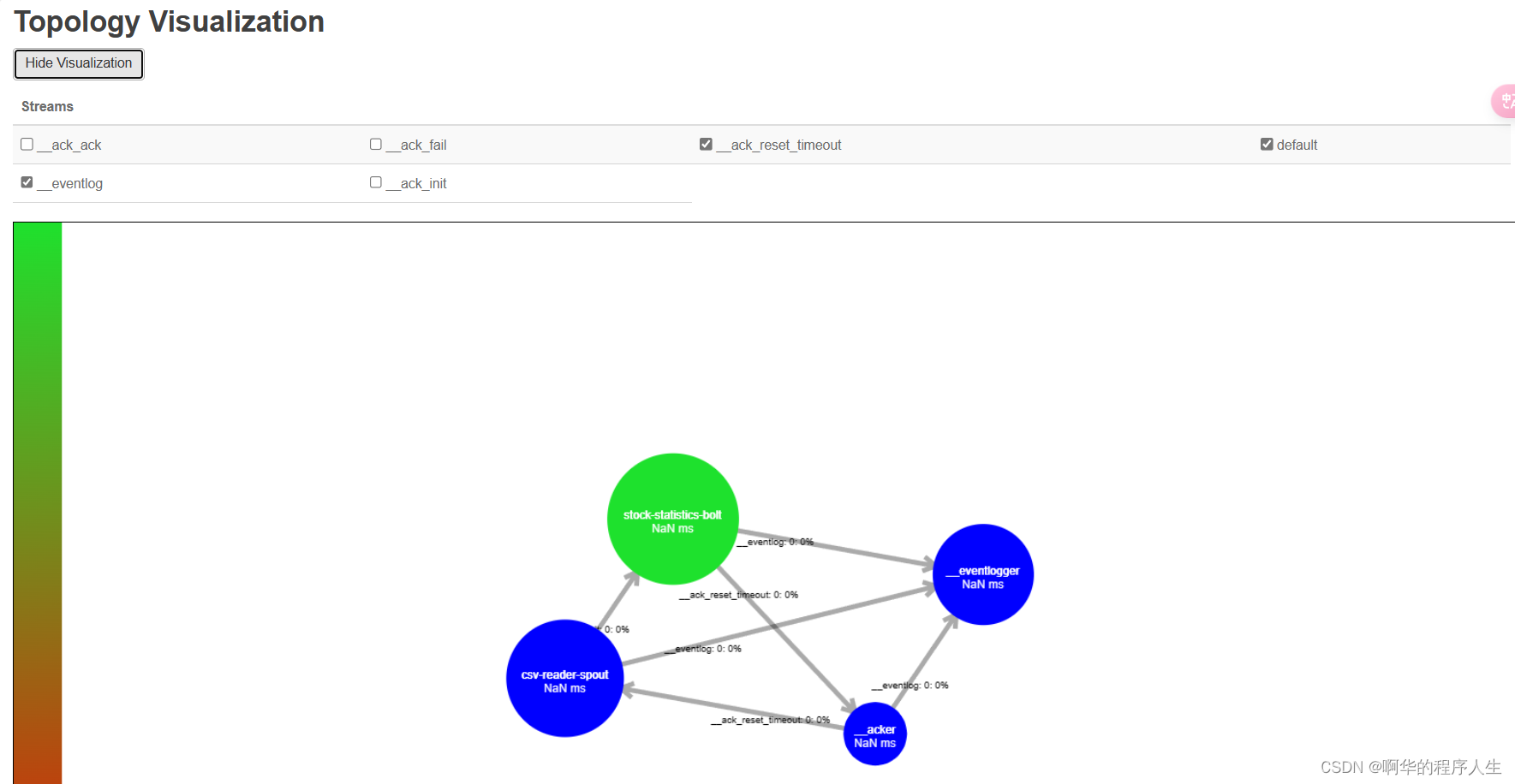
关于统计任务和调参记录表格任务因为代码还有点问题待解决,这里暂时不做讲述,后续解决会 补充。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









