



 作者提出了一种名为HiduNet的文本隐写分析方法,结合层次监督学习和双重视觉机制。文章对比了基于RNN和CNN的加密效果,指出这些方法的不足在于特征表示简单。研究还探讨了安全性和嵌入偏差问题,以及NLI任务的应用。实验涵盖了多种加密文本分析和数据预处理策略,展示了H-Net和S-Net层的性能提升。
作者提出了一种名为HiduNet的文本隐写分析方法,结合层次监督学习和双重视觉机制。文章对比了基于RNN和CNN的加密效果,指出这些方法的不足在于特征表示简单。研究还探讨了安全性和嵌入偏差问题,以及NLI任务的应用。实验涵盖了多种加密文本分析和数据预处理策略,展示了H-Net和S-Net层的性能提升。
Text Steganalysis Based on Hierarchical Supervised Learning and Dual Attention Mechanism
是一篇B类的文章
作者提出的HiduNet(hierarchical supervised learning and dual attention mechanism Net)隐写的方法是针对对抗分析检测的。类似于检测算法。
作者说对于Yang提出的基于RNN的文本加密和Wen提出的CNN加密效果都不错,a main problem with these methods is that the extracted feature representations are relatively simple and insufficient,但是与高级加密算法相比检测精度不足。
这篇文章 Related work 中可以多看两遍学一下对比分析的写法。
Element-wise addition , ⨁ \bigoplus ⨁ 是一种数学操作,通常用在数组或矩阵中。在这个操作中,两个数组或矩阵的相同位置的元素被相加。这要求两个数组或矩阵必须有相同的形状和尺寸
安全性分析
embedding中安全性分析,
. However, the process of constructing the reversible mapping inherently introduces embedding deviations.
Unfortunately, there are rare explorations of the embedding distortion and elaborate structure designs in the text steganalysis community
(然而,构造可逆映射的过程固有地引入嵌入偏差。
不幸的是,在文本隐写分析社区中,对嵌入失真和精细结构设计的探索很少)。
NLI任务:NLI(NaturalLanguageInference)任务是一种自然语言处理任务,旨在判断两个文本之间的逻辑关系。在NLI任务中,通常有两个输入文本,一个称为前提(premise),另一个称为假设(hypothesis)。任务的目标是确定假设是否可以从前提中推断出来,即判断前提和假设之间的关系是蕴含(entailment)、矛盾(contradiction)还是中立(neutral)。
例如,给定以下前提和假设:前提:一个人在下象棋。假设:这个人在室内。
隐写术评估的方法 Jensen-Shannon Divergence(JSD).
与通常用于评估生成文本隐写术统计不可见性的Kullback-Leibler距离(KLD)[11]、[14]、[46]相比,由于其对称性,JSD是一个更好的度量。

第五页的这个可以看一下,是一个非常好的解释实验的方法。
Provably Secure Generative Linguistic Steganography这篇文章里有ADG-based的加密方法。
第六页开始作者才开始写自己所使用的加密方法。
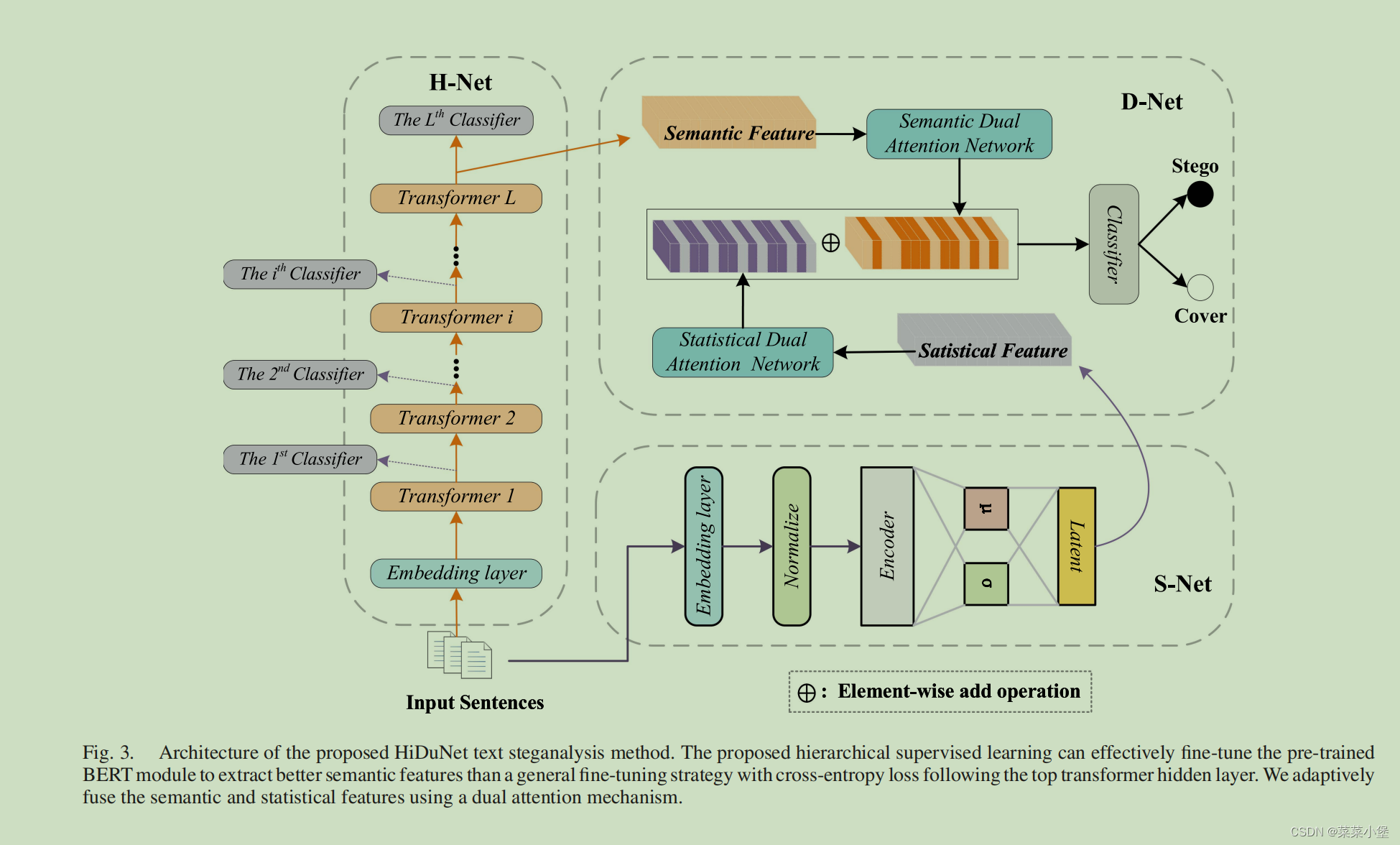
H-Net层
作者提出了两种不同的联合损失函数👇
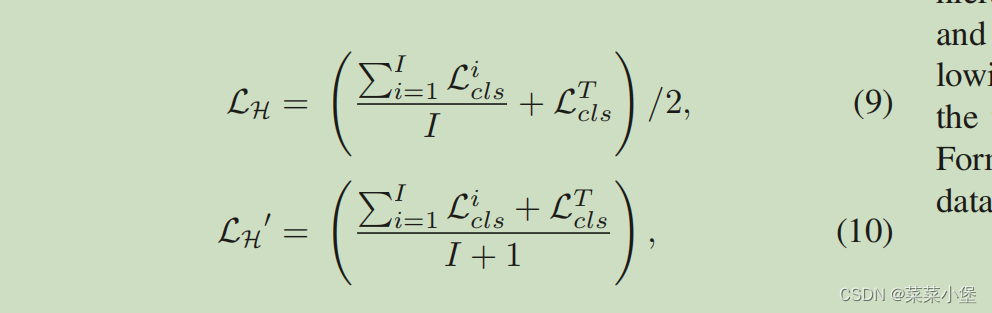
其中I的范围是[1,10] L表示的是第i哥softmax的分类的交叉熵损失函数。

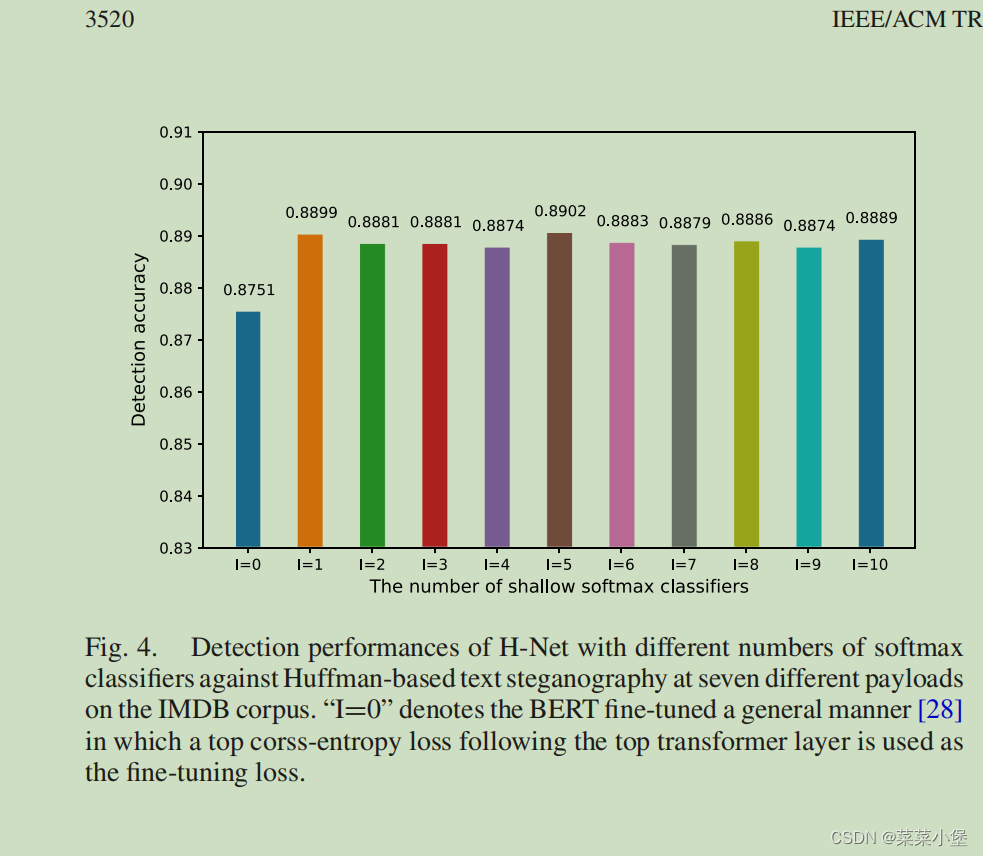
通过上图的对比可以明显看出 分层监督学习微调的BERT模型效果要明显优于一般微调的BERT模型。其中通过下图的实验可以表面I=5的情况是效果最好的。

通过上述所提起的有监督且分层训练(fine-tuning)的BERT来把x(语句)输入获取一些语义特征。
S-Net层
先讲解了自编码器(VAE)的内容VAE教程

其中方差和均值表示的是输入文本的···。Zi表示的是潜在空间的第i个向量。因此数据集的分布可以用q(Z)来表示。O表示输入空间,Z表示潜在空间。N表示整个数据集中句子的数量。
q(Z)作为VAE的encoder。
所以作者用VAE的编码器(encoder)来表示HiDuNet的生长文本隐写方法的统计失真(statistical distortion),构建了S-Net层(constructed with three dense layers)
** S-Net的作用**:由三个dense layers组成,用来学习cover和stego的mean和standard deviation。
用H-Net的embedding层放到VAE的编码器中,并用4个dense neural layers来估计 mean和standard。👇

接下来通过S-Net获得F_st
然后通过H-Net和S-Net来获得两个F(F_st and F_se)两个特征函数,然后提出来一个双向网络(dual attention network)D-Net
在 H-Net和S-Net两个网络得到的特征结果都增加一个双向注意力机制(H-Net是语义特征,S-Net是数据统计特征)
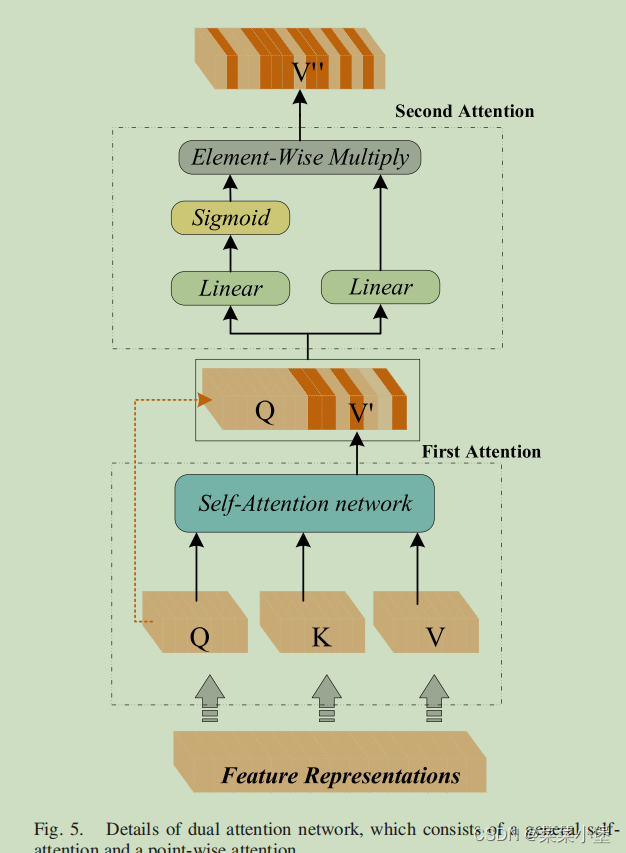

👆是dual attention network的第一层的结构,使用的正常的自注意力机制。
👇是dual attention network的第二层的结构,使用的一个线性层和一个sigmoid的函数。


最后进行一层线性层分布获取最终分类结果。
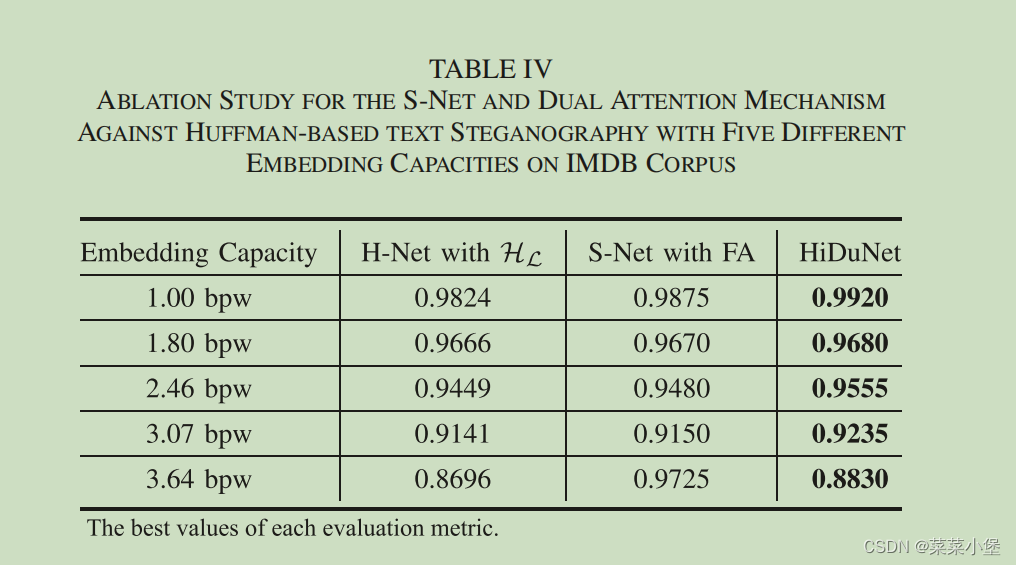
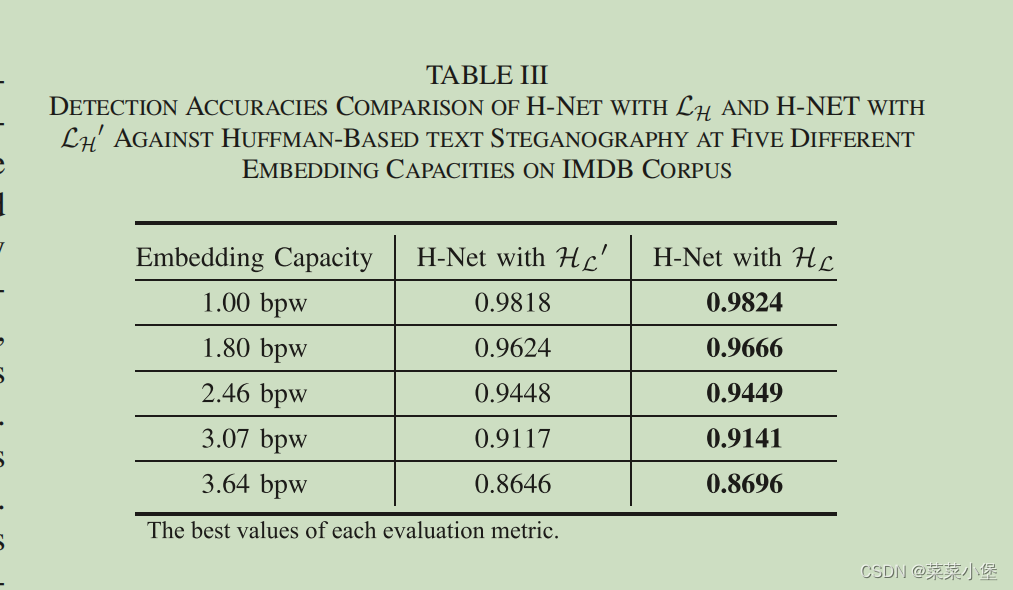
这个表中的效果是识别隐写文本的准确率, 第一列是H-net+有监督分层训练后的模型,第二列是在第一个模型上又加上了S-Net和第一层注意力机制(self-attention)后的结果,第三列是final-model的结果(又加上了第二层的注意力机制)。
实验和结果
第一种实验是一种具体的方法,我们可以知道相关文本隐写的细节信息,包括语料库、嵌入算法和嵌入能力。
使用了Huffman-based, Arithmetic-based, and ADG-based methods which are implemented on two
well-trained LSTM language models trained on Twitter [58] and IMDB [54] corpora。
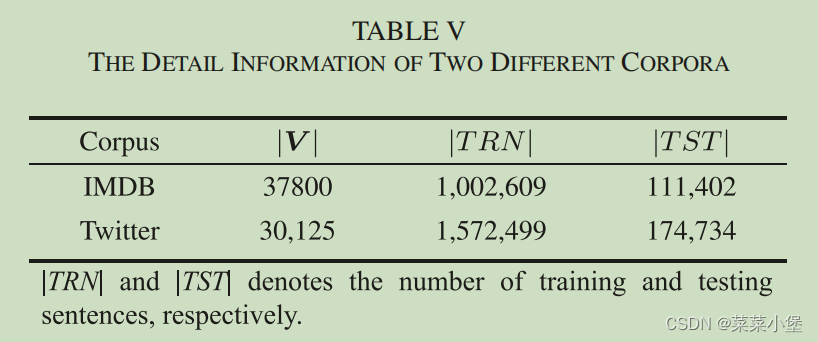
测试大概占训练的10%。
第二种实验是一些半盲加密文本(semi-blind text steganography),使用了SHA( we leveraged “BHA” dataset proposed
by Xue et al. [33])数据集,除了语料库类型外,我们不知道嵌入算法和嵌入能力的细节。数据集有BHA-Twitter,
BHA-IMDB, and BHA-News。
第三种实验是盲文本加密,使用了“Tstega-thu”,该数据集混合了几种生成的文本隐写方法和基于同义词替代的文本隐写方法。(杨震老师提出的数据集)。
对比加密文本
实验中测试了六种基于dnn的文本步分析方法,包括一种基于单一特征的方法(single-based method)、两种基于特征的混合方法(hybrid feature-based method)、一种基于图的方法(graph-based method)和两种基于transformer的方法(two transformer-based methods)。
1、LS-CNN方法引用自Convolutional neural network based text steganalysis论文。
2、Dense-LSTM方法引用自Linguistic steganalysis with graph neural networks论文。
3、R-BiLSTM-C方法引用自A hybrid R-BILSTM-C neural network based text steganalysis论文。
4、Sesy 方法引用自SeSy: Linguistic steganalysis framework integrating semantic and syntactic features论文。
5、BERT-FT 方法引用自Real-time text steganalysis based on multi-stage transfer learning论文。
6、ELM方法引用自Detection of generative linguistic steganography based on explicit and latent text word relation mining using deep learning 论文。
数据预处理和分析标准
对于第一种实验进行了20,000stego和cover句子进行训练。1000个setgo和cover进行验证。
对于第二种实验和第三种实验进行了95,000stego和cover(cover-stego pair)句子进行训练。训练集和验证集以及测试集比例为90:1:4。
实验结果有三项结果分类 Accuracy、Recall、Precision
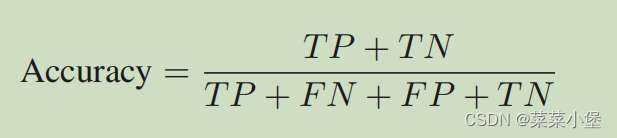

True Positive(TP):正确地将正类的样本识别为正类。
True Negative (TN):模型正确地将负类样本预测为负类。
False Positive (FP):模型错误地将负类样本预测为正类(也称为“假阳性”或“类型 I 错误”)。
False Negative (FN):模型错误地将正类样本预测为负类(也称为“假阴性”或“类型 II 错误”)。
具体配置和实验环境

实验结果
贴图实验清晰明显参照论文。

















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









