




 本文介绍如何使用Hadoop进行单词计数的实现过程,包括搭建Maven项目、编写MapReduce程序,并解决了一些常见的配置问题。
本文介绍如何使用Hadoop进行单词计数的实现过程,包括搭建Maven项目、编写MapReduce程序,并解决了一些常见的配置问题。
首先通过idea创建一个maven文件
导入pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.yw</groupId>
<artifactId>cn.yw</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
</project>
版本号不需要和自己的hadoop版本一致
然后做个最简单的单词计数
然后开始写map层
package cn.yw;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCount extends Mapper<LongWritable, Text,Text, IntWritable>{
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
//设置分隔符
String[] words = value.toString().split("\t");
//每个字存入
for(String word : words){
context.write(new Text(word),new IntWritable(1));
}
}
}
导入的包要注意都是hadoop的包
然后写Reduce层
package cn.yw;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordREducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int Count = 0;
Iterator<IntWritable> iterator = values.iterator();
//迭代器计数
while (iterator.hasNext()) {
IntWritable value = iterator.next();
Count += value.get();
}
context.write(key, new IntWritable());
}
}
最后写main层整合map和reduce
package cn.yw;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import javax.security.auth.login.AppConfigurationEntry;
import java.io.FileInputStream;
import java.net.URI;
public class Wc {
public static void main(String[] args) throws Exception{
//hadoop用户不然不能拥有写进去的权限
System.setProperty("HADOOP_USER_NAME","hadoop");
//hdfs的地址
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://106.15.179.224:9000");
configuration.set("dfs.client.use.datanode.hostname", "true");
//输入输出的文件m目录
String input="/input/text.txt";
String output="/output/";
// FileUtil.deleteDir(output);
Job job = Job.getInstance(configuration);
//主函数位置
job.setJarByClass(Wc.class);
//map函数位置
job.setMapperClass(WordCount.class);
job.setReducerClass(WordREducer.class);
//map设置出来的
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reduce设置出来的
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//删除output文件夹
FileSystem fileSystem = FileSystem.get(new URI("hdfs://106.15.179.224:9000"),configuration,"hadoop");
Path outputPath = new Path(output);
if(fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath,true);
}
FileInputFormat.setInputPaths(job,new Path(input));
FileOutputFormat.setOutputPath(job, outputPath);
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : -1);
}
}
遇到的坑如下
首先9000端口访问不了
在服务器的host文件下配置0.0.0.0 允许远程访问
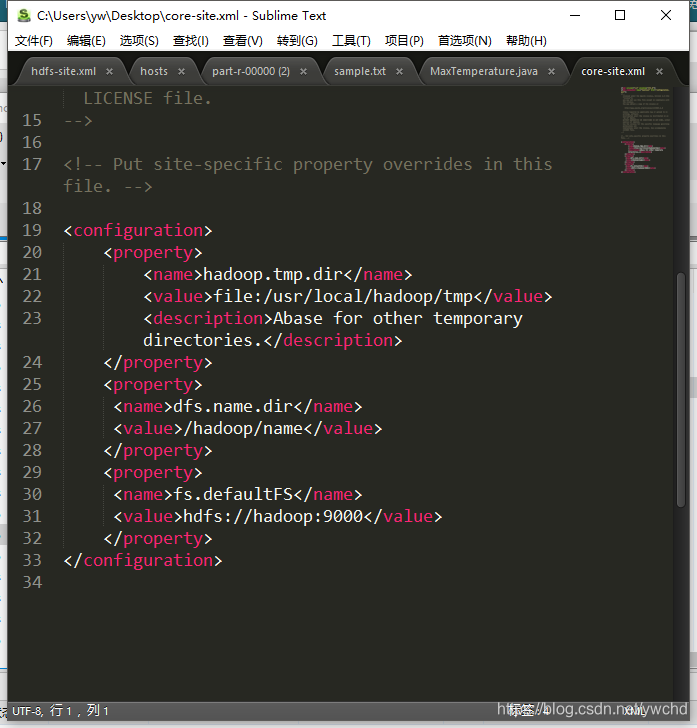
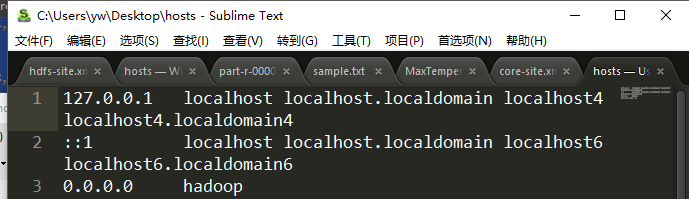
然后还要在自己电脑上下载个hadoop和配置自己的本机host 配置主机名对应服务器的ip这个超级重要被坑了一天

















 3008
3008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









