




 本文详细介绍了如何在Python中安装和使用Scrapy框架创建一个爬虫,抓取豆瓣电影Top250的数据,包括设置初始URL、解析响应、存储数据至Excel。作者还给出了items和setting的配置示例。
本文详细介绍了如何在Python中安装和使用Scrapy框架创建一个爬虫,抓取豆瓣电影Top250的数据,包括设置初始URL、解析响应、存储数据至Excel。作者还给出了items和setting的配置示例。
目录
第一步:了解并会安装scrapy框架
第二步:创建一个scrapy爬虫
第三步:在pycharm中打开scrapy文件
第四步:将我的配置文件中的内容复制到自己的文件中
第一步什么是scrapy框架
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
第二步需要先安装scrapy
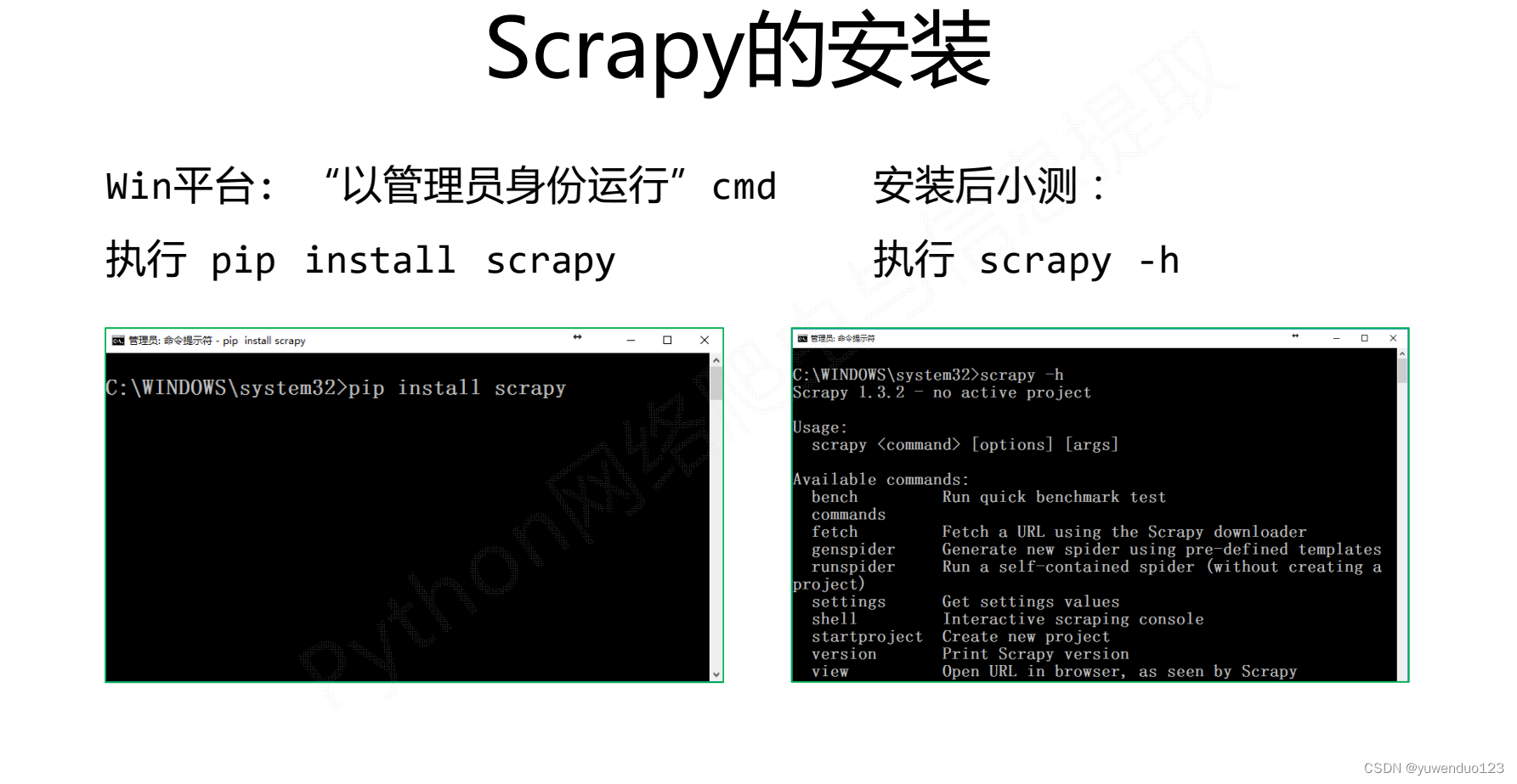
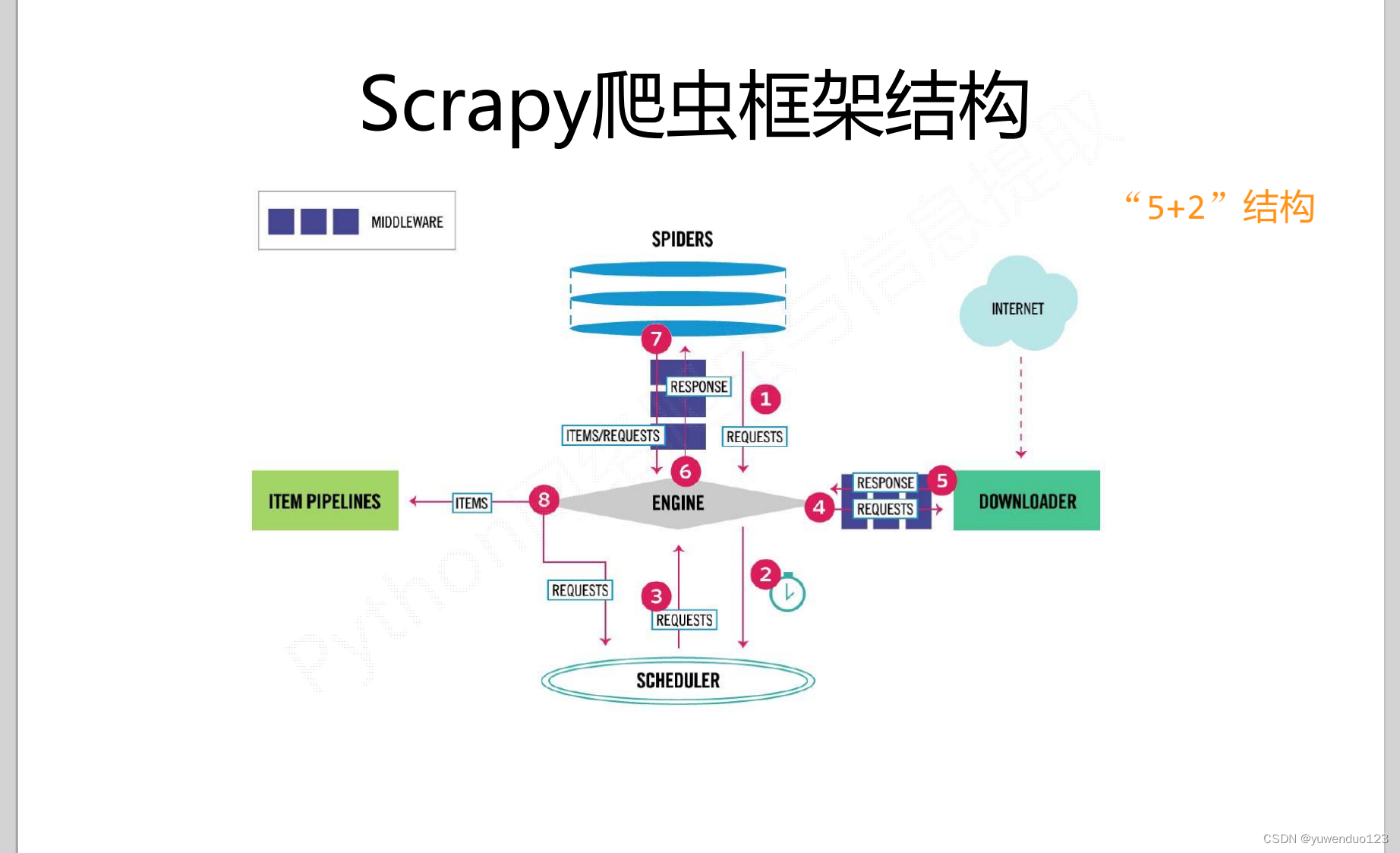
scrapy框架的结构图如下:
在命令行中输入下面内容:

然后如下图

最后建成一个scrapy框架
在pycharm中打开本项目内容
然后点开spiders中的douban.py文件进行如下编辑内容:
import scrapy
from scrapy import Selector, Request
from ..items import MovieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
# start_urls = ['http://movie.douban.com/top250']
def start_requests(self):
for page in range(10):
yield Request(url=f'http://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response, **kwargs):
sel = Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')
for list_item in list_items:
movie_item = MovieItem()
movie_item['title'] = list_item.css('span.title::text').extract_first()
movie_item['rank'] = list_item.css('span.rating_num::text').extract_first()
movie_item['subject'] = list_item.css('span.inq::text').extract_first()
yield movie_item
# href_list = sel.css('div.paginator > a::attr(href)')
# for href in href_list:
# url = response.urljoin(href.extract())
# yield Request(url=url)
即可获取豆瓣数据然后还有items和setting的配置如下:
items.py文件
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
# 爬虫获取到的数据需要组装成Item对象
class MovieItem(scrapy.Item):
title = scrapy.Field()
rank = scrapy.Field()
subject = scrapy.Field()
setting.py文件
# Scrapy settings for spider2107 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "spider2107"
SPIDER_MODULES = ["spider2107.spiders"]
NEWSPIDER_MODULE = "spider2107.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 2
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
RANDOMIZE_DOWNLOAD_DELAY = True
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "spider2107.middlewares.Spider2107SpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# "spider2107.middlewares.Spider2107DownloaderMiddleware": 543,
# }
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
"spider2107.pipelines.ExcelPipeline": 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
还有pipelines.py的内容如下
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import openpyxl
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ExcelPipeline:
def __init__(self):
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
self.ws.title = 'Top250'
self.ws.append(('标题','评分','主题'))
def open_spider(self,spider):
pass
def close_spider(self,spider):
self.wb.save('电影数据.xlsx')
def process_item(self, item, spider):
title = item.get('title', '')
rank = item.get('rank', '')
subject = item.get('subject', '')
self.ws.append((title,rank,subject))
return item
对于该文件配置是对于将获取的信息导入excel起之重要的作用,想要将获取的数据文件导成什么文件就对此文件进行编辑内容就可以。
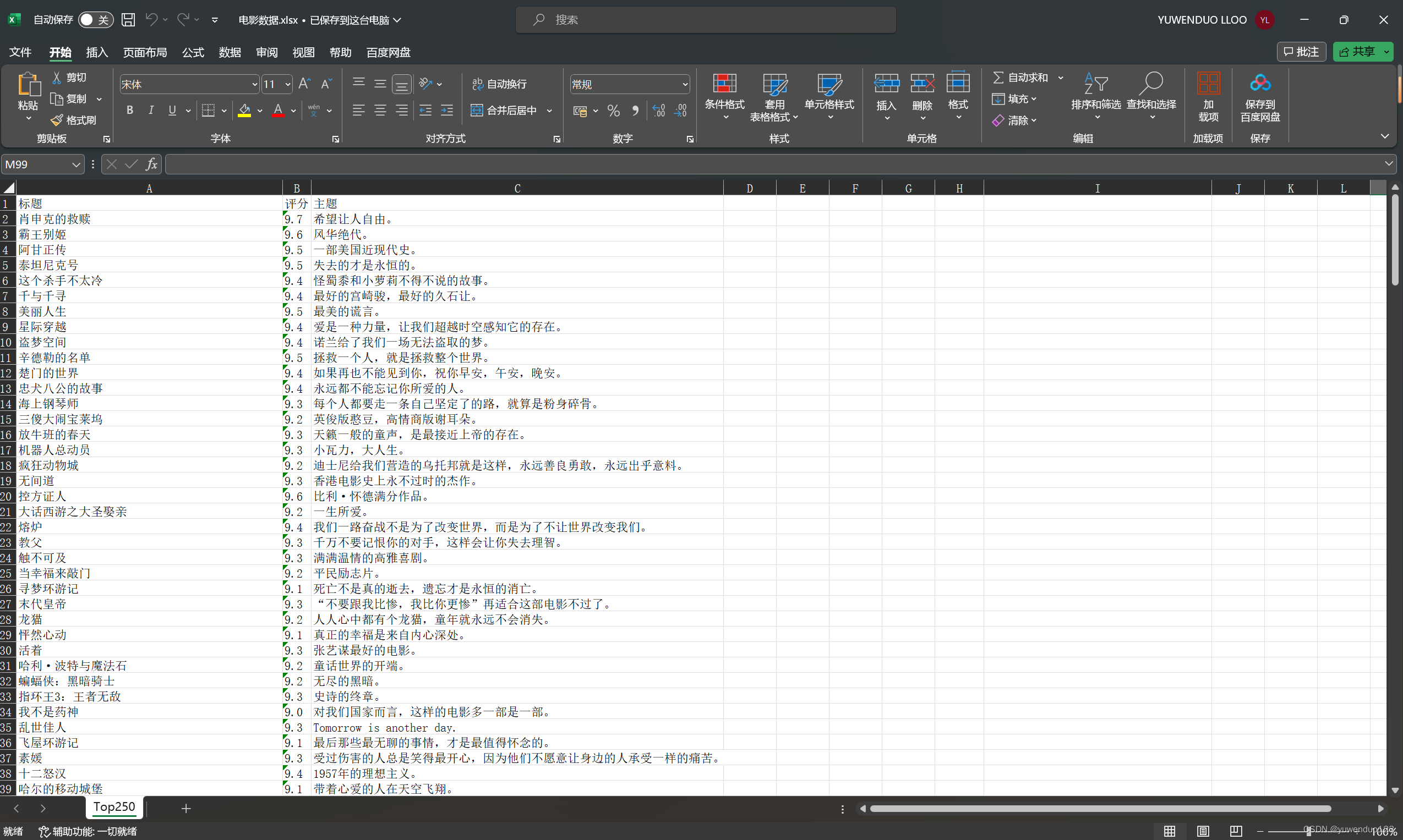
最后运行结果获取的excel文件如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









