






java forEach 如何跳出循环?如何使用 continue break?stream parallel效率如何?
我答: 不需要在使用forEach的时候跳出循环,可以使用stream,forEach等专门针对集合的工具来做遍历操作,完全代替关键字for,break,continue;效率见下文。
我的理由
如果你使用forEach,那你一定知道lambda表达式,如果你知道lambda表达式,那你大概率会用stream,使用stream可以不需要break和continue。
想使用break的场景
无非是一个list里面,要对id=xx的进行操作,这个时候可以用stream的filter,直接筛选出这个就可以了,如果id=xx的有多个,你只要任意一个,那么可以使用findFirst
MyObject myObject = list.stream.filter(s -> {xx}).findFirst().orElse(null);
想使用continue的场景
continue是可以通过调整逻辑代码给去掉的
if(type == 2) {
fieldValueA += 10;
continue;
} else if(type == 3) {
fieldValueA += 15;
} else {
fieldValueA = 0;
}
fieldB += 20;
// 可以替换为
if(type == 2) {
fieldValueA += 10;
} else if(type == 3) {
fieldValueA += 15;
} else {
fieldValueA = 0;
}
if(type != 2) {
fieldB += 20;
}
关于效率
在一个循环里统计三个字段的和,写成stream的话会有三个stream。stream可以把一次连续调用里的操作优化到一个循环里(这个是我看stream效率博客看的,好像是这样,嗯,大概),但是没法把分开写的三次stream优化到同一个循环里,那写三个stream的时间复杂度不就是普通的for的3倍?
试一下
@Test
public void streamTest() {
streamTestWithCycleNum(10000); // 万
streamTestWithCycleNum(100000); // 十万
streamTestWithCycleNum(1000000); // 百万
streamTestWithCycleNum(10000000); // 千万
streamTestWithCycleNum(100000000); // 亿
}
private void streamTestWithCycleNum(int cycleNum) {
System.out.println("循环次数:" + cycleNum);
HpBillAllocation hpBillAllocation = new HpBillAllocation();
hpBillAllocation.setOrderMoney(BigDecimal.valueOf(156));
hpBillAllocation.setChargeAmount(BigDecimal.valueOf(415));
hpBillAllocation.setPaidAmount(BigDecimal.valueOf(786));
hpBillAllocation.setActivityAmount(BigDecimal.valueOf(119));
List<HpBillAllocation> hpBillAllocations = new ArrayList<>();
for (int i = 0; i < cycleNum; i++) {
hpBillAllocations.add(hpBillAllocation);
}
long forBeginTime = System.nanoTime();
BigDecimal totalAmount = new BigDecimal(0);
BigDecimal successAmount = new BigDecimal(0);
BigDecimal refundAmount = new BigDecimal(0);
int successCount = 0;
int refundCount = 0;
for (HpBillAllocation billAllocation : hpBillAllocations) {
BigDecimal chMoney = billAllocation.getOrderMoney();
totalAmount = totalAmount.add(chMoney);
if (chMoney.compareTo(BigDecimal.ZERO) >= 0) {
hpBillAllocation.setChOrderType(WXPayConstants.CH_ORDER_TYPE_PAY);
successAmount = successAmount.add(chMoney);
successCount += 1;
} else {
hpBillAllocation.setChOrderType(WXPayConstants.CH_ORDER_TYPE_REFUND);
refundAmount = refundAmount.add(chMoney);
refundCount += 1;
}
}
long forEndTime = System.nanoTime();
System.out.println("forTime: " + (forEndTime - forBeginTime)/1000000 + "ms");
long streamBeginTime = System.nanoTime();
HpBillAllocation hpBillAllocation1 = hpBillAllocations.stream().findFirst().orElse(null);
totalAmount = BigDecimal.valueOf(hpBillAllocations.stream().mapToLong(s -> s.getOrderMoney().longValue()).sum());
successAmount = BigDecimal.valueOf(hpBillAllocations.stream().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) >= 0).mapToLong(s -> s.getOrderMoney().longValue()).sum());
successCount = (int)hpBillAllocations.stream().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) >= 0).count();
refundAmount = BigDecimal.valueOf(hpBillAllocations.stream().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) < 0).mapToLong(s -> s.getOrderMoney().longValue()).sum());
successCount = (int)hpBillAllocations.stream().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) < 0).count();
long streamEndTime = System.nanoTime();
System.out.println("streamTime: " + (streamEndTime - streamBeginTime)/1000000 + "ms");
long streamParallelBeginTime = System.nanoTime();
totalAmount = BigDecimal.valueOf(hpBillAllocations.stream().parallel().mapToLong(s -> s.getOrderMoney().longValue()).sum());
successAmount = BigDecimal.valueOf(hpBillAllocations.stream().parallel().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) >= 0).mapToLong(s -> s.getOrderMoney().longValue()).sum());
successCount = (int)hpBillAllocations.stream().parallel().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) >= 0).count();
refundAmount = BigDecimal.valueOf(hpBillAllocations.stream().parallel().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) < 0).mapToLong(s -> s.getOrderMoney().longValue()).sum());
successCount = (int)hpBillAllocations.stream().parallel().filter(s -> s.getOrderMoney().compareTo(BigDecimal.ZERO) < 0).count();
long streamParallelEndTime = System.nanoTime();
System.out.println("streamParallelTime: " + (streamParallelEndTime - streamParallelBeginTime)/1000000 + "ms\n");
}
输出
循环次数:10000
forTime: 1ms
streamTime: 28ms
streamParallelTime: 7ms
循环次数:100000
forTime: 7ms
streamTime: 4ms
streamParallelTime: 15ms
循环次数:1000000
forTime: 24ms
streamTime: 28ms
streamParallelTime: 3ms
循环次数:10000000
forTime: 257ms
streamTime: 250ms
streamParallelTime: 32ms
循环次数:100000000
forTime: 9625ms
streamTime: 2428ms
streamParallelTime: 313ms
虽然不知道原理,但是可以看到,数据量越大,for效率越赶不上stream,即使是没有使用parallel的情况下。这个情况跟cpu效率有关,我对比了别人的博客,cpu越差,用stream效率越早反超
关于stream的一些技巧
可能会觉得stream api有点多,自己要学习有点麻烦,其实根本不需要,或者说只用学习一点点。
2023了,ai在语言方面的能力可能会超乎一些人的想象,有梯子,可以直接使用免费的new bing,
没有梯子也没关系,我们可以使用百度ai,不过就我使用经验来看百度的生成的东西有时候是错的,没new bing好用,不过大部分时间也够用了,出来的代码总归要自己检查一下的,直接上图。
new bing
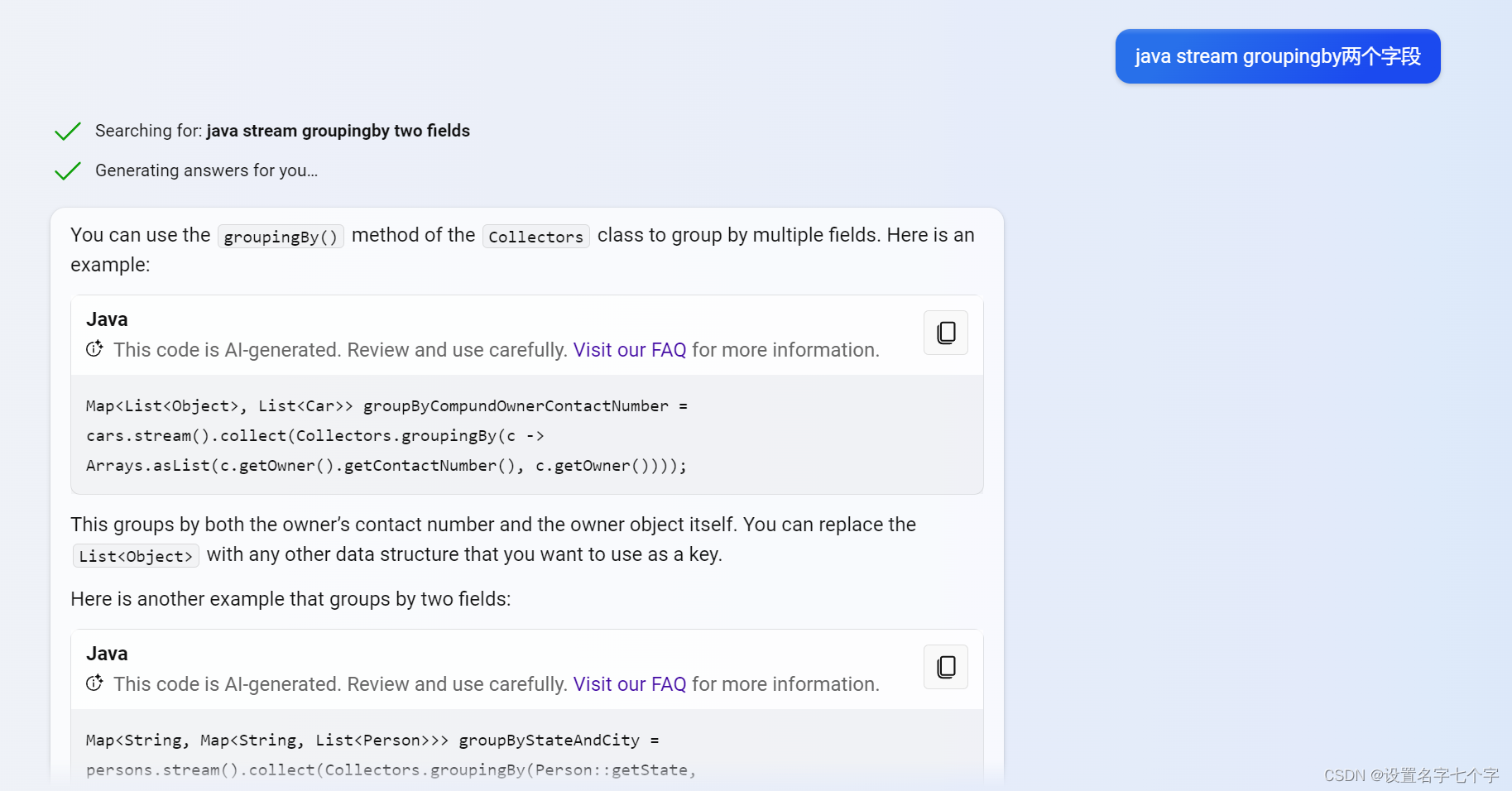

百度ai
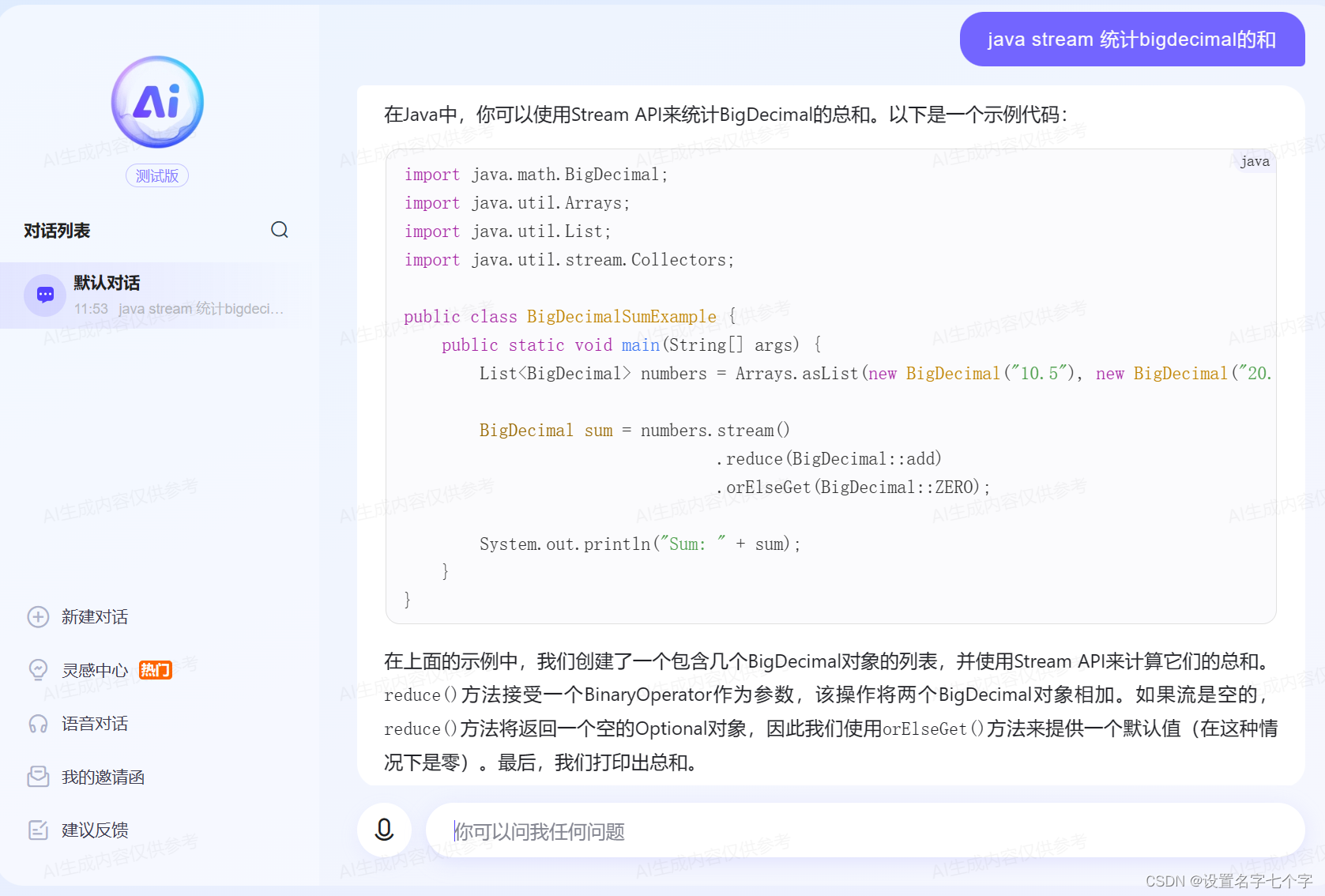
对于统计bigdecimal的和,bing的BigDecimal:ZERO在reduce方法里的,针对空值的时候就取0,百度这个丢到后面的在编译器里报错了,即使是对的也没有bing的写法优雅。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









