






 本文详细介绍了Redis中的数据类型如sortedset和压缩列表,以及跳表的高效查找特性。讨论了缓存策略与数据一致性问题,包括脏数据处理、锁机制、主从一致性与哨兵机制,以及脑裂解决方案。强调了Redis在实际应用中的数据一致性挑战和可能的优化策略。
本文详细介绍了Redis中的数据类型如sortedset和压缩列表,以及跳表的高效查找特性。讨论了缓存策略与数据一致性问题,包括脏数据处理、锁机制、主从一致性与哨兵机制,以及脑裂解决方案。强调了Redis在实际应用中的数据一致性挑战和可能的优化策略。
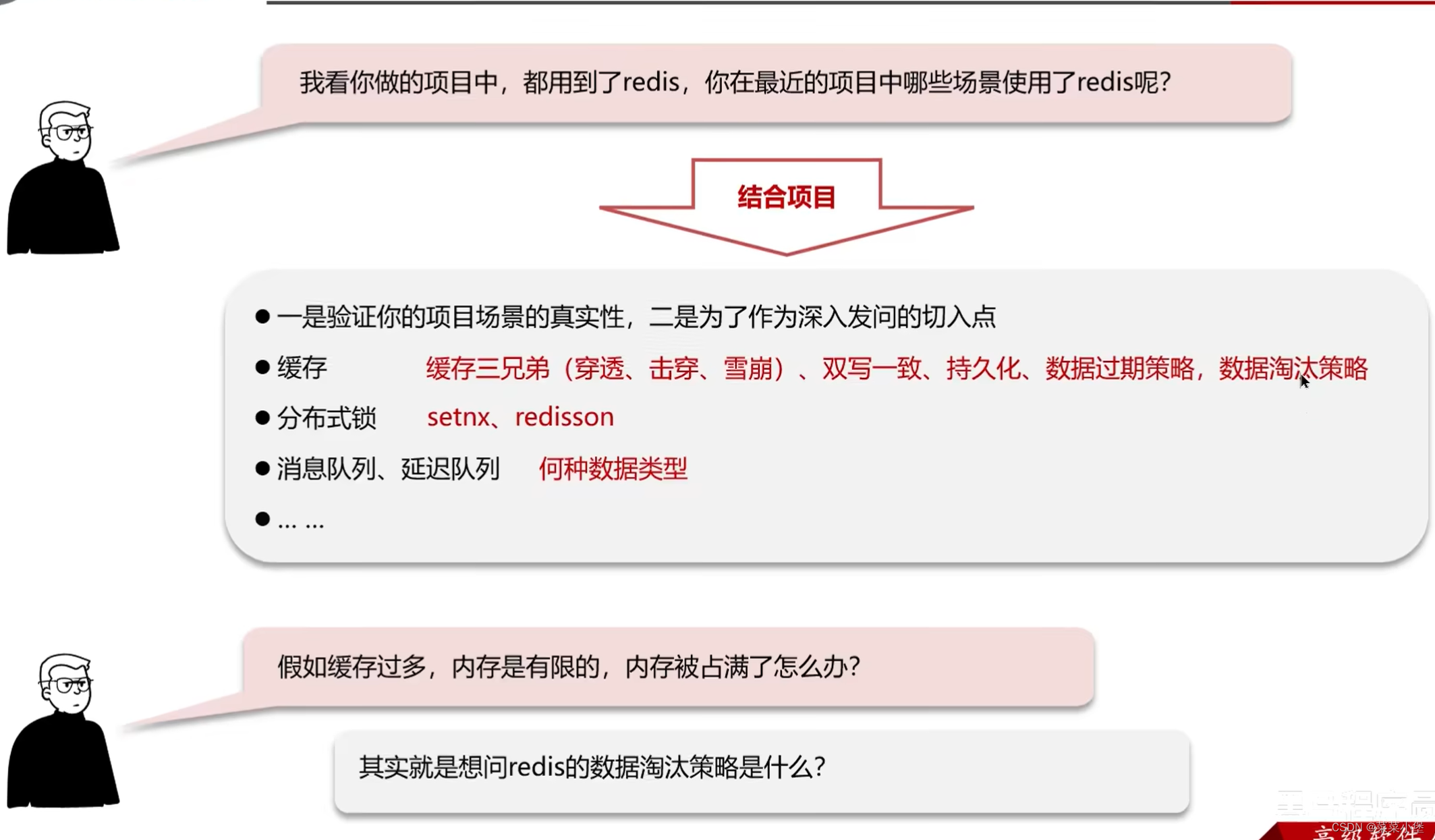
Redis八股
redis数据类型和底层数据结构
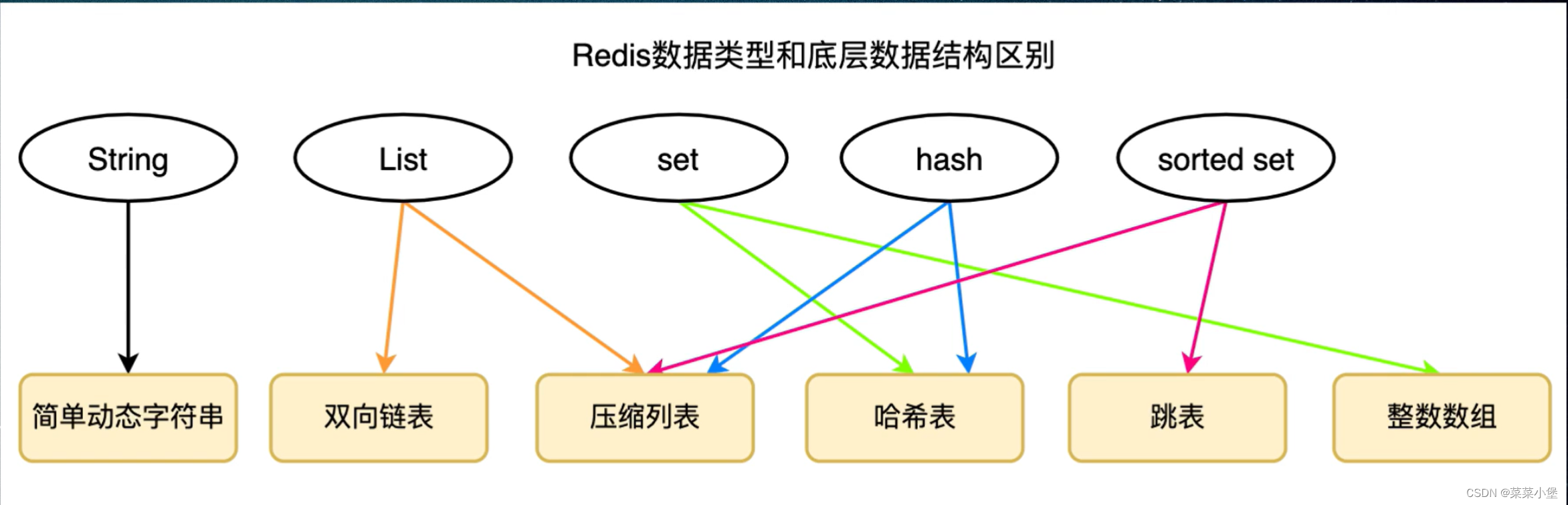
sorted set
压缩列表

方便头尾开始的查找
转换

跳表
跳表在链表的基础上加上了多级索引

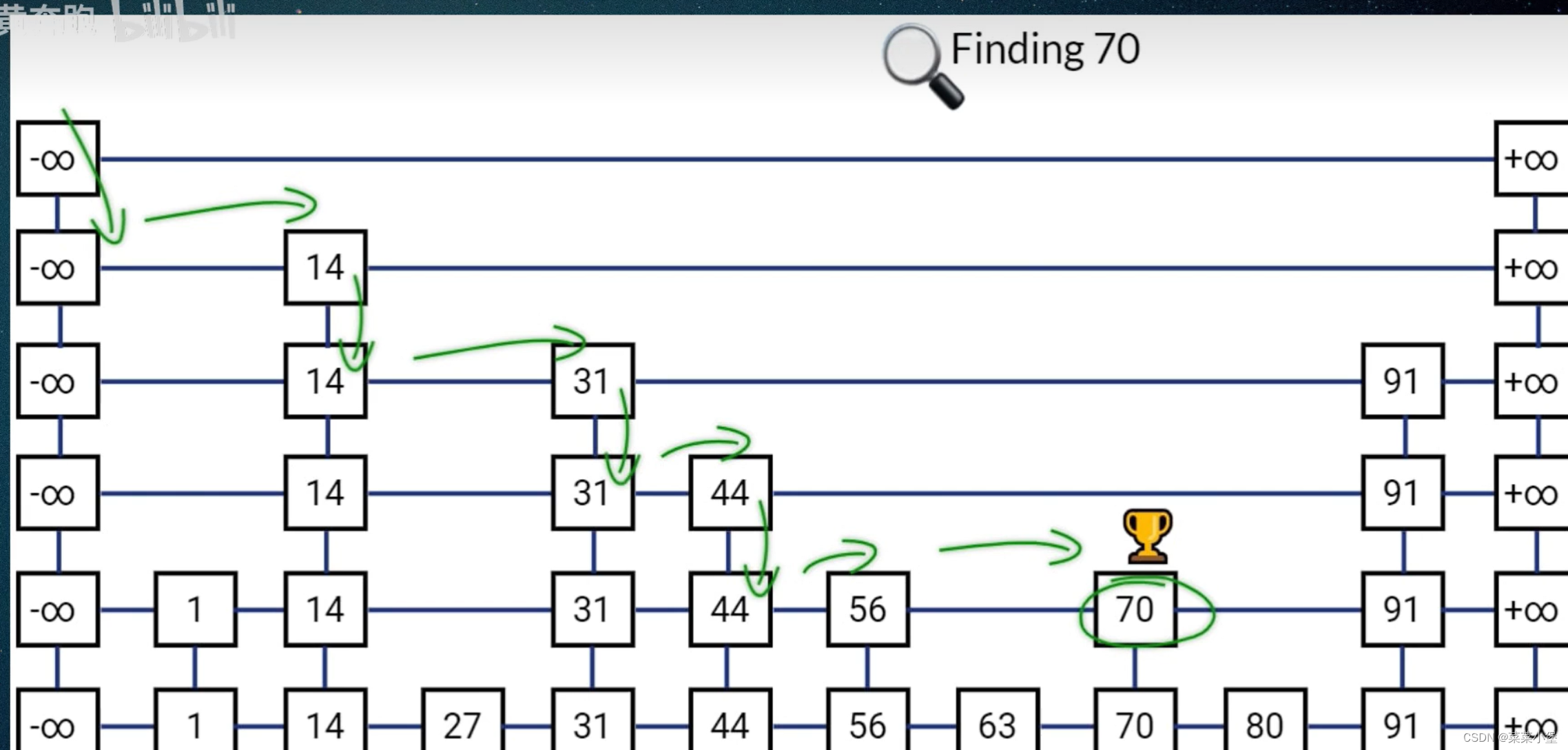
删除插入元素都是logn,查找也是logn
同时跳表的范围查找要优于红黑树
同时实现要简单一点。
跳表插入值的时候确定层数,是通过随机值确定的即(1/2)插入两层,1/4插入3层·····
层数增高也是通过此概率来进行,而且十分合理,因为一个区间内的数大量增多的时候,那很有可能就会在这个区间内的数来进行层数的增加,方便密集查找,
跳表的层数是不做限制的,具体可以参考
跳表随机化
跳表讲解

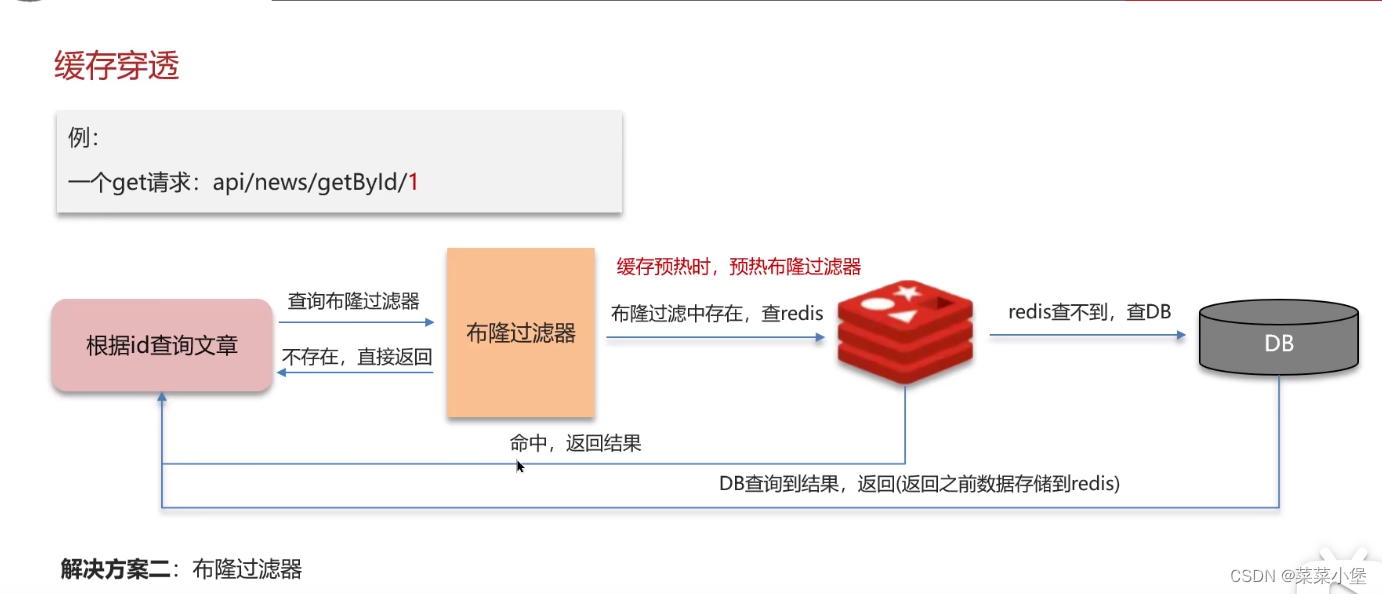

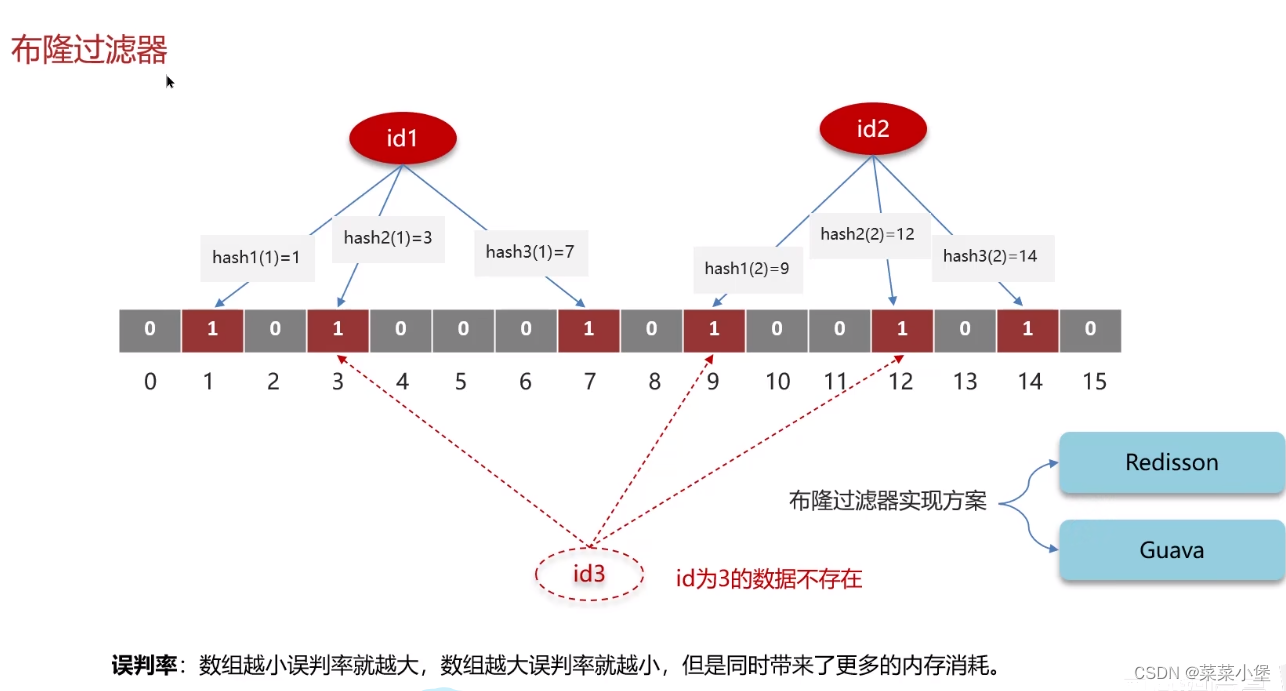
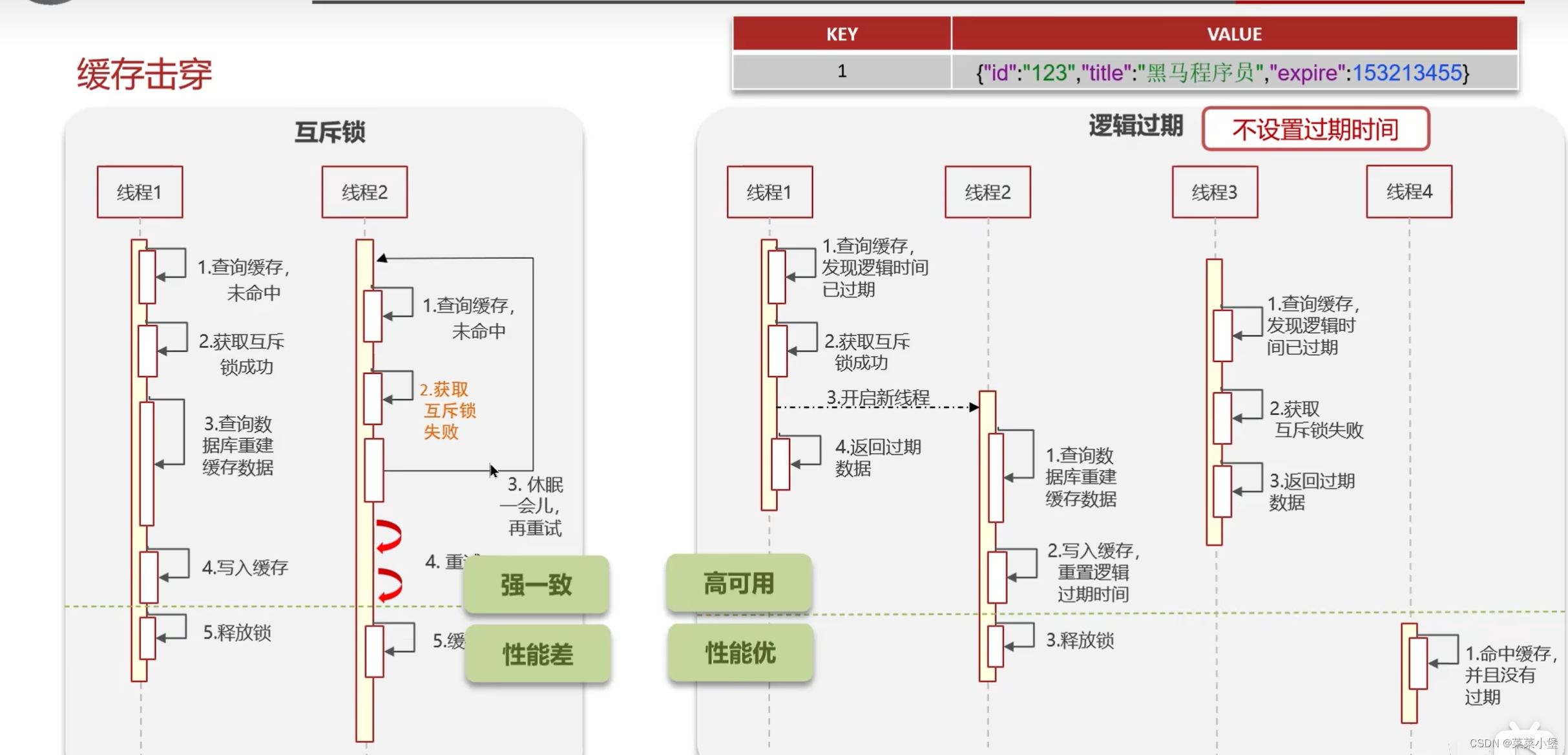



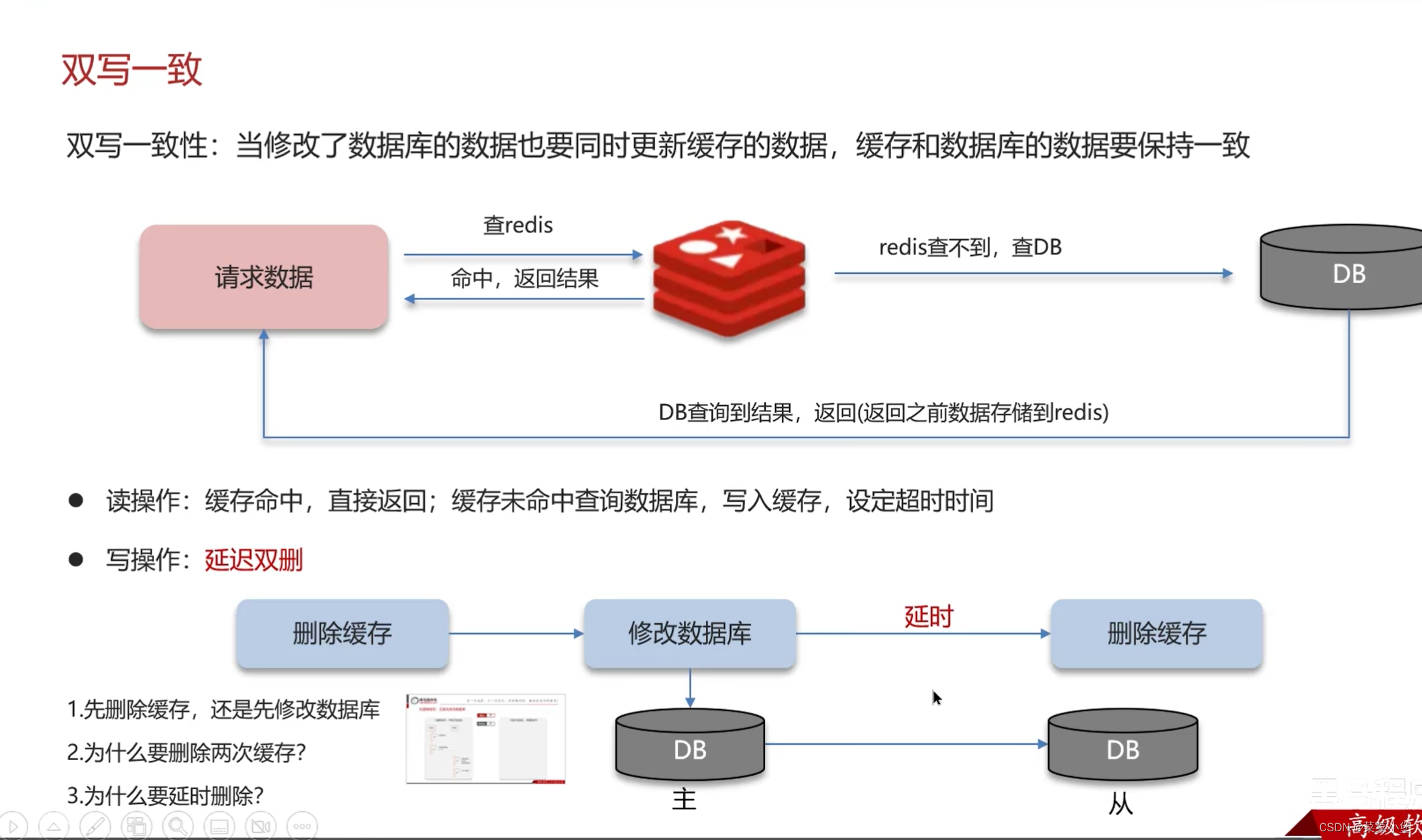
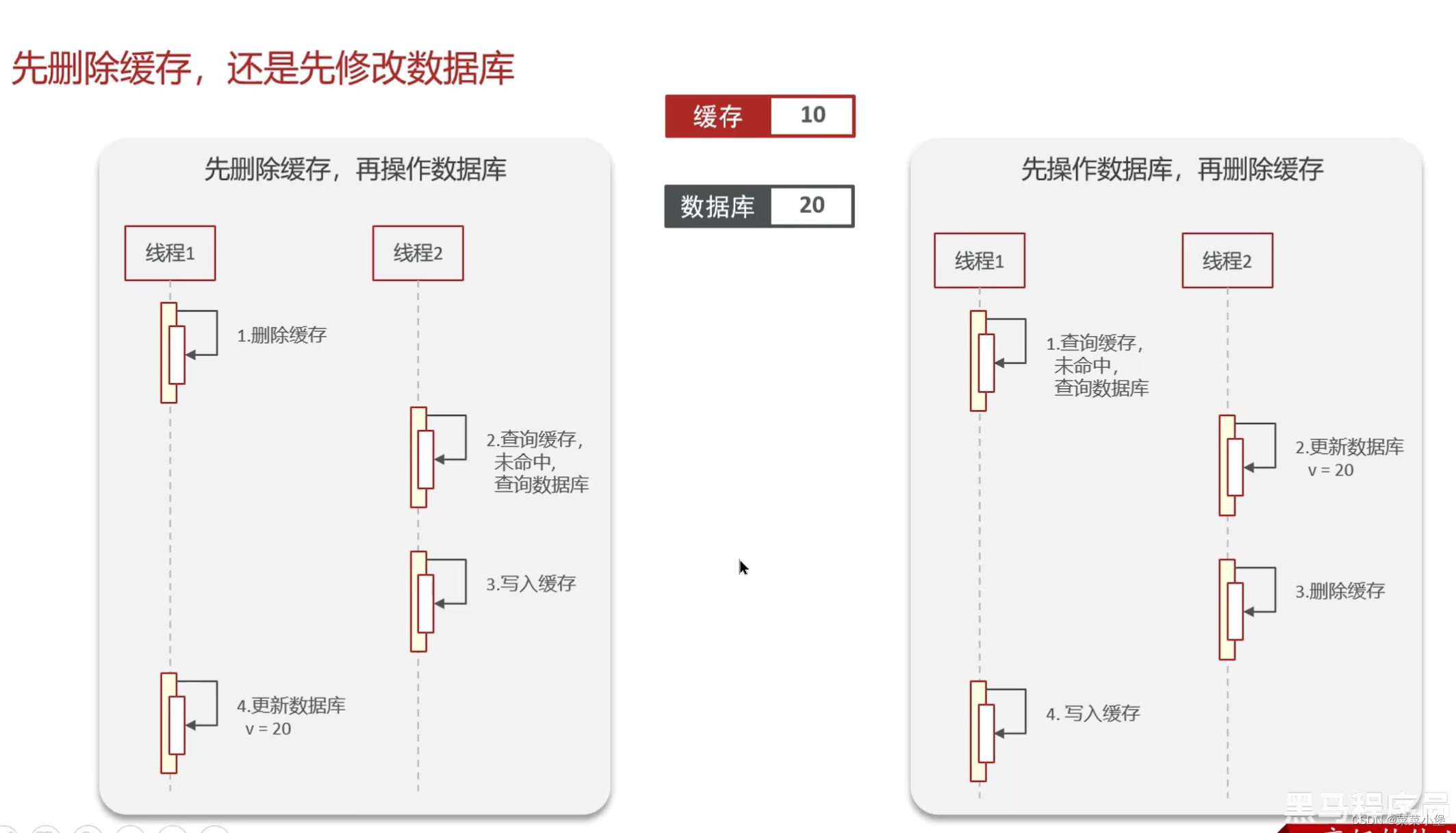
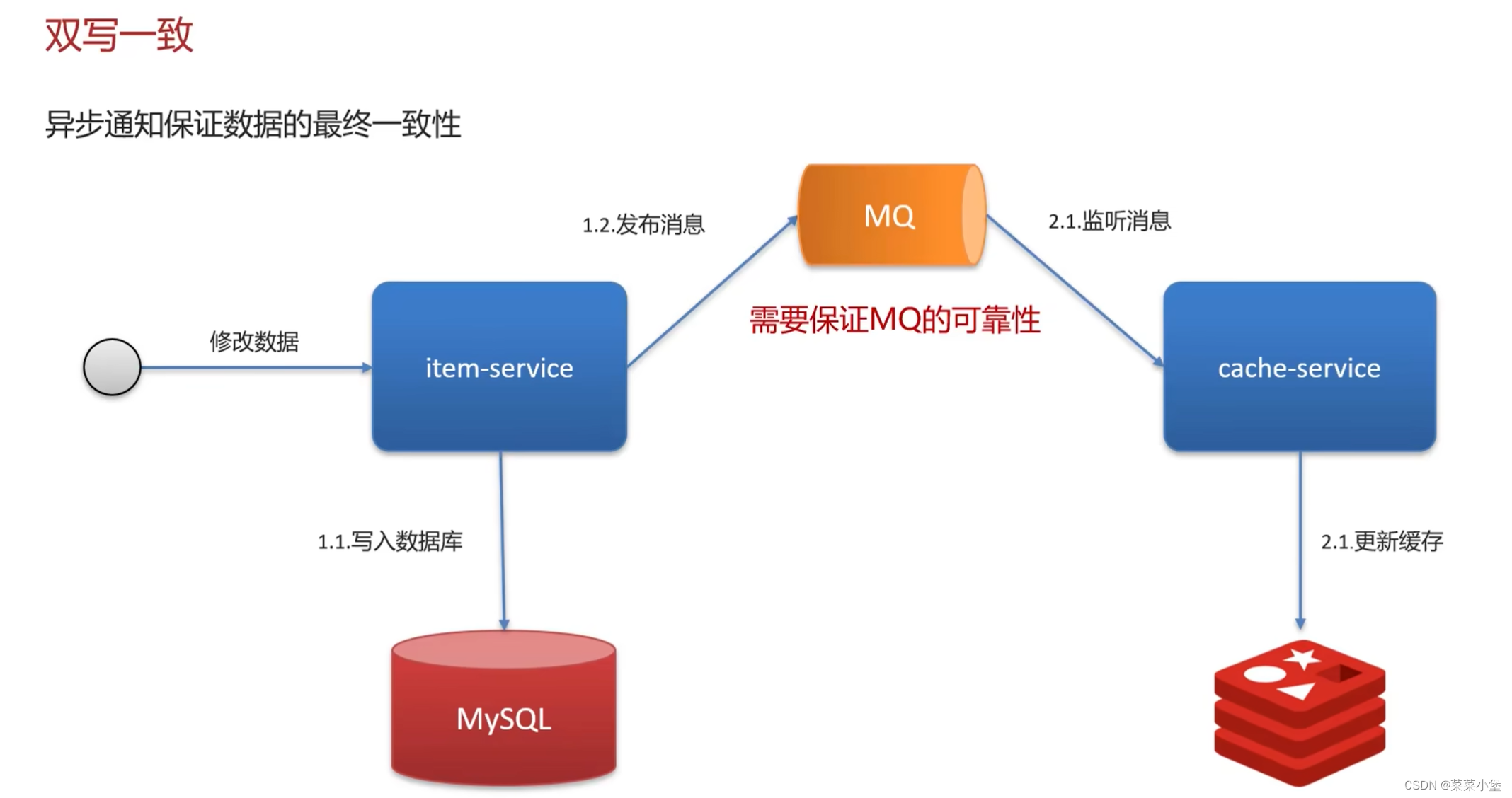
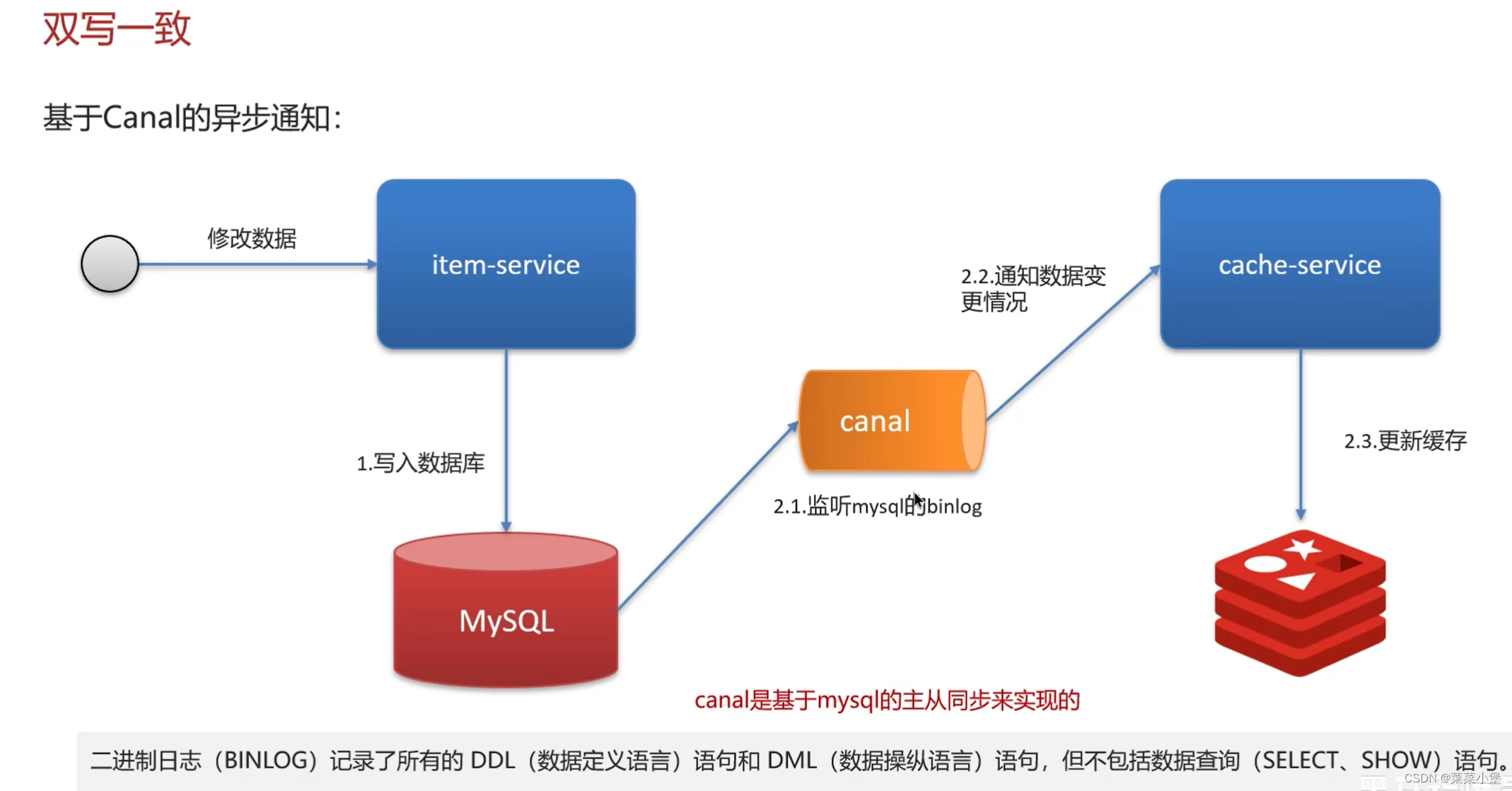
上两种都有可能导致脏数据
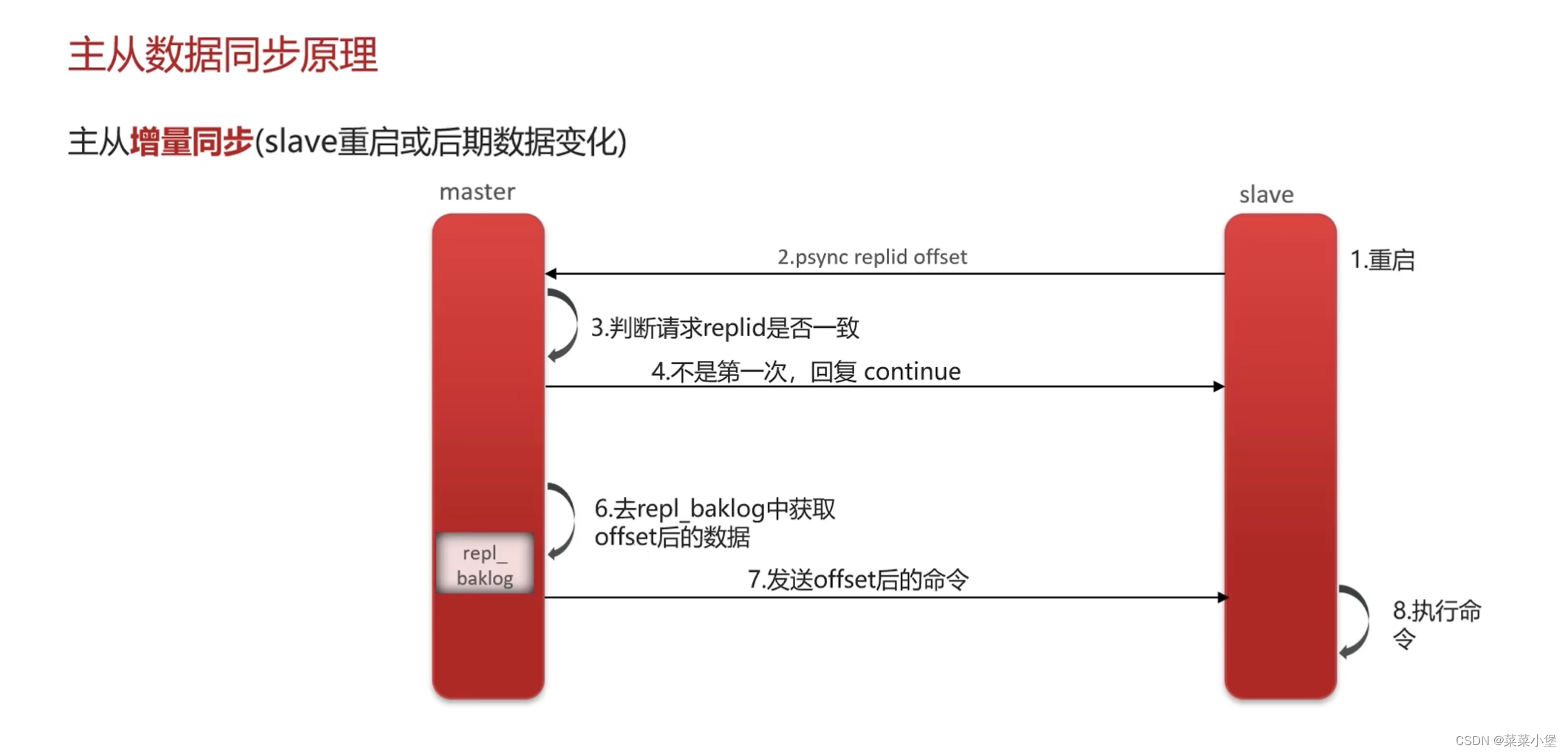
所以使用两次删除缓存的技术,延时是因为数据库有主从问题需要更新,无法达到完全的强一致性,只能达到控制一致性。
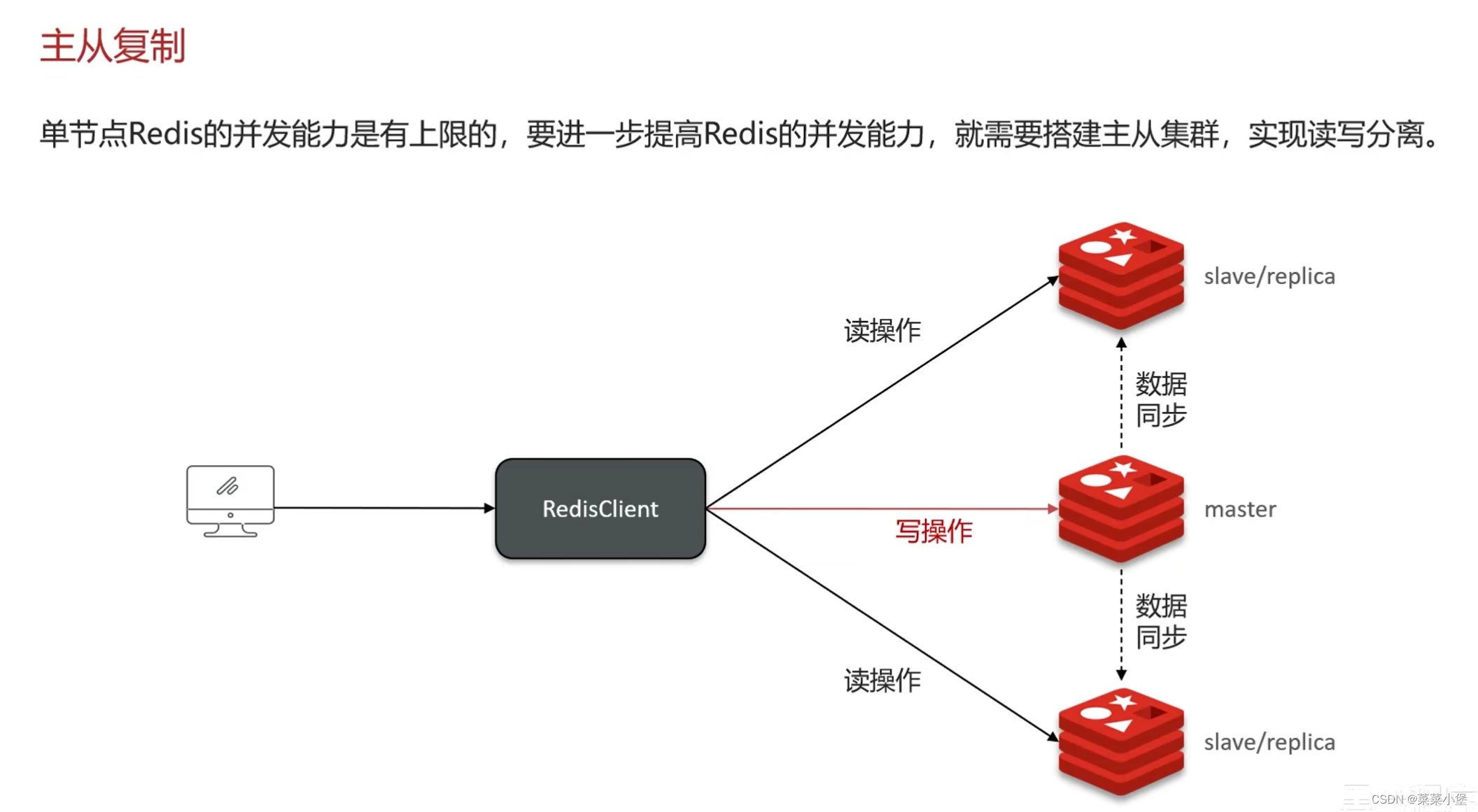
一般放入缓存中的数据都是读多写少的数据
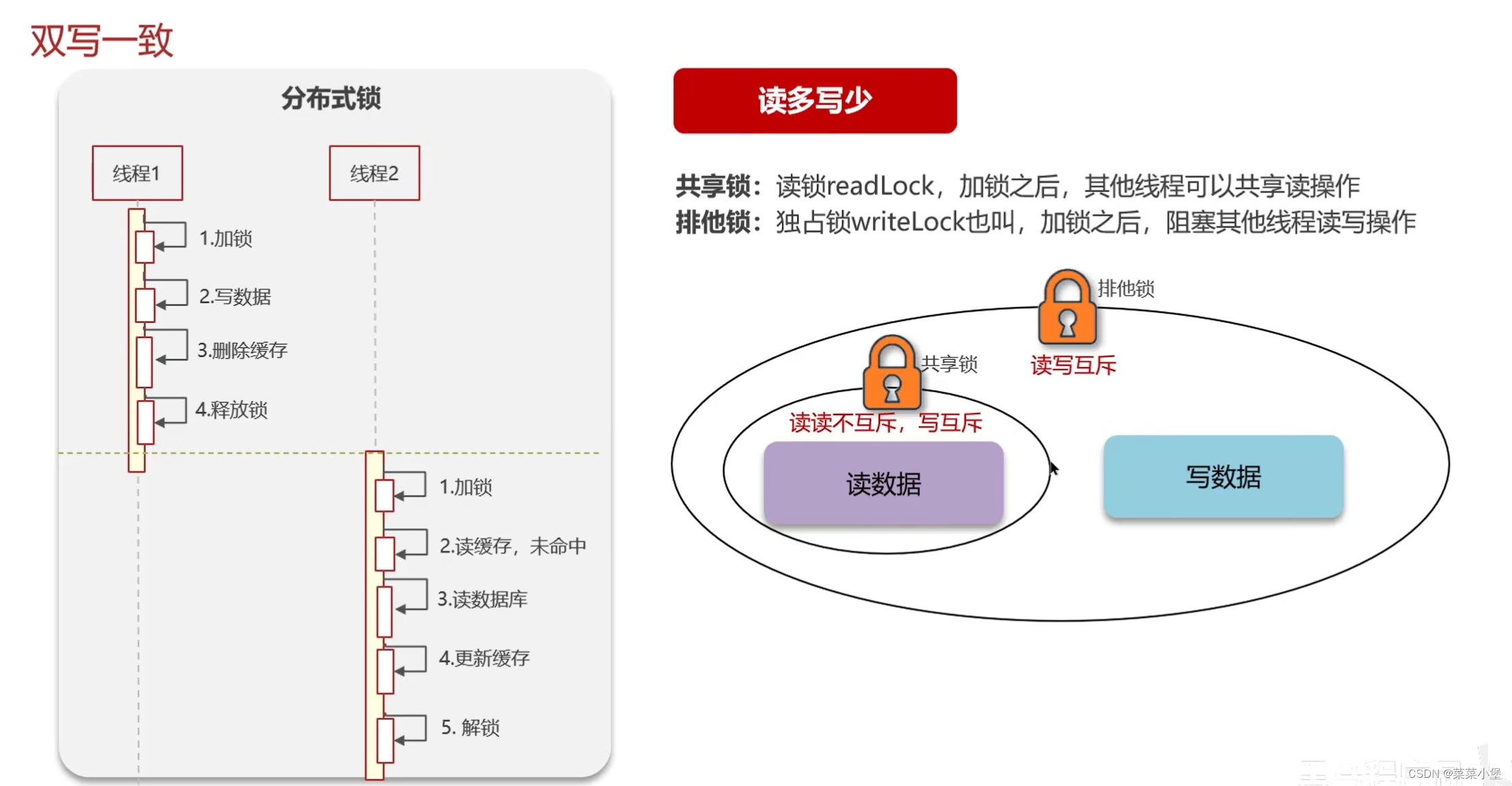
业务逻辑代码👇
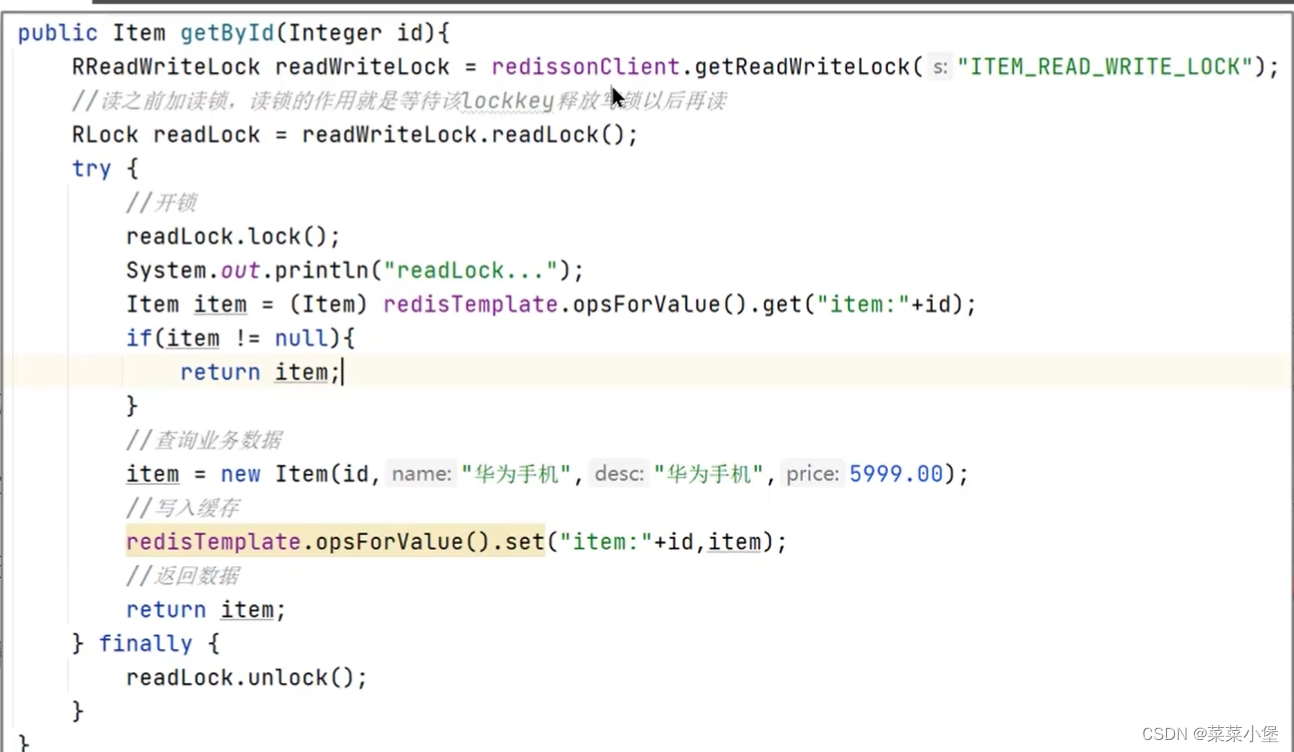
写锁👇
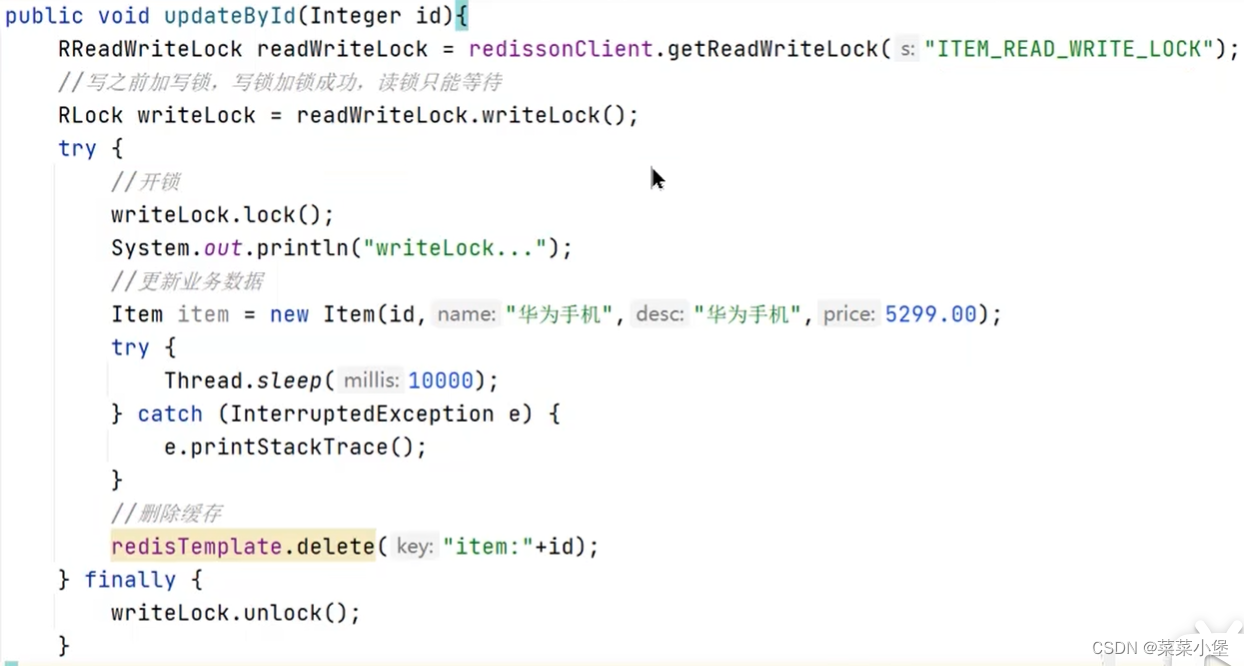
读写锁的方法确实可以达成强一致性,但是效率太低了。



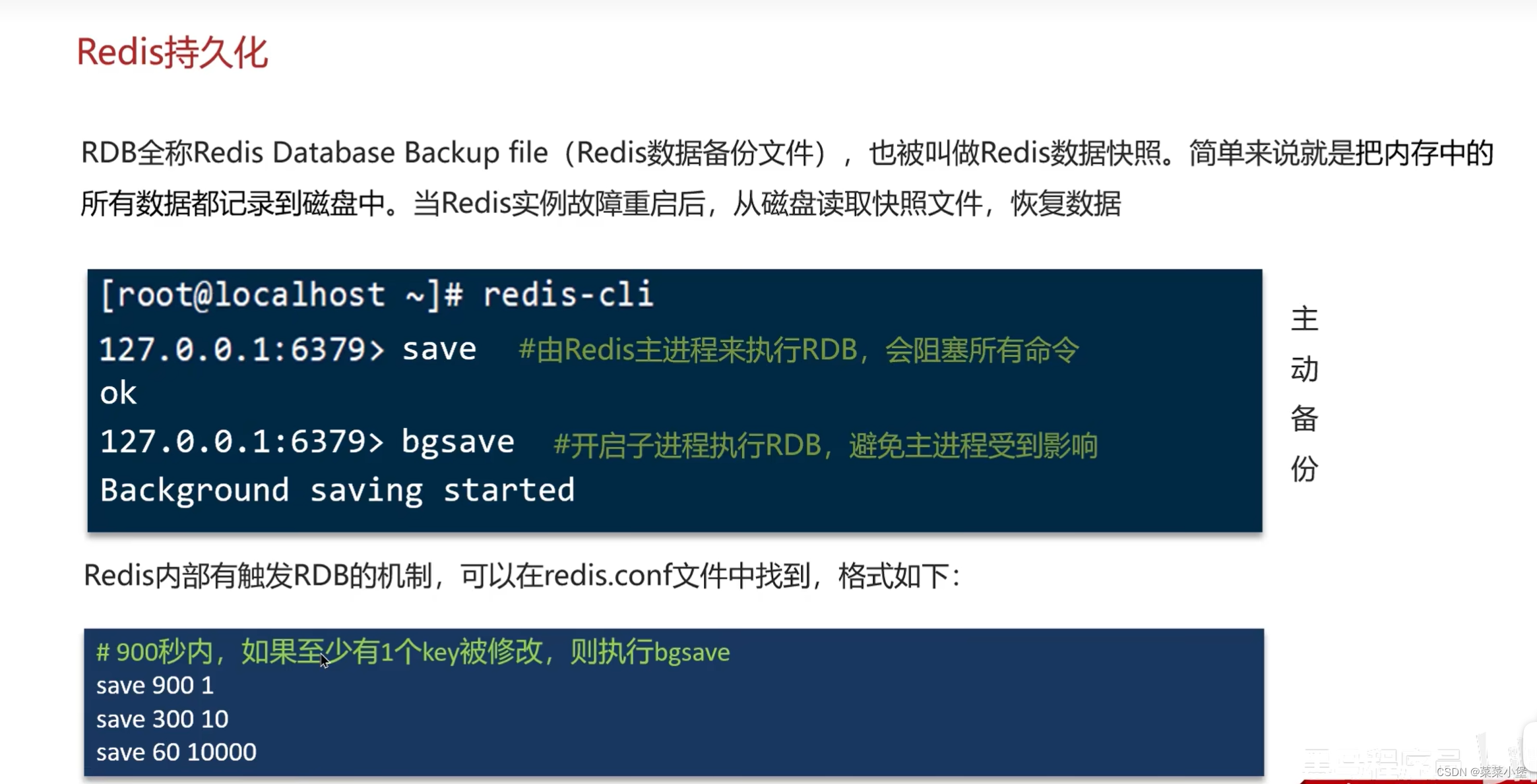

👆默认一般使用everysec

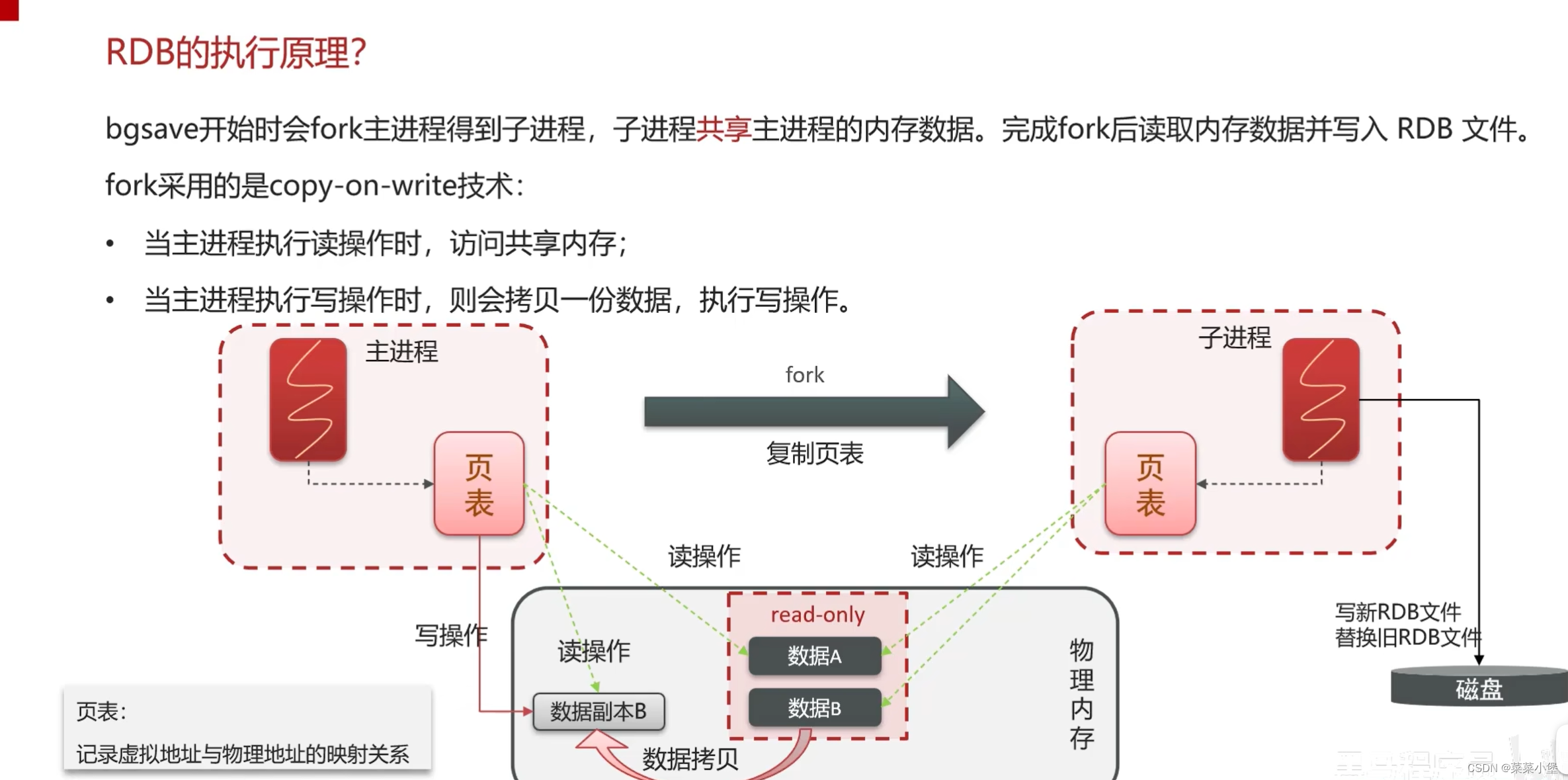
RDB如果两次备份之间宕机了,会丢失数据







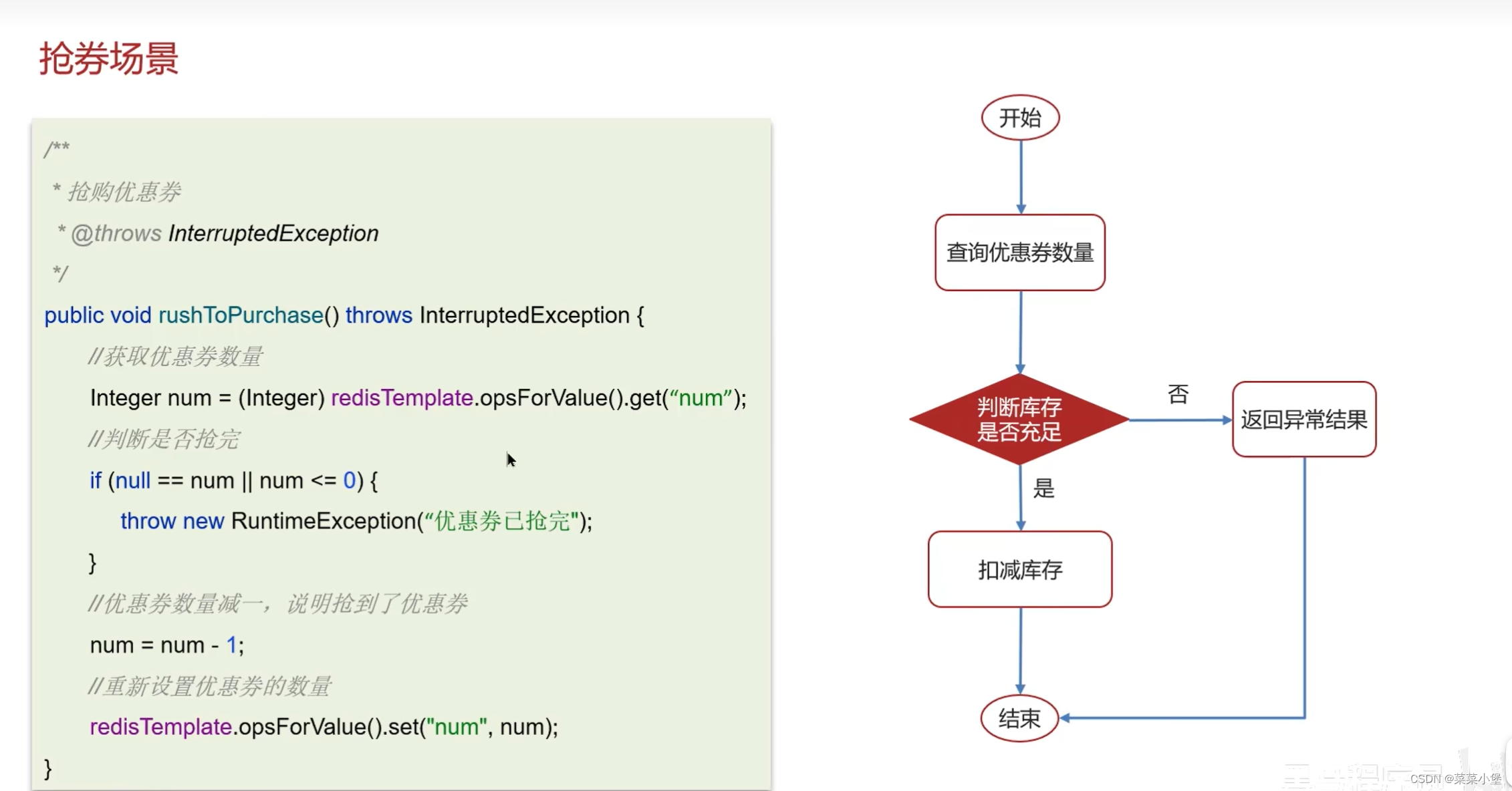
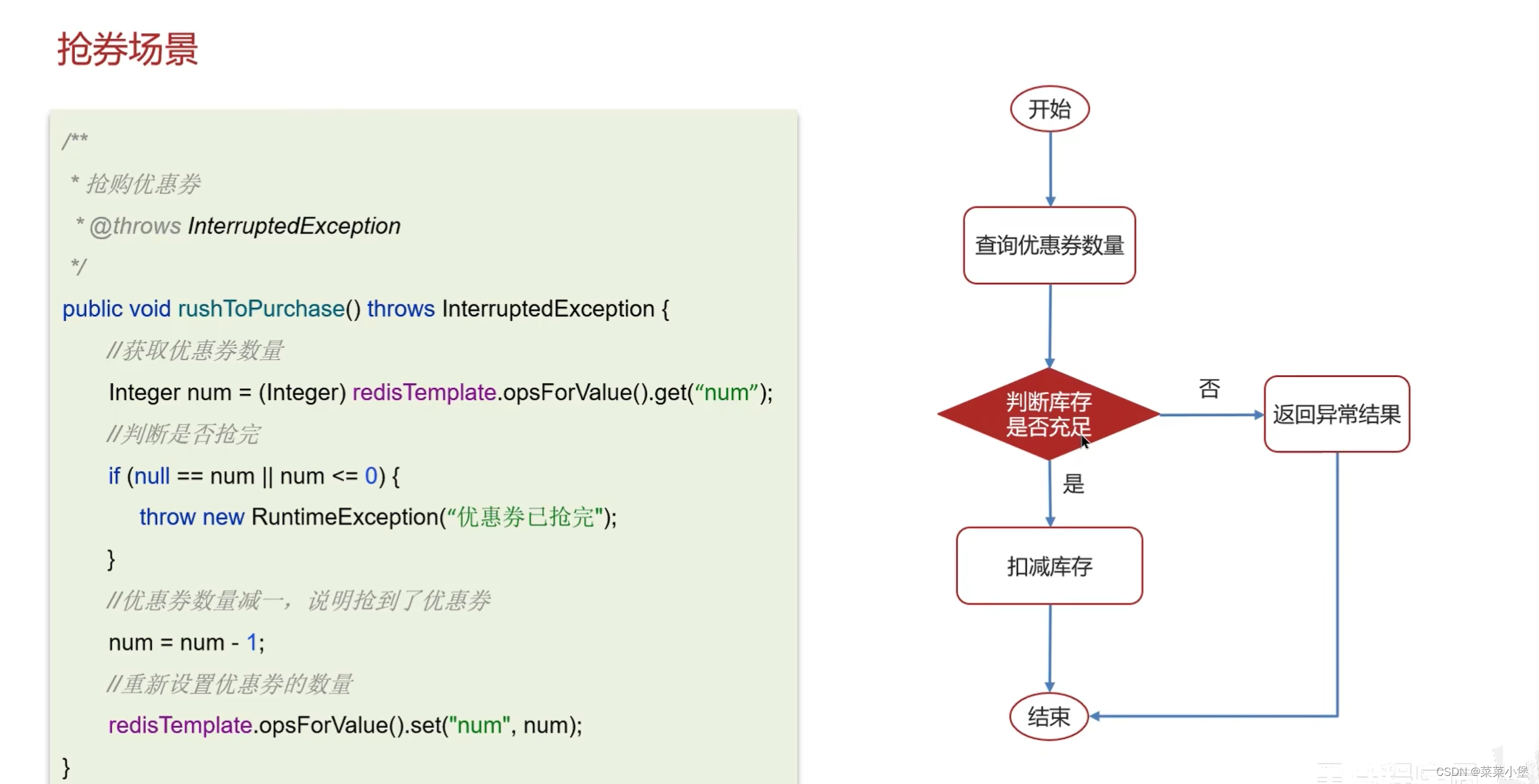
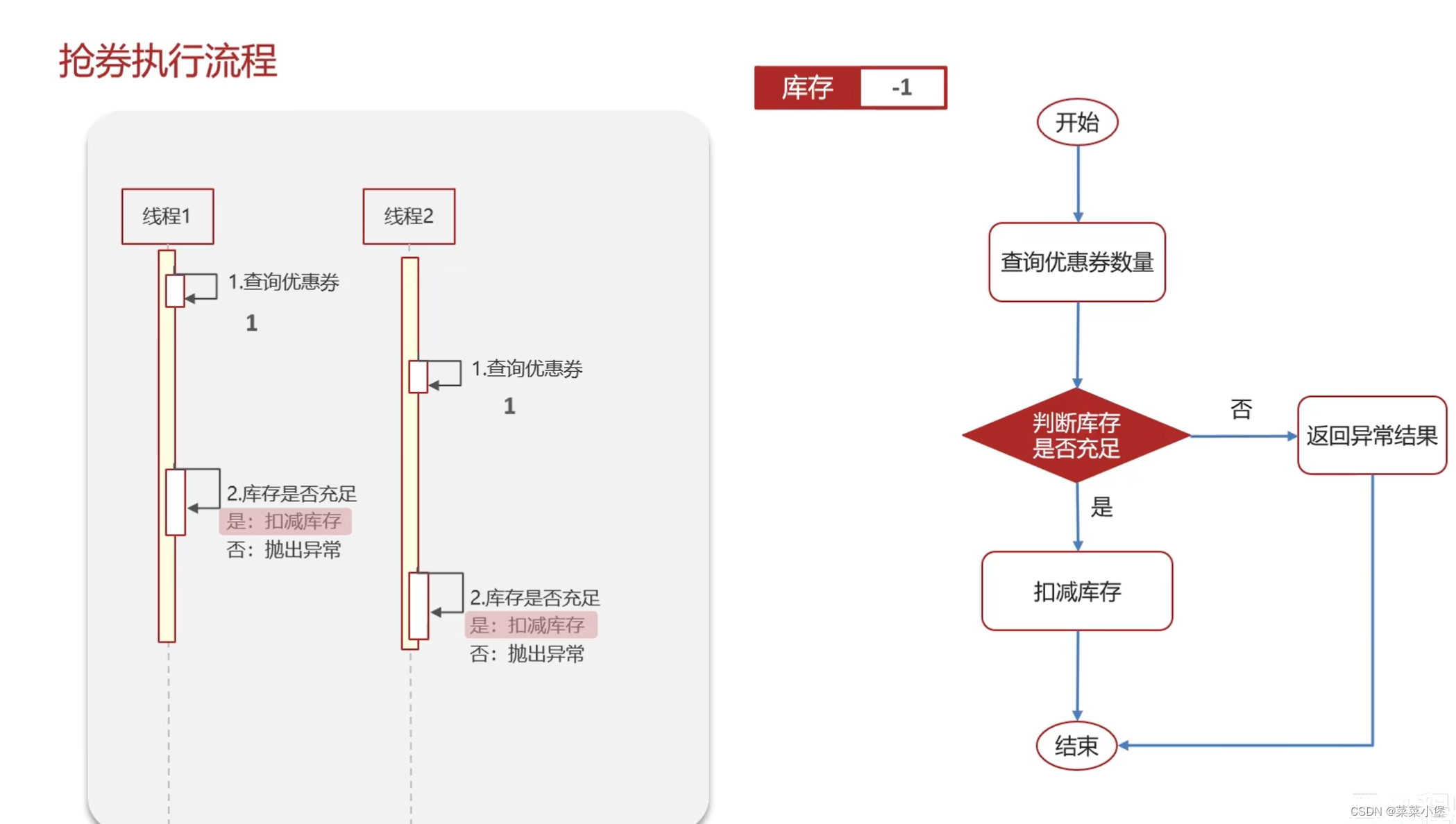
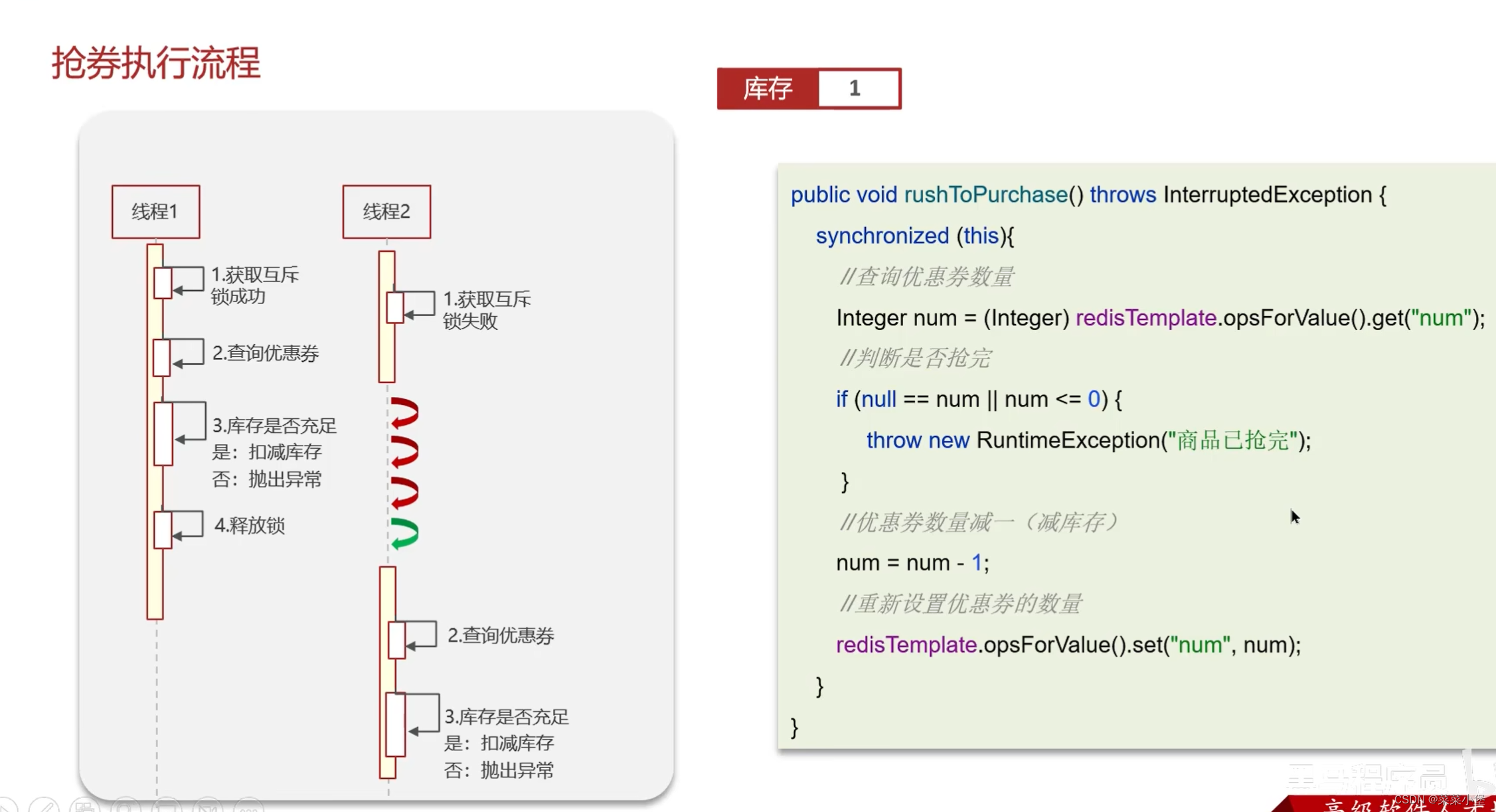
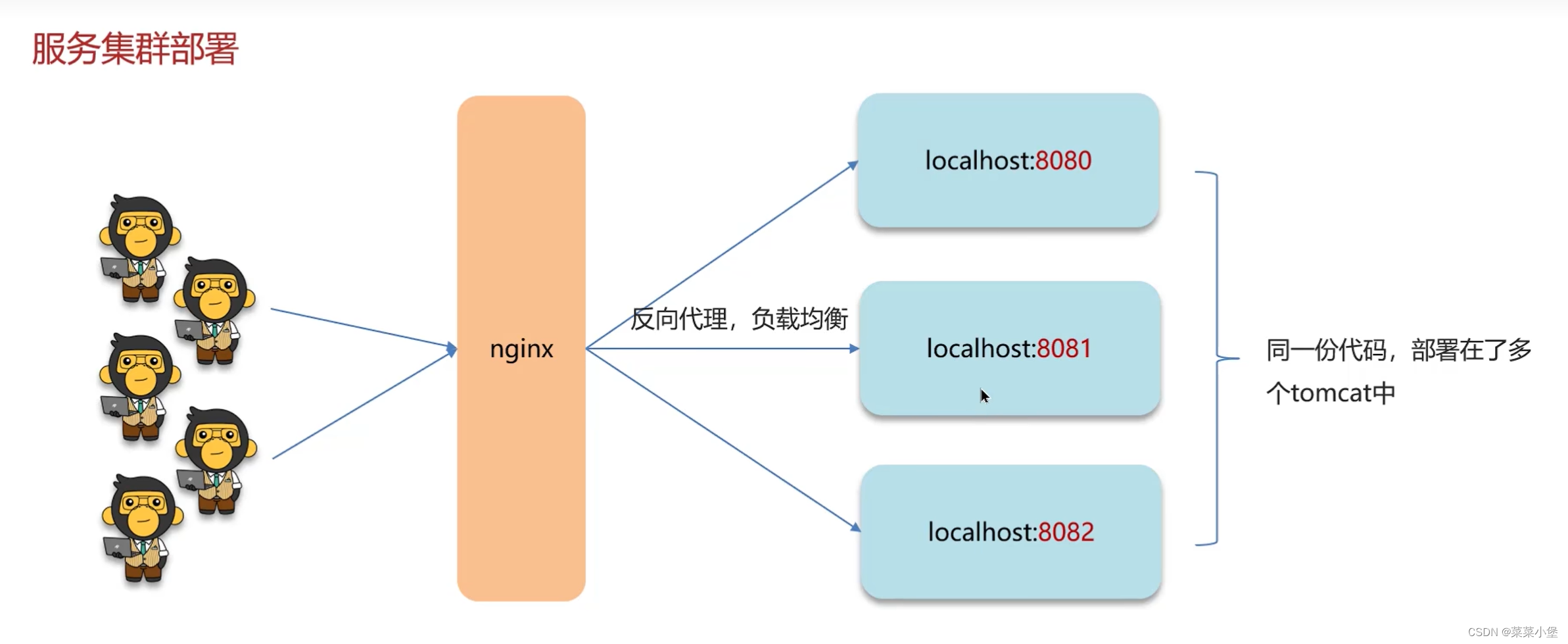
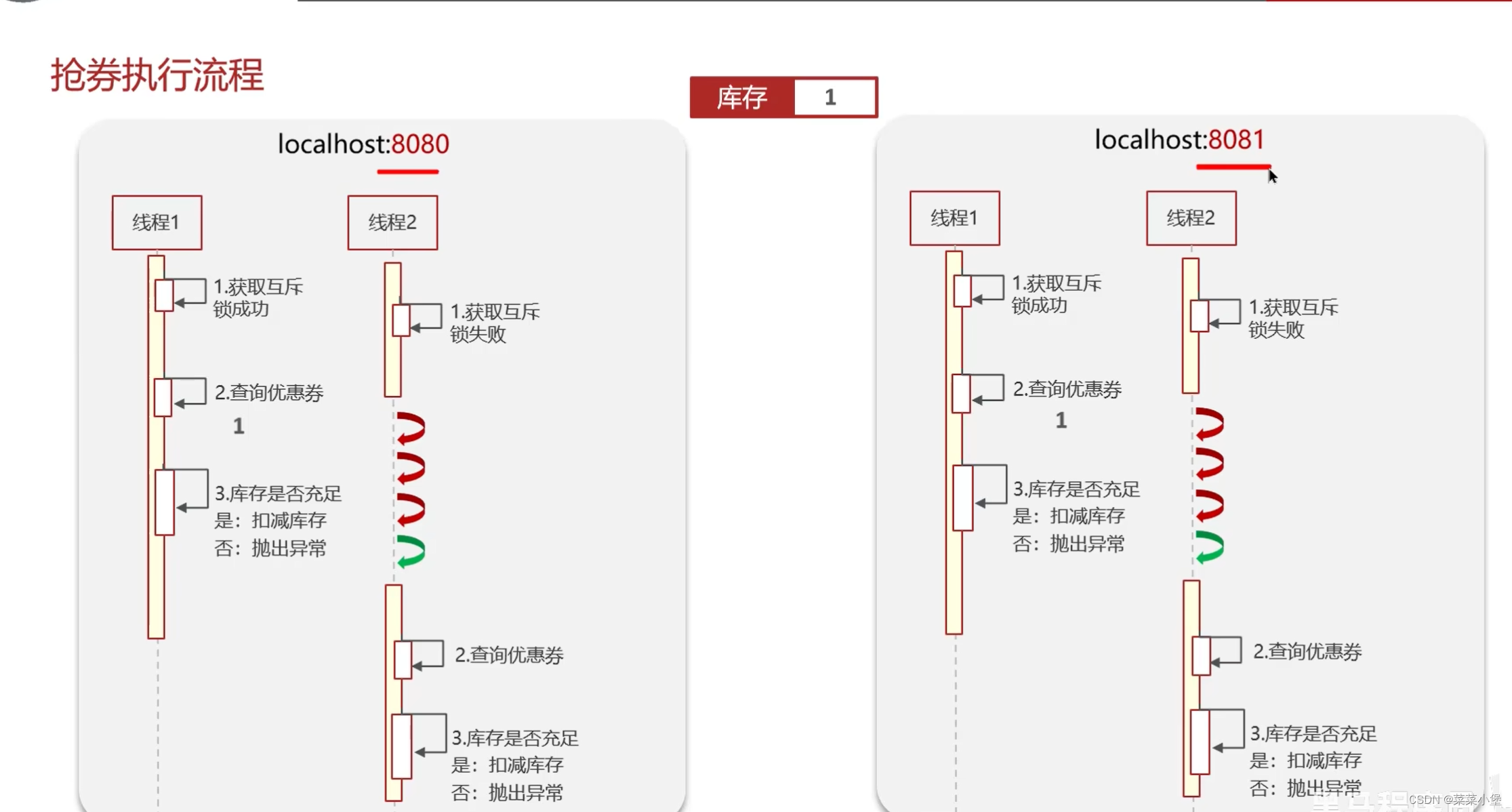
多端部署无法限制线程的互斥👆
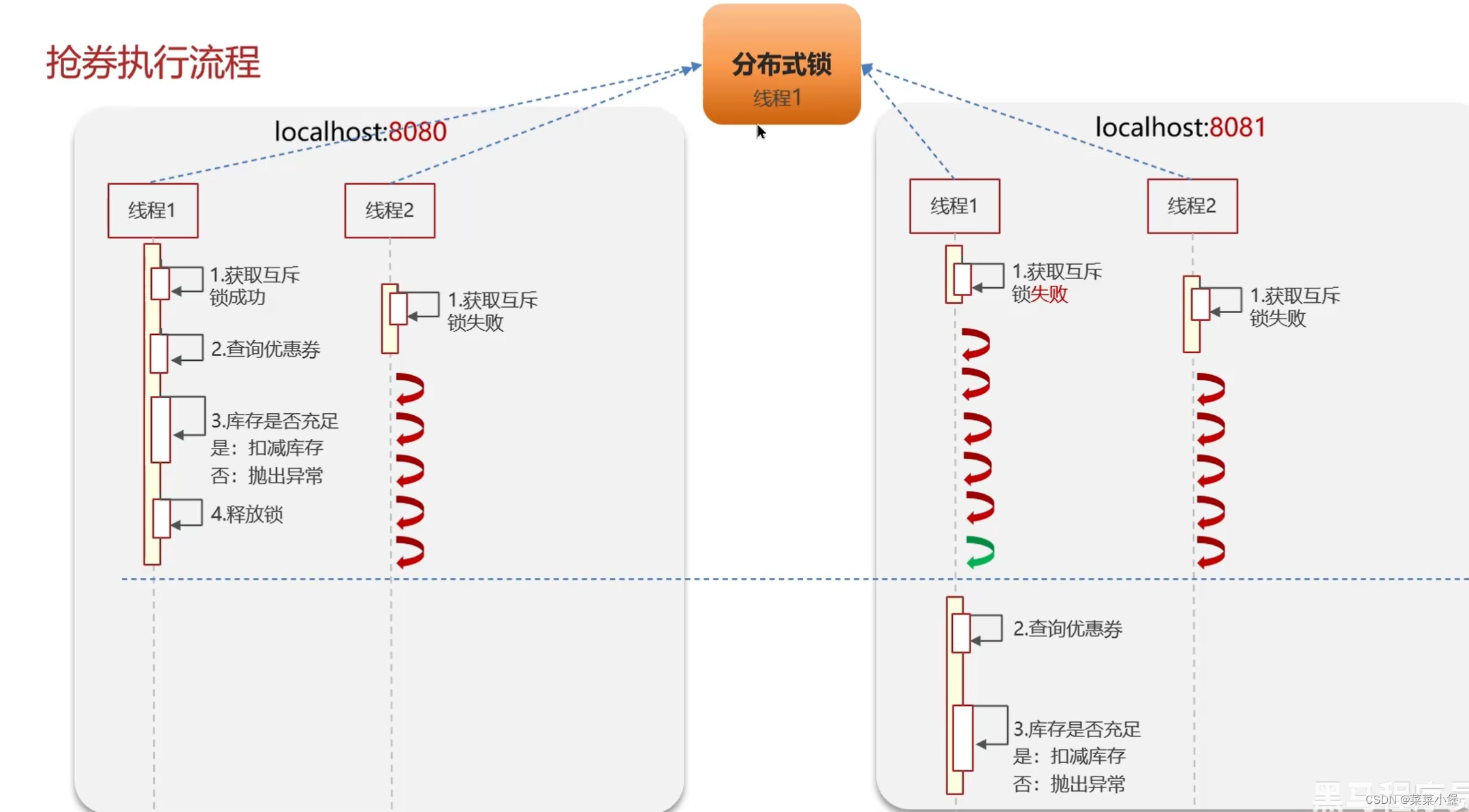
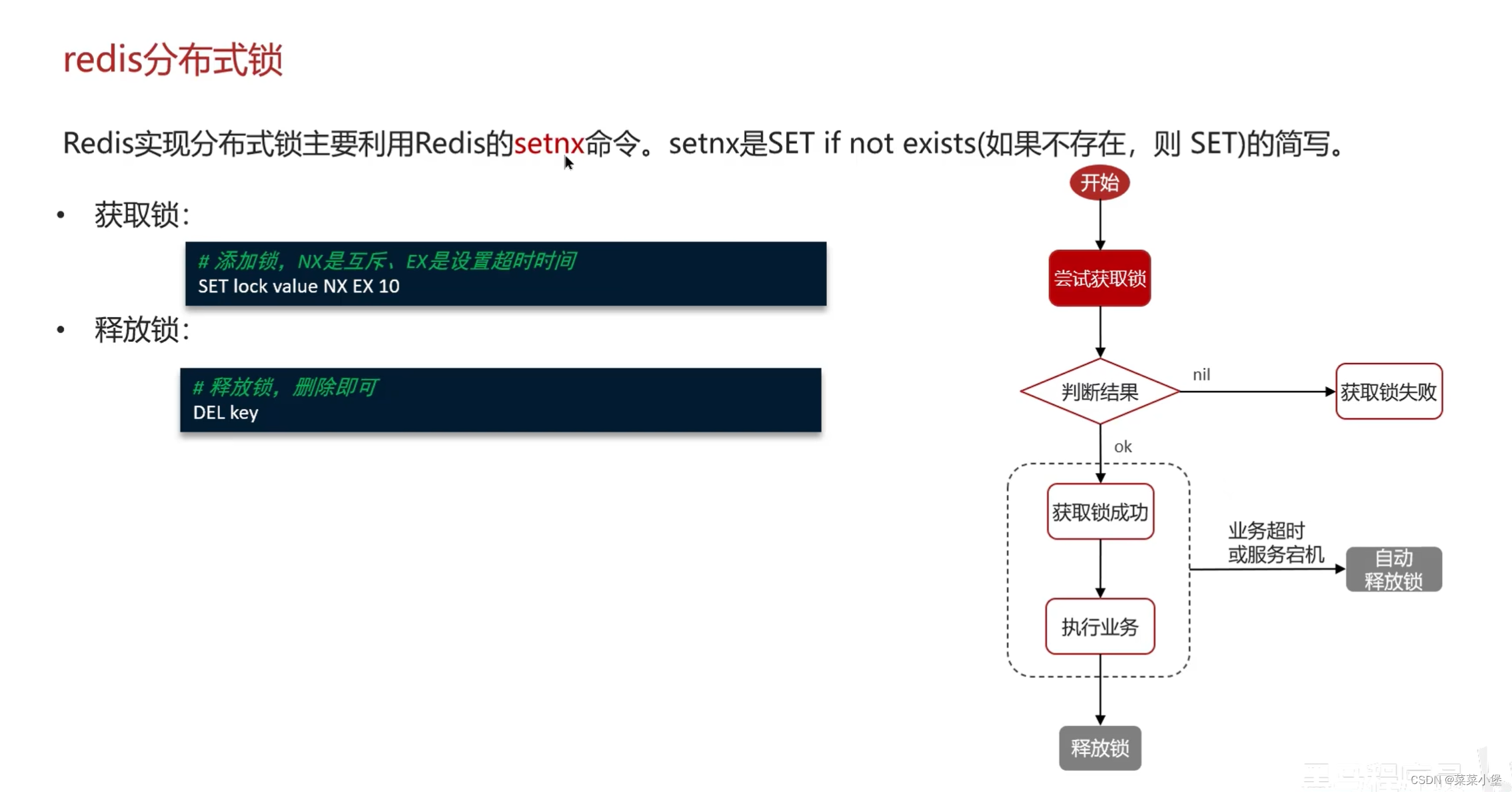
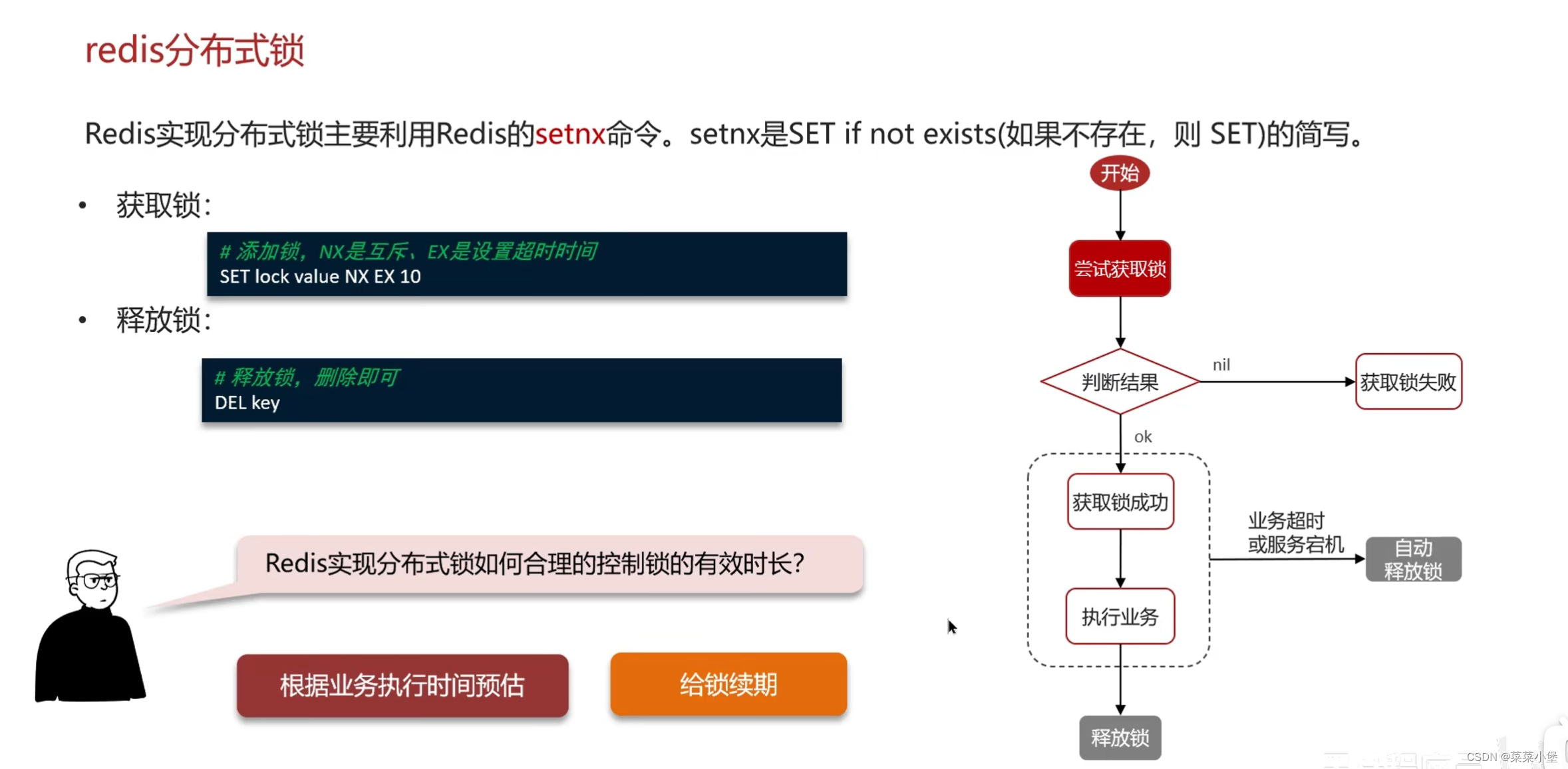
👆EX 过期时间还是需要设定的,因为如果突然宕机了,锁设定了时间会按时间释放,不设定则无法释放会造成死锁。
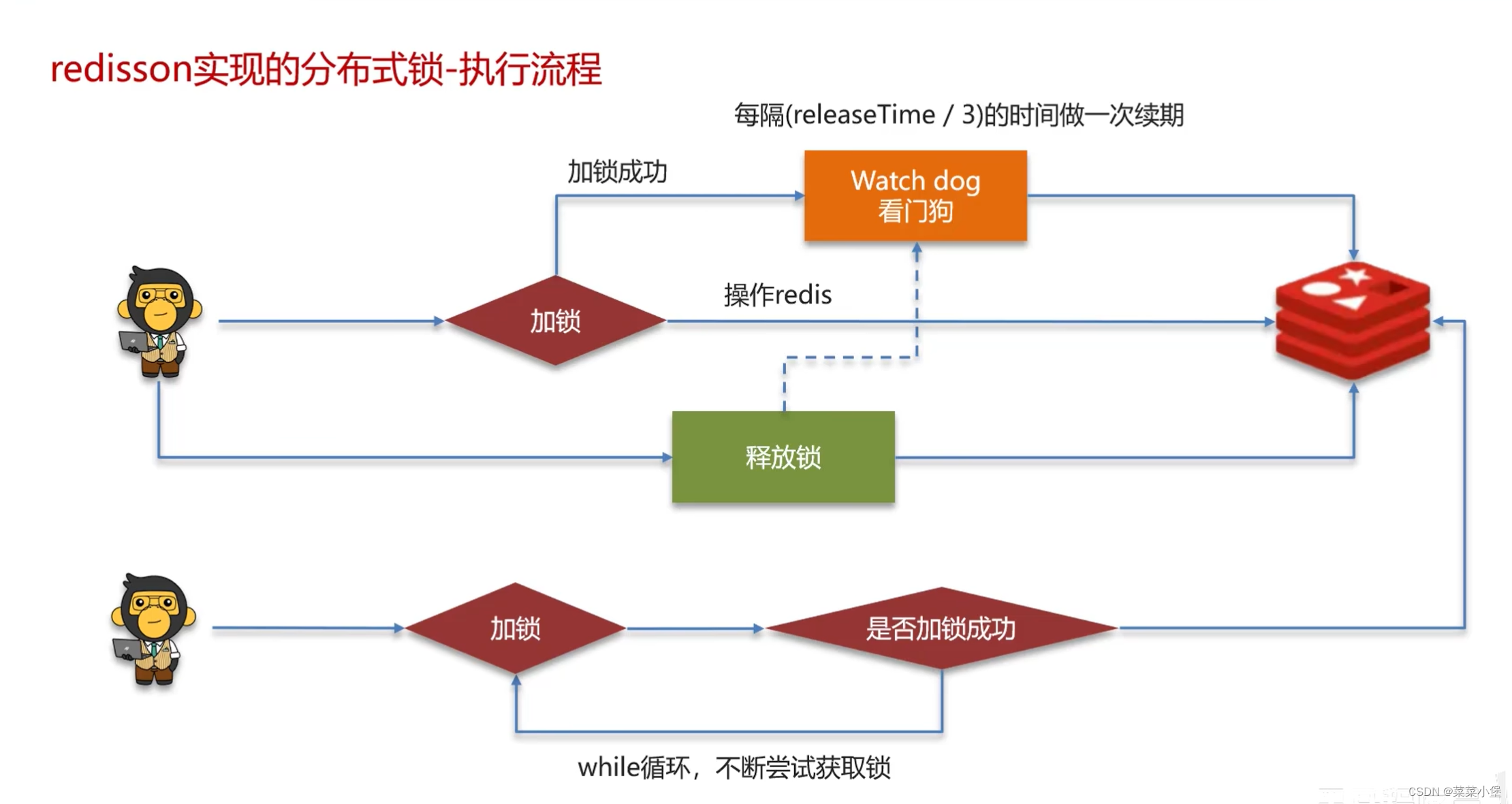


同一个线程可重入锁!!!👆

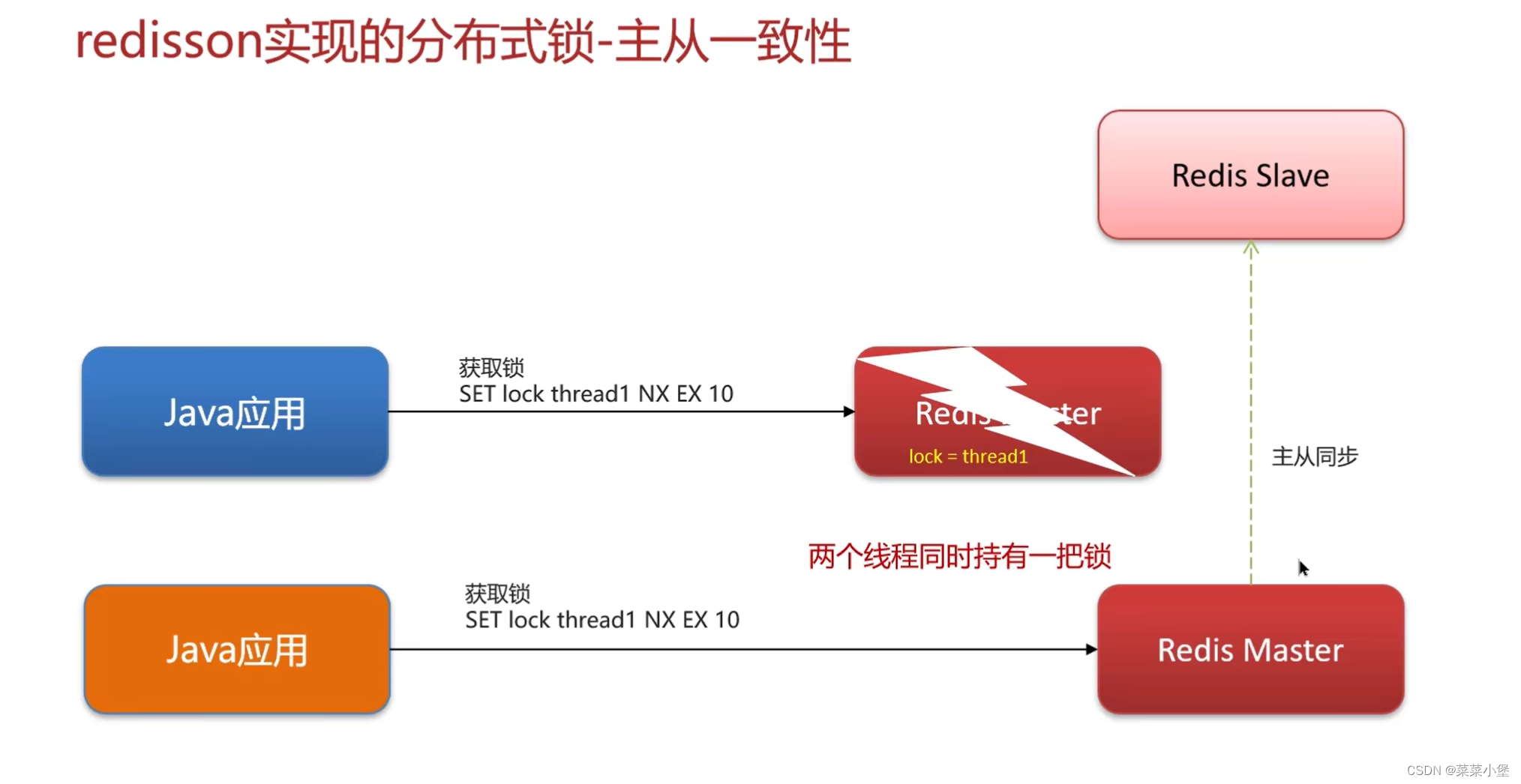
👆主机宕机了后,一个从属机器变成了主机器,再次为新线程分配锁,造成了两个线程持有一把锁,无法保证主从的一致性
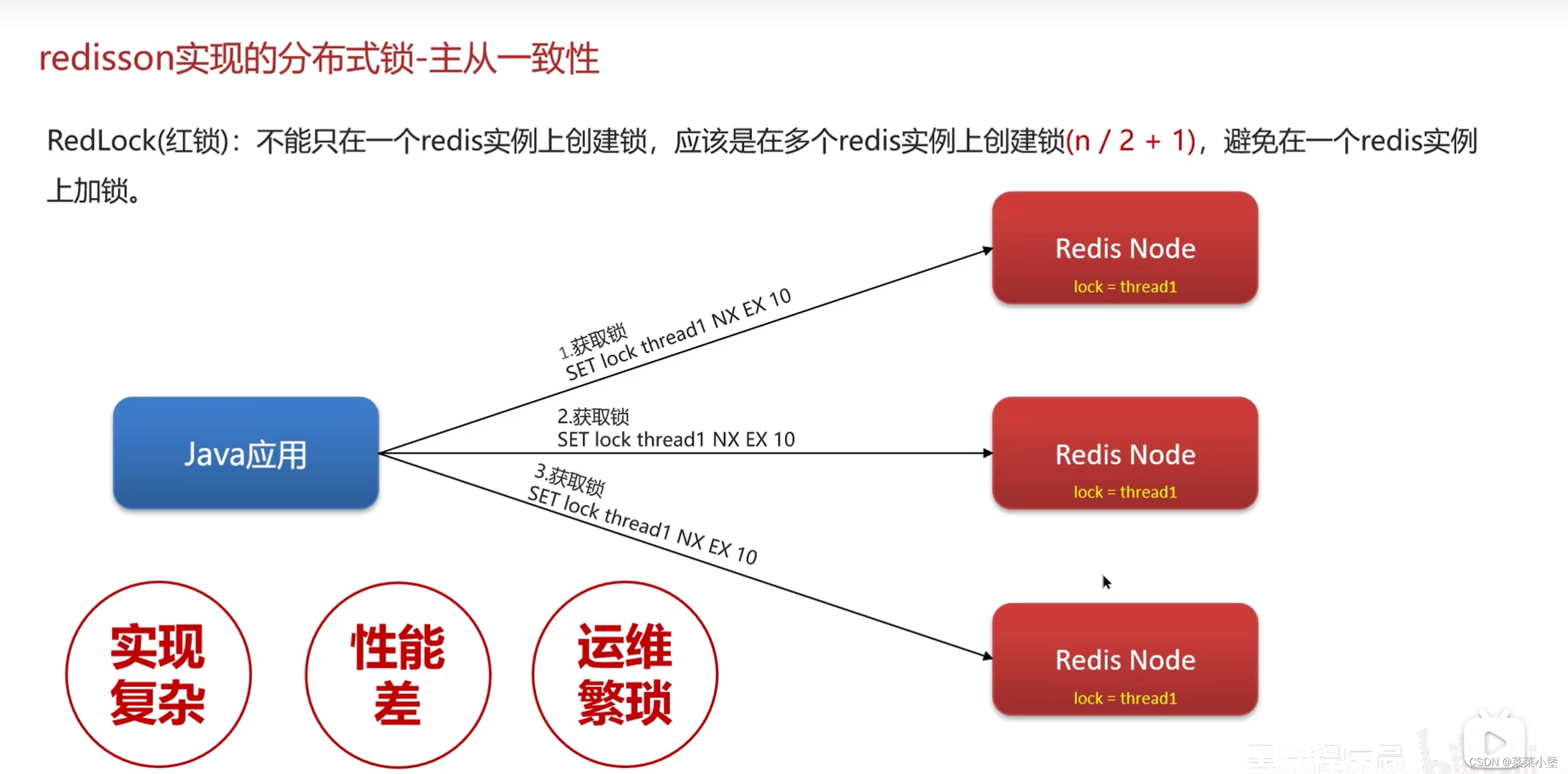
👆红锁可以保证主从数据的一致性。但是低效
一般业务中redis不能保证数据的强一致性,如果想保证强一致性可以使用zookeeper




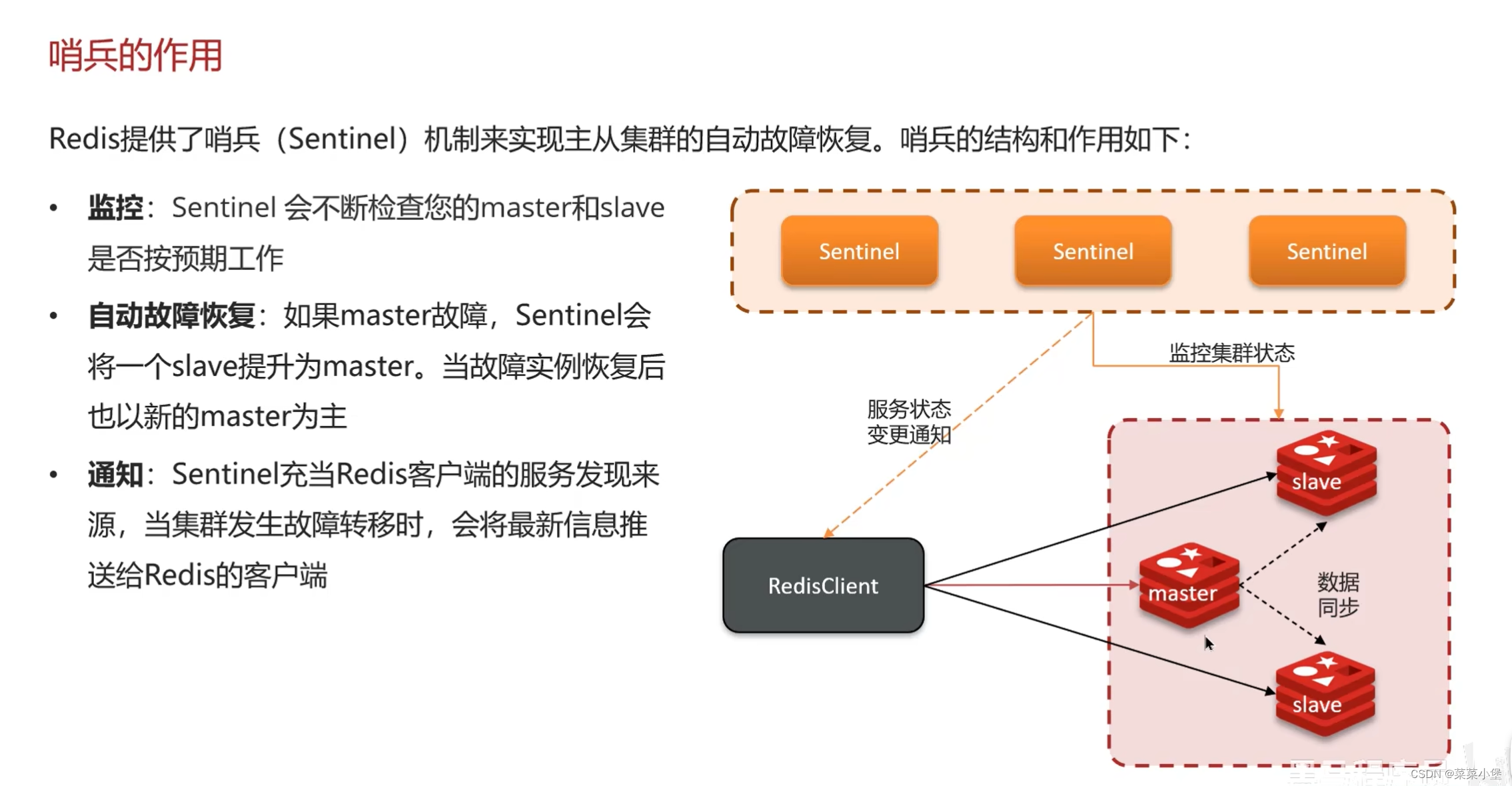
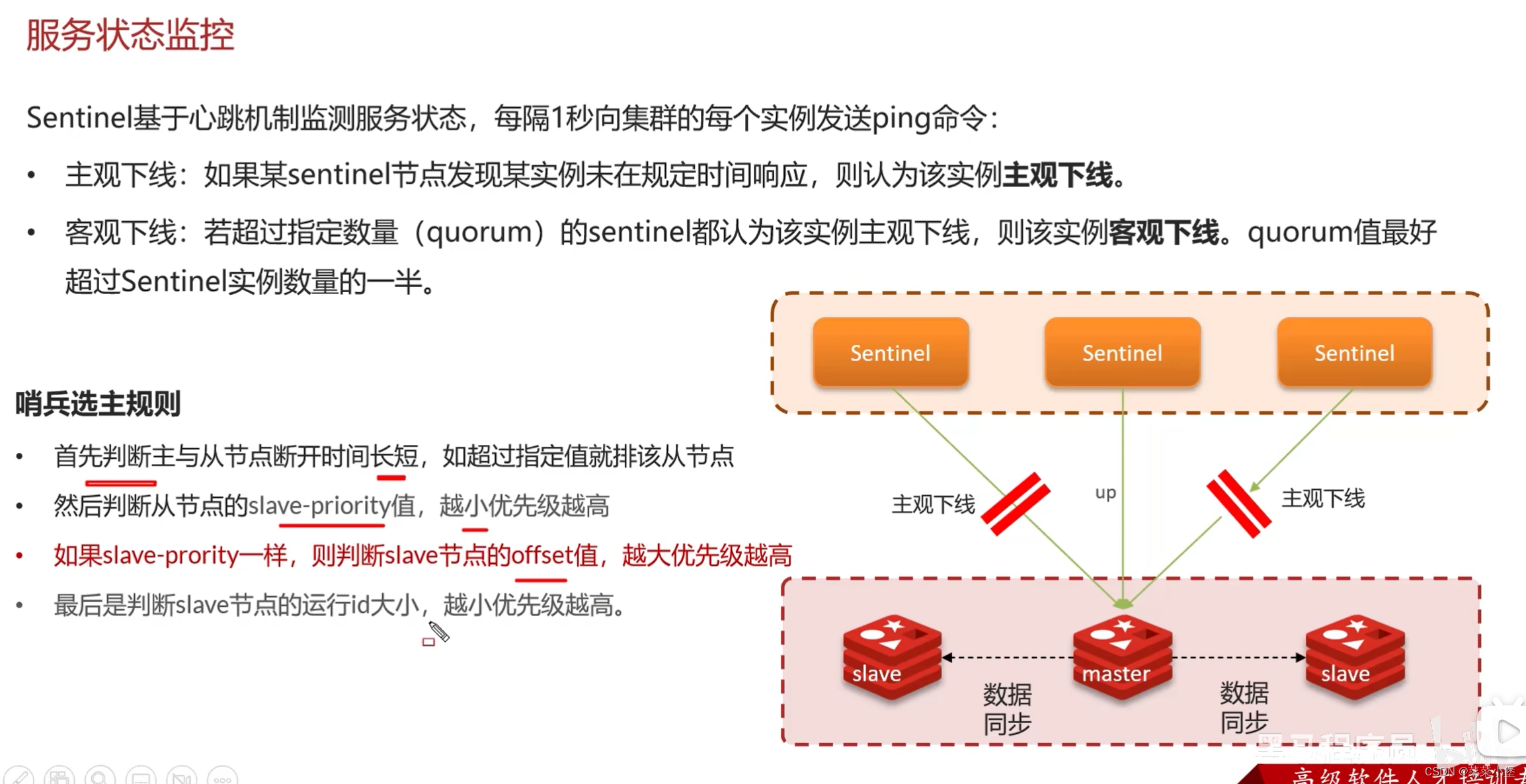
👆当master down了之后哨兵选代替主节点(master)的过程
👇脑裂是因为哨兵监听主节点的时候网络不畅,又在可控范围选择了新的master节点,当网络通常后,清空了master(原),让其成为slave,导致这段时间写在master里的数据被清空。
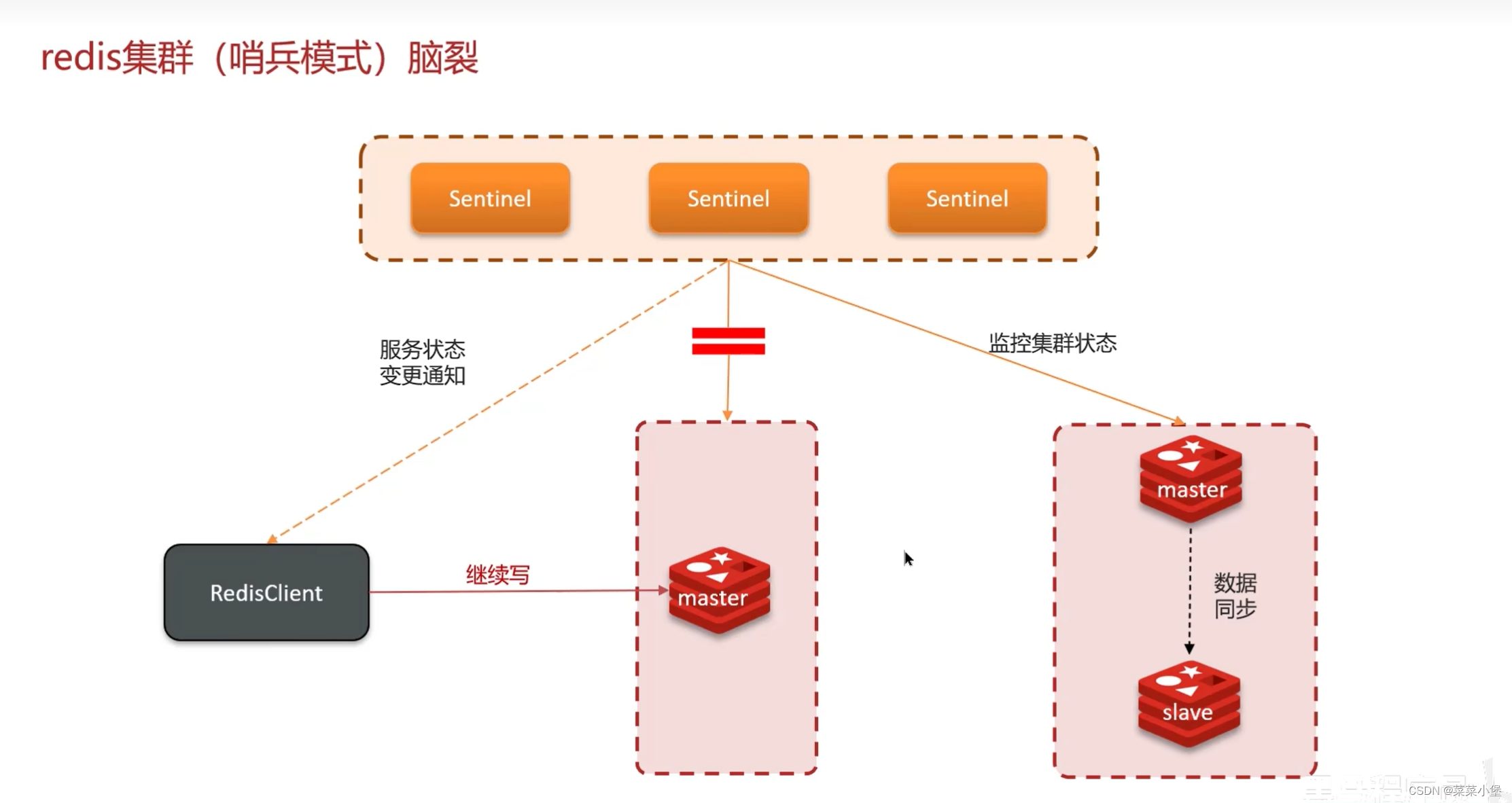
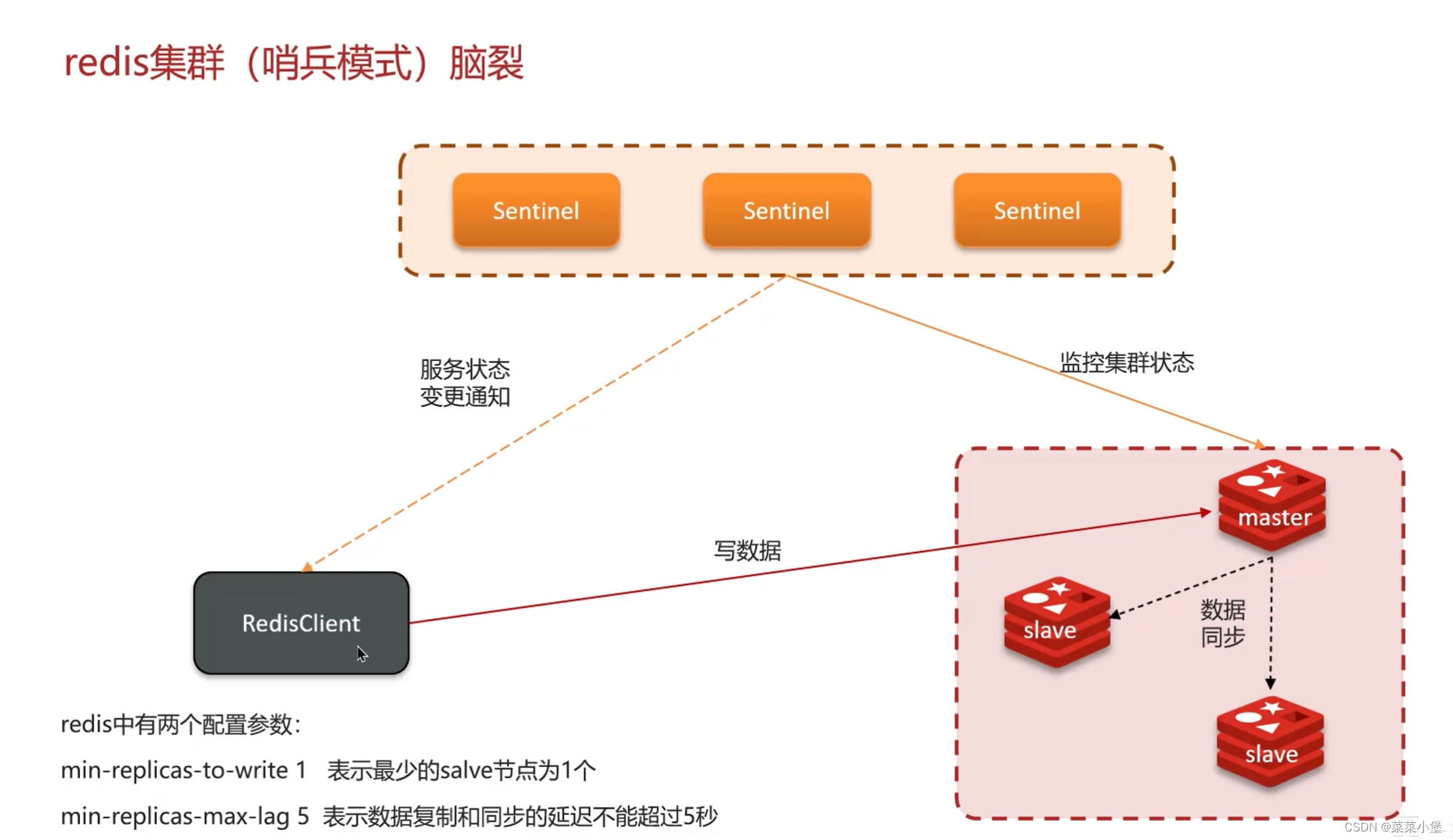
👆这个是解决脑裂的方法,write最少一个salve点,lag延迟不能超过5秒,这些不满足就拒绝客户端的请求,减少数据的进一步丢失。(不是很懂其中逻辑)

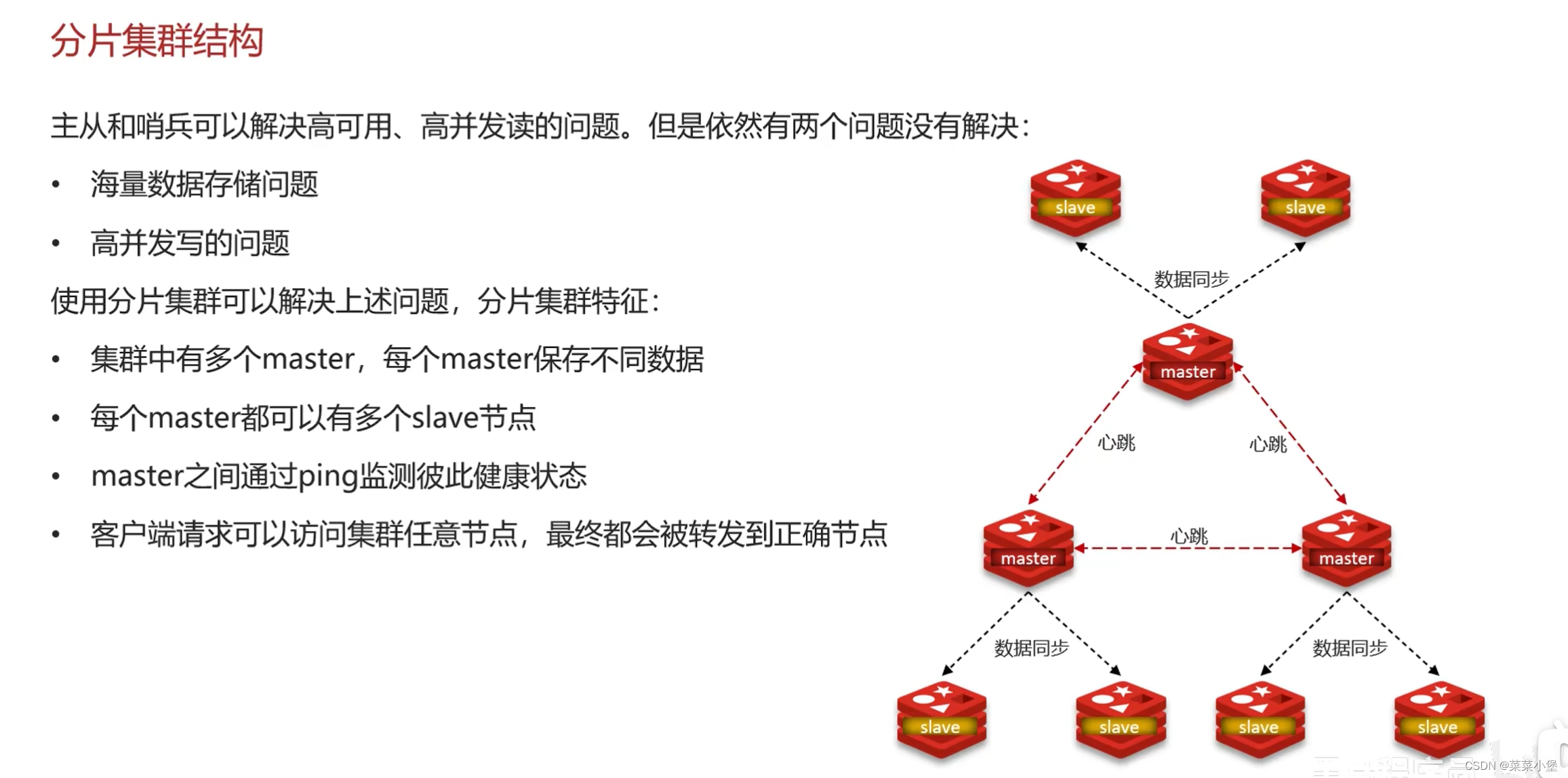
👆每个master保存不同的数据,彼此检测online状况(类似哨兵!),访问任意一个master就可以获得其他master的数据(master之间有路由)。
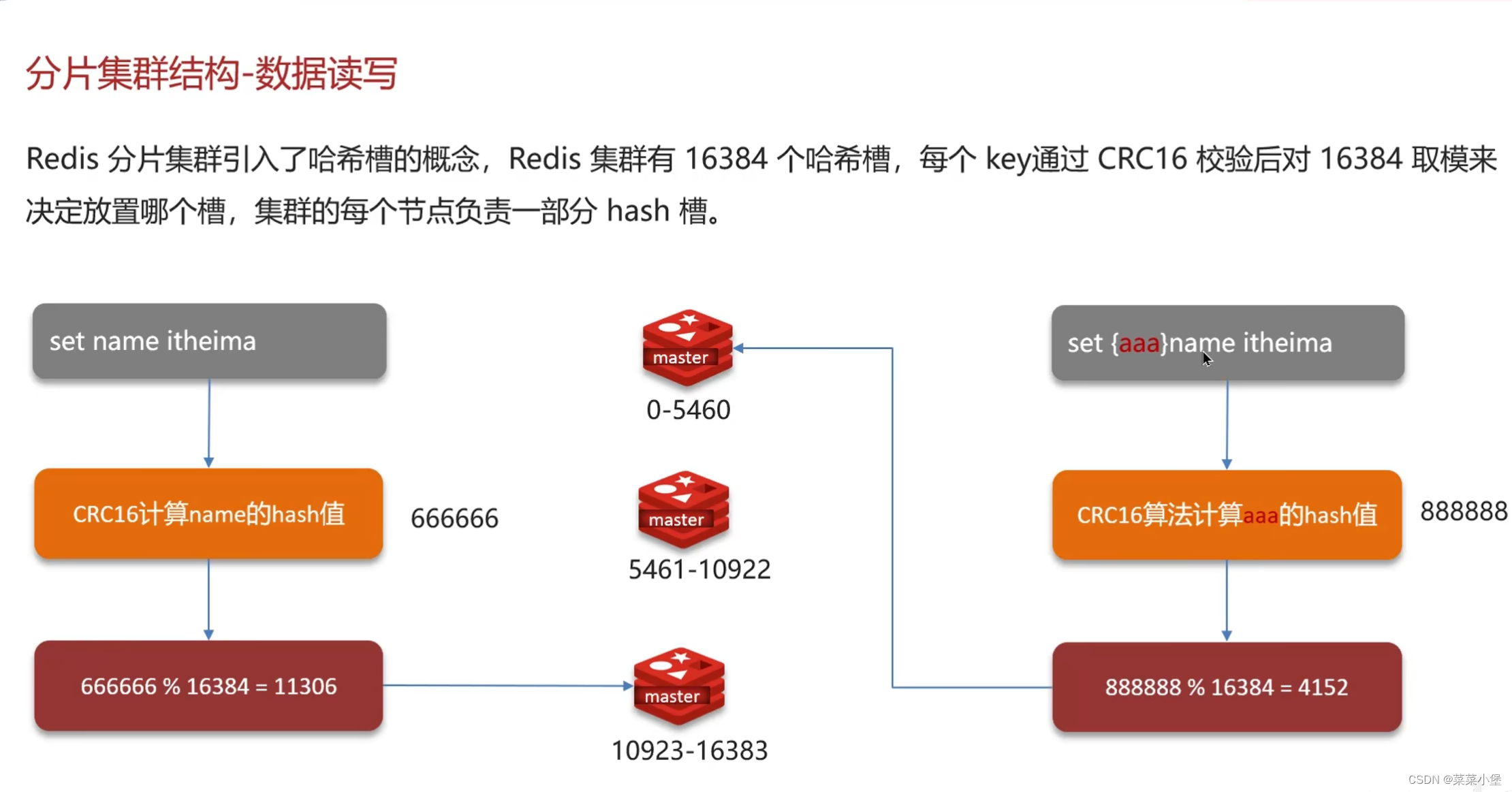
👇有效实例就是master节点



等待数据就绪和读取时间浪费了很多时间。👆
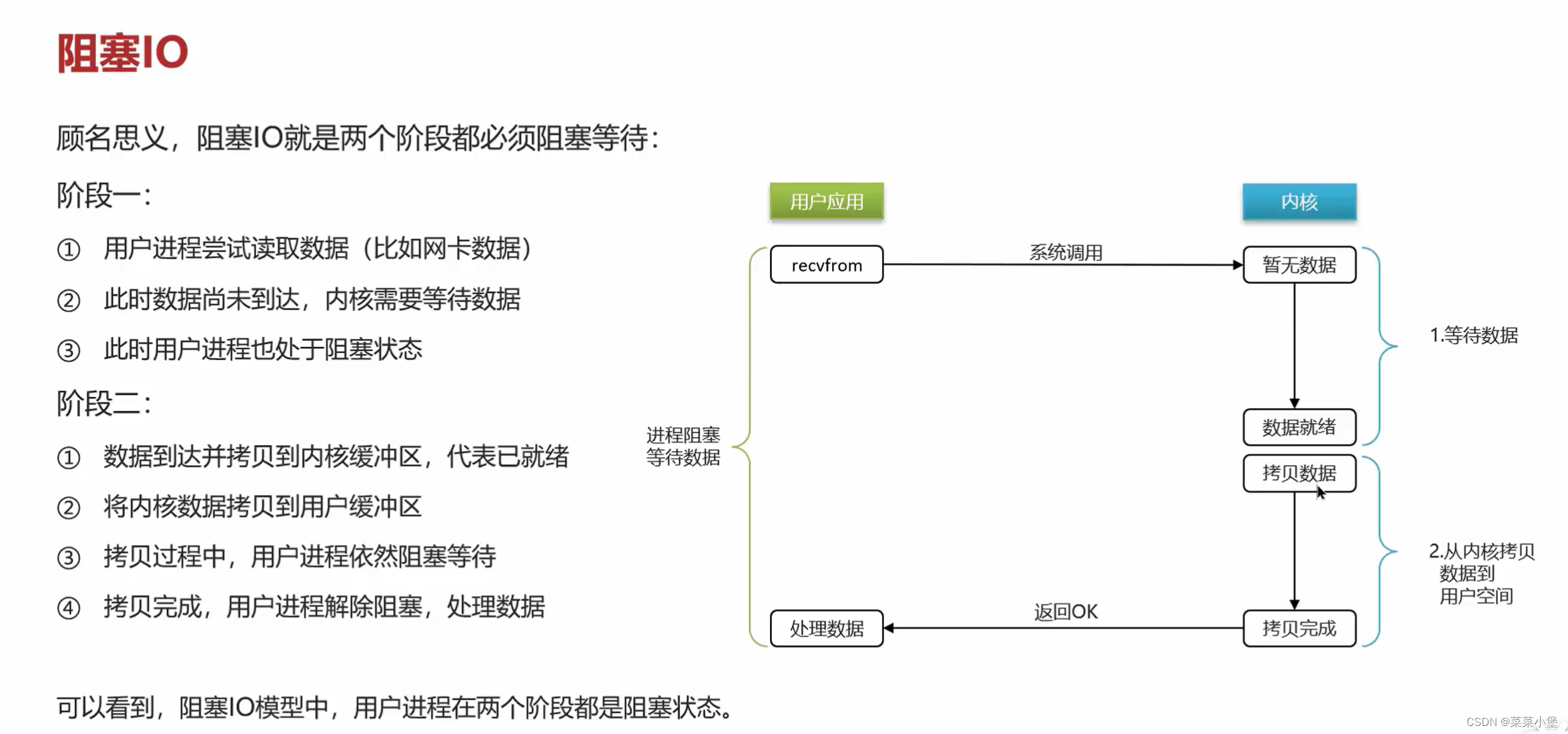
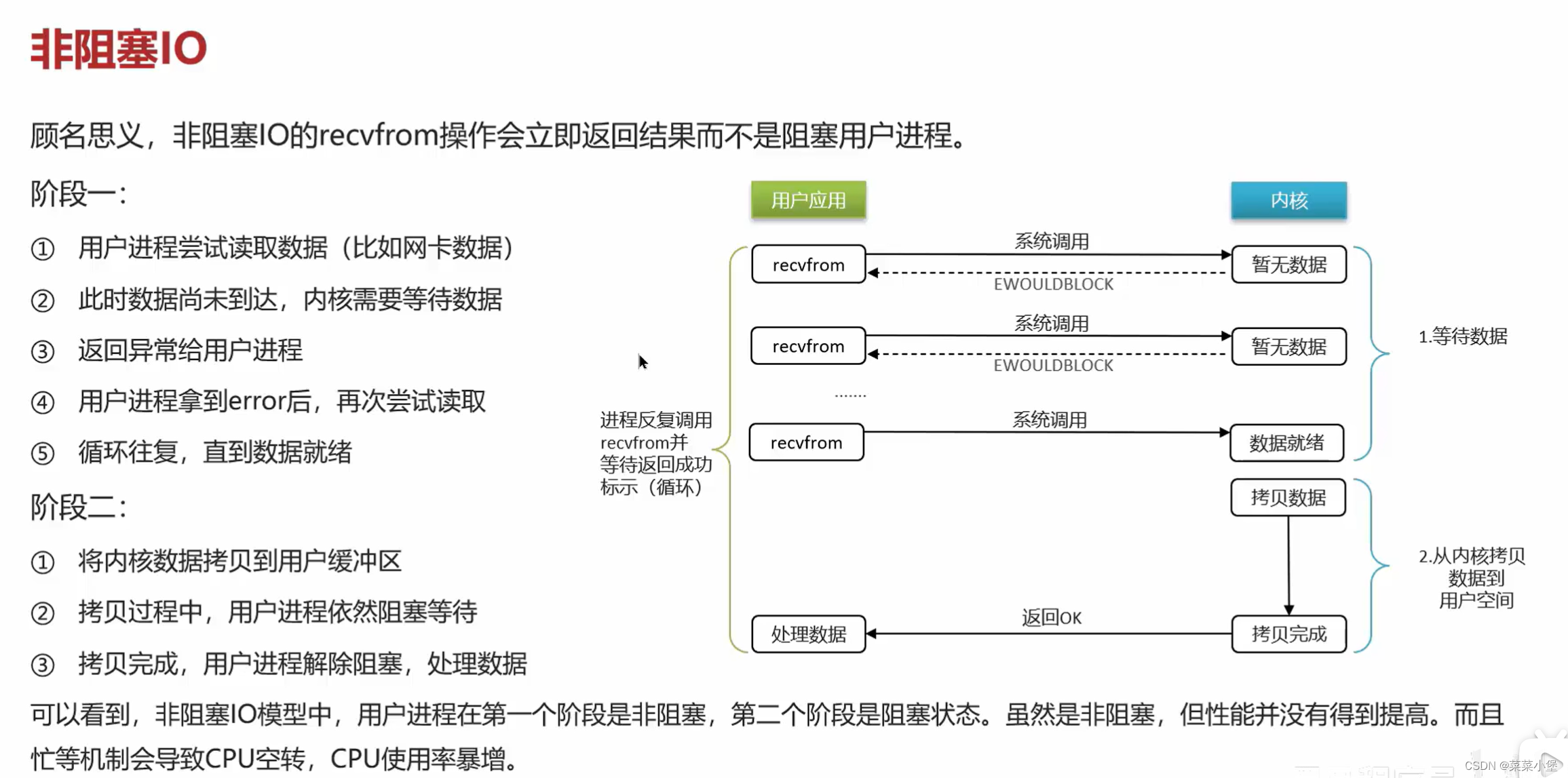
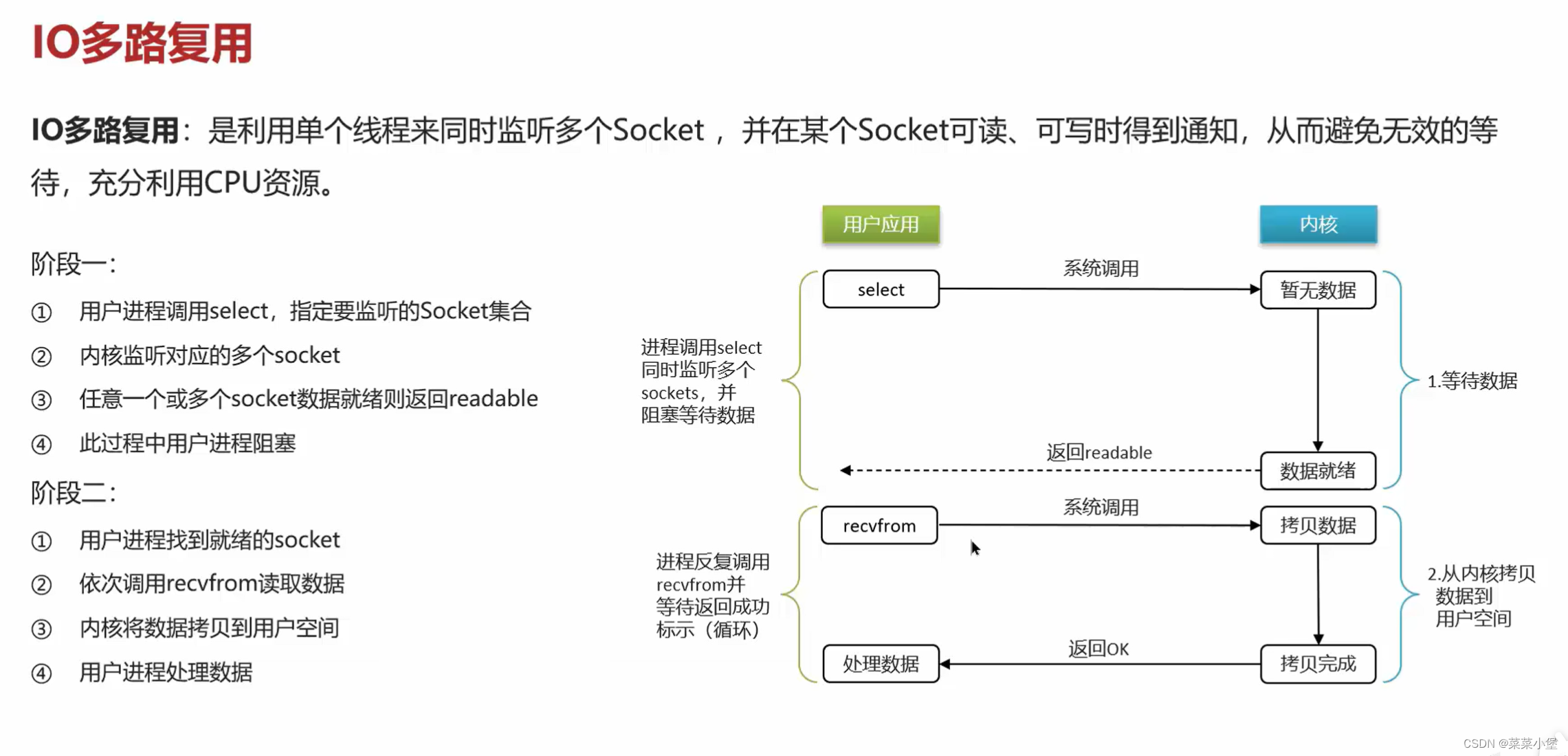
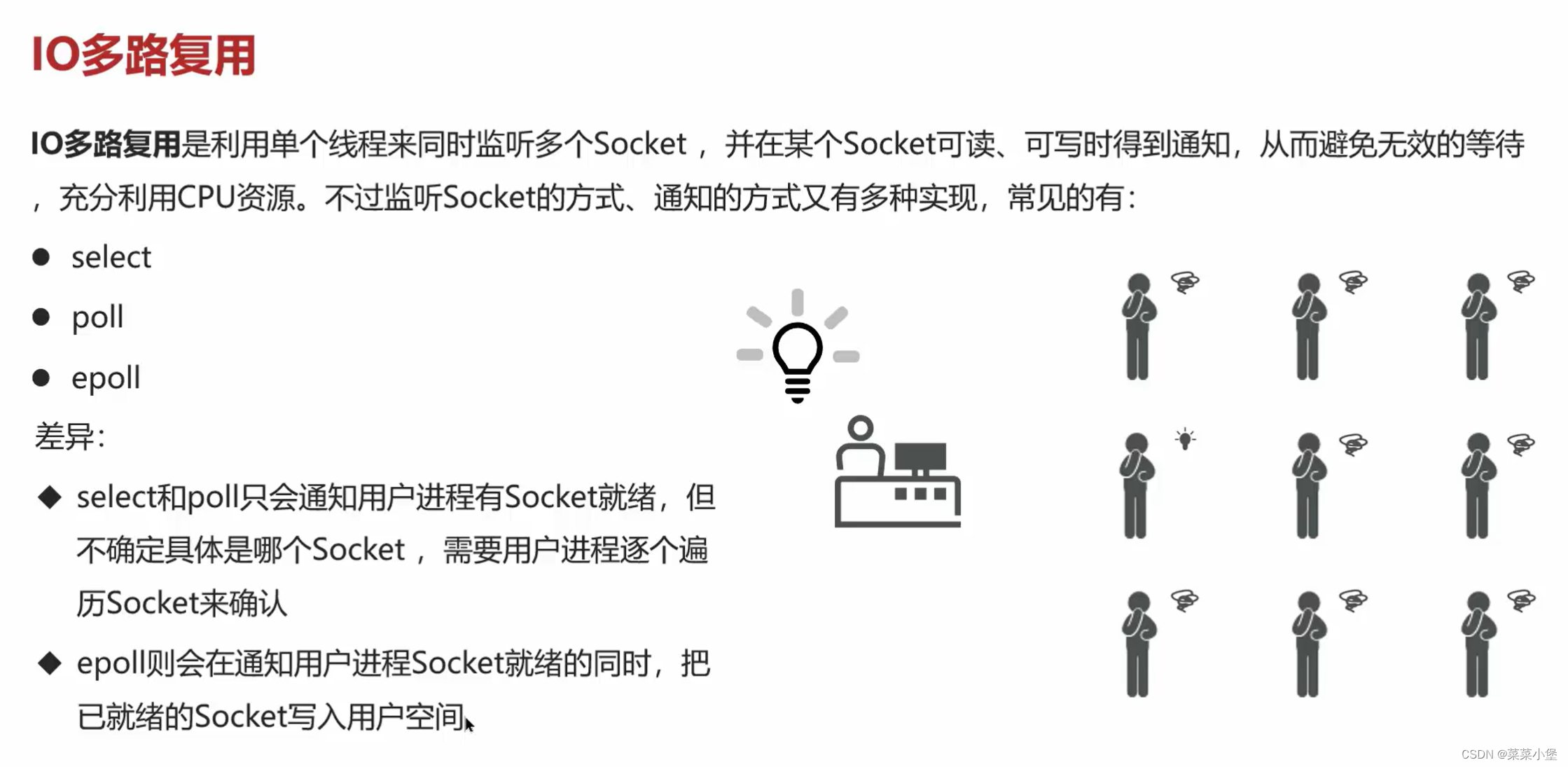
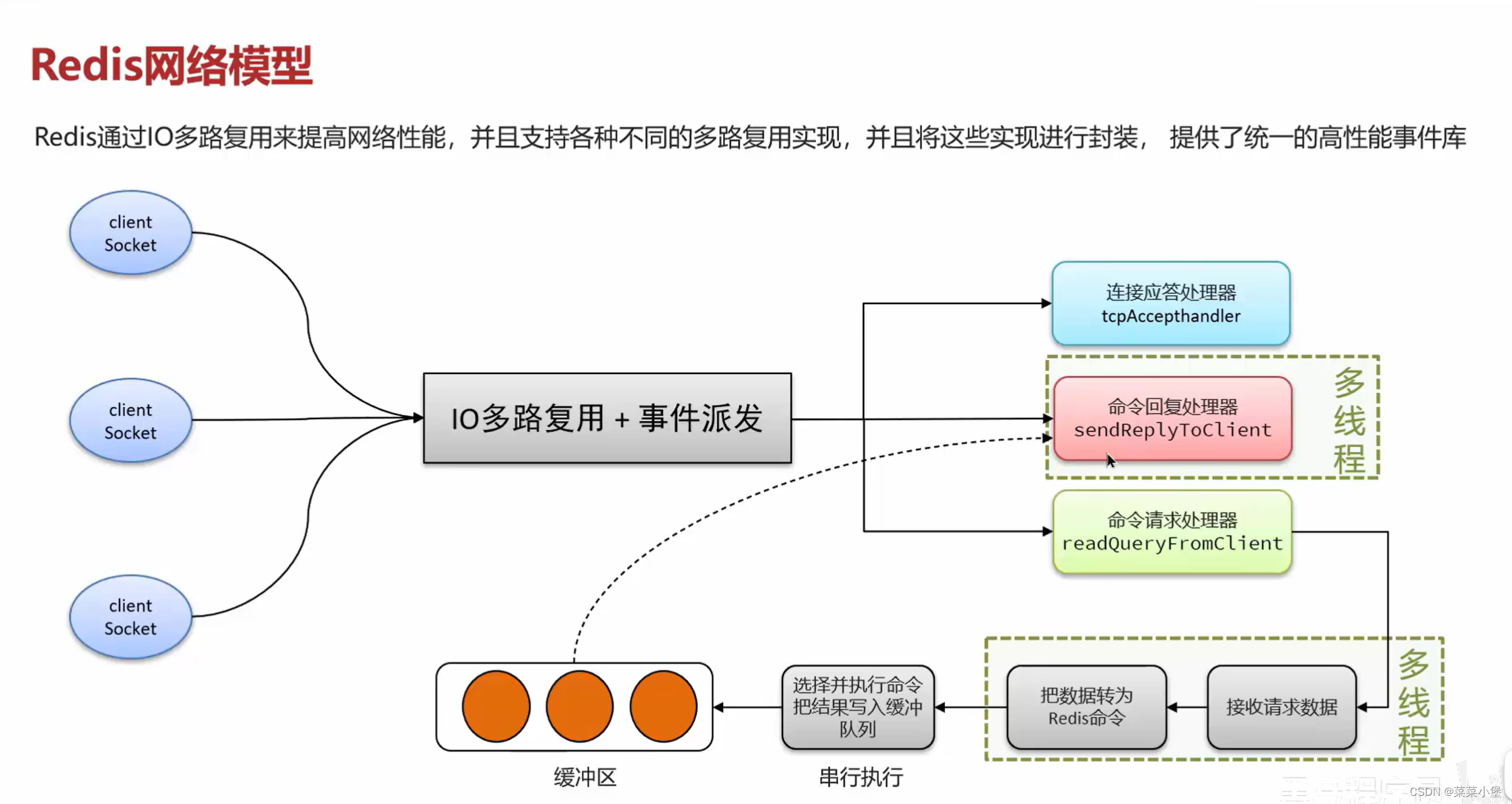
👆IO是最耗时的操作


















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









