




 本文详细介绍了数据仓库DWD层的设计和实现,主要涉及交易域的加购、下单、取消订单、支付成功和退单事务事实表的分区规划、建表语句以及数据装载流程。DWD层依据维度建模理论,采用orc存储格式,通过增量分区策略进行数据组织。各事实表根据业务场景和数据流向进行设计,确保数据准确反映业务行为。
本文详细介绍了数据仓库DWD层的设计和实现,主要涉及交易域的加购、下单、取消订单、支付成功和退单事务事实表的分区规划、建表语句以及数据装载流程。DWD层依据维度建模理论,采用orc存储格式,通过增量分区策略进行数据组织。各事实表根据业务场景和数据流向进行设计,确保数据准确反映业务行为。
离线数仓—DWD层设计开发
前言
前面完成了DIM层维度表的设计和开发,下面进行额DWD层事实表的设计和开发。
一、DWD层设计分析
1.设计要点
1.1 设计依据
DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
1.2 存储格式
DWD层的数据存储格式为orc列式存储+snappy压缩
1.3 存储格式
DWD层表名的命名规范为:dwd_数据域_表名_单分区增量全量标识(inc/full)
二、DWD层实现
根据业务总线矩阵确定每个表里的字段。
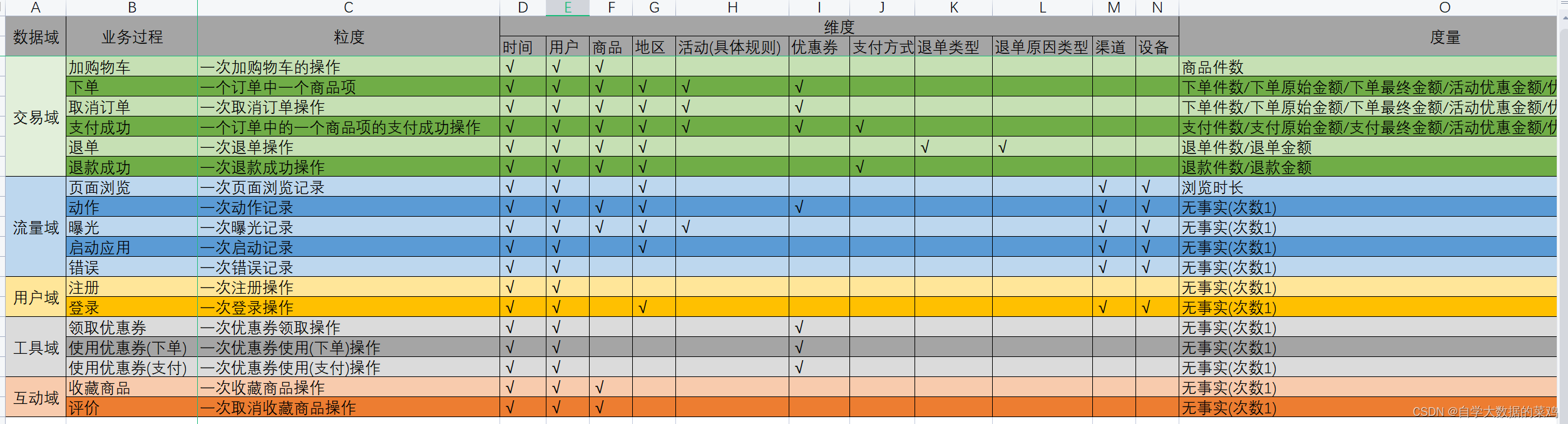
1.交易域加购事务事实表
1.1 分区规划分析
事实表一般情况下都是增量表,所以采用一天一个增量的分区规划。
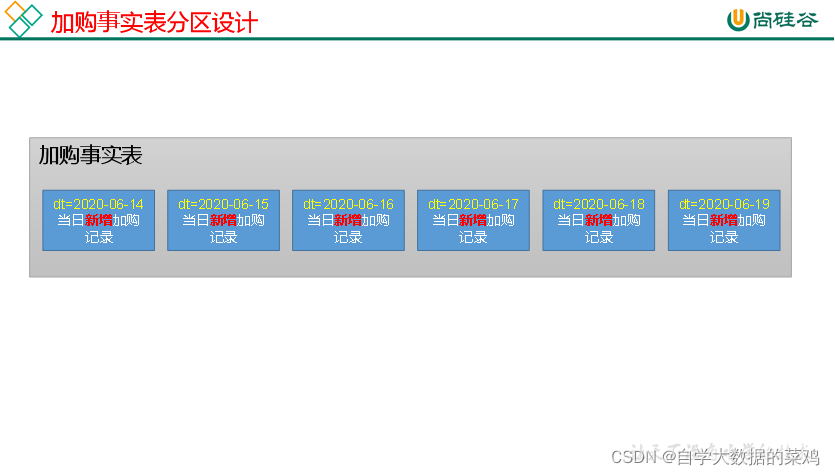
1.2 建表语句
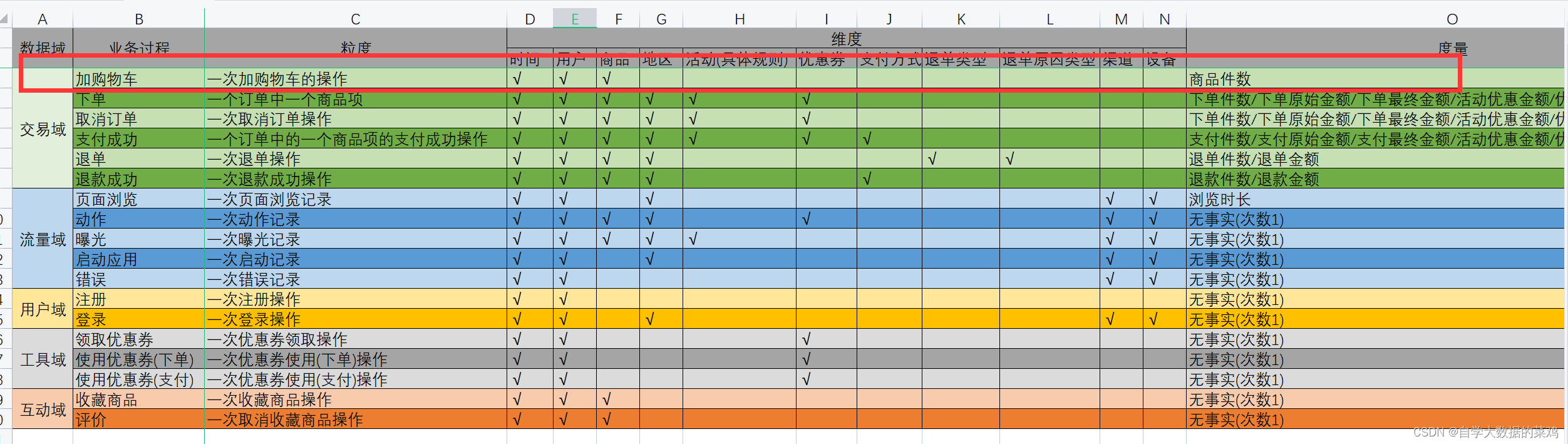
加购物车这个业务过程是一个用户一次把一种商品加入到购物车,所以它的维度有时间、用户、商品,还有度量值商品件数(隐藏度量值加购次数,一行相当于一次),建表语句如下:
DROP TABLE IF EXISTS dwd_trade_cart_add_inc;
CREATE EXTERNAL TABLE dwd_trade_cart_add_inc
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`date_id` STRING COMMENT '时间id',
`create_time` STRING COMMENT '加购时间',
`source_id` STRING COMMENT '来源类型ID',
`source_type_code` STRING COMMENT '来源类型编码',
`source_type_name` STRING COMMENT '来源类型名称',
`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域加购物车事务事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cart_add_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');
1.4 数据流向分析
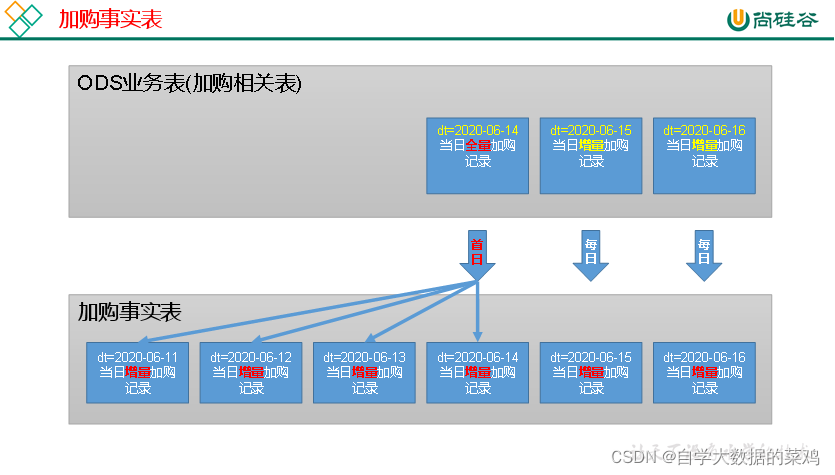
其实这个加购表一行数据并不不代表是一次加购操作,因为如果商品件数不为1的时候,可能是用户加购了多次该商品。这在平日的增量同步中可以很好的判断出来;但是在数仓首日时,如果没有初始的binlog记录,无法判断是几次,我们只能把一行数据代表是一次加购操作。
在首日时,业务数据库中可能有多日的数据,我们根据创建时间这一列获取加购的时间,把对应的数据放到日期对应的分区。
在平时时,当天的增量数据获取到的加购操作直接就放到当日日期的文件夹中即可。
1.5 首日数据装载
首日时,表中可能存在多天的业务数据,我们要根据create_time将对应日期的数据放到对应的分区。
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cart_add_inc partition (dt)
select
id,
user_id,
sku_id,
date_format(create_time,'yyyy-MM-dd') date_id,
create_time,
source_id,
source_type,
dic.dic_name,
sku_num,
date_format(create_time, 'yyyy-MM-dd')
from
(
select
data.id,
data.user_id,
data.sku_id,
data.create_time,
data.source_id,
data.source_type,
data.sku_num
from ods_cart_info_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
)ci
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='24'
)dic
on ci.source_type=dic.dic_code;
注意:开启非严格模式;
1.6 每日数据装载
insert overwrite table dwd_trade_cart_add_inc partition(dt='2020-06-15')
select
id,
user_id,
sku_id,
date_id,
create_time,
source_id,
source_type_code,
source_type_name,
sku_num
from
(
select
data.id,
data.user_id,
data.sku_id,
date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd') date_id,
date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd HH:mm:ss') create_time,
data.source_id,
data.source_type source_type_code,
if(type='insert',data.sku_num,data.sku_num-old['sku_num']) sku_num
from ods_cart_info_inc
where dt='2020-06-15'
and (type='insert'
or(type='update' and old['sku_num'] is not null and data.sku_num>cast(old['sku_num'] as int)))
)cart
left join
(
select
dic_code,
dic_name source_type_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='24'
)dic
on cart.source_type_code=dic.dic_code;
需要注意的地方:
1)每日数据中有insert和update两种类型的数据,我们要找到所有insert的数据,以及update中修改了sku_num且修改后数量增加的数据,其中old是一个Map<STRING,STRING>类型的数据,所以要转化为int类型
type='insert'or(type='update' and old['sku_num'] is not null and data.sku_num>cast(old['sku_num'] as int))
2)时间问题。对于insert类型的数据,create_time就是加购的时间,同时它的operate_time为null;而对于update类型的数据,create_time是第一次加购的时间,而不是本次加购的时间,它的operate_time才是本次加购的时间,因此同时获取两种数据的时候,没办法使用create_time或operate_time来确定加购时间。
获取加购时间的方式:第一种是使用ods_cart_info_inc里的ts字段,这个字段就是发生变化的时间,但是这是以秒为单位的,在转换时要注意。
date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd') date_id,
date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd HH:mm:ss') create_time,
第二种是用if判断如果是insert,就取它的create_time字段;如果是update就取它的operate_time字段(在子查询里要把create_time和operate_time都选到)
if(type='insert',date_format(create_time,'yyyy-MM-dd'),date_format(operate_time,'yyyy-MM-dd')) date_id
if(type='insert',create_time,operate_time) create_time
3)sku_num问题。对于insert数据,sku_num就是该次加购的商品件数,对于update数据,data里的sku_num减去old里的sku_num才是该次加购商品件数(int减string类型数据可以不转换)。
if(type='insert',data.sku_num,data.sku_num-old['sku_num']) sku_num
2.交易域下单事务事实表
2.1 分区规划分析
分区规划跟加购事实表一样,一天一个增量分区
2.2 建表语句
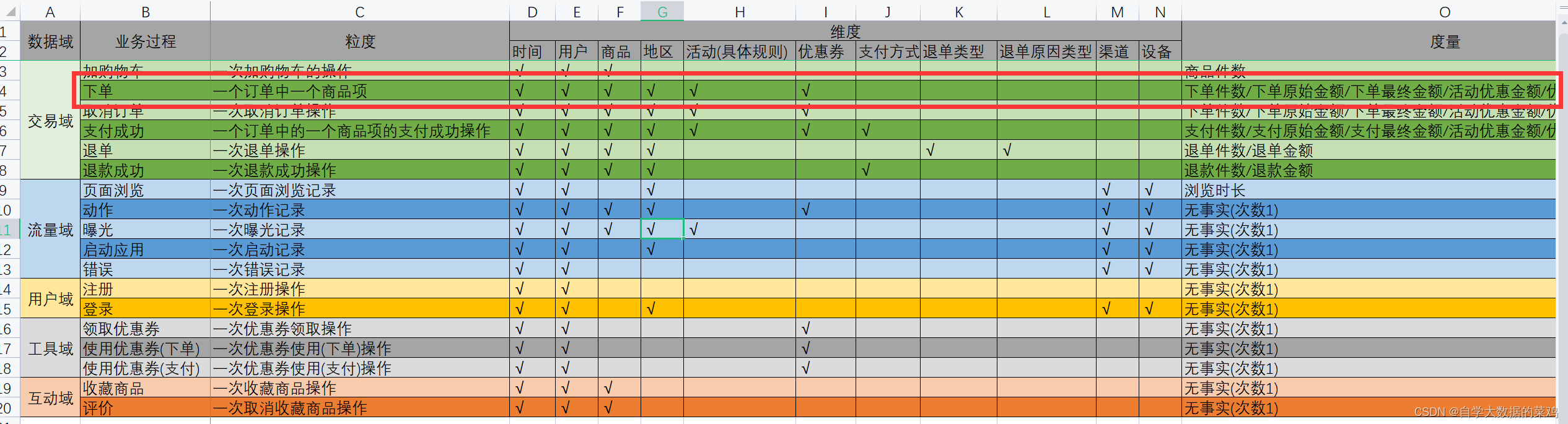
下单这个业务过程的粒度是一个订单中的一个商品项,它的维度有时间、用户、商品、地区、活动、优惠券,度量值有商品件数、商品原始金额、商品最终金额、活动优惠金额、优惠券优惠金额。
建表语句如下:
DROP TABLE IF EXISTS dwd_trade_order_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_order_detail_inc
(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单id',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`province_id` STRING COMMENT '省份id',
`activity_id` STRING COMMENT '参与活动规则id',
`activity_rule_id` STRING COMMENT '参与活动规则id',
`coupon_id` STRING COMMENT '使用优惠券id',
`date_id` STRING COMMENT '下单日期id',
`create_time` STRING COMMENT '下单时间',
`source_id` STRING COMMENT '来源编号',
`source_type_code` STRING COMMENT '来源类型编码',
`source_type_name` STRING COMMENT '来源类型名称',
`sku_num` BIGINT COMMENT '商品数量',
`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',
`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',
`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',
`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域下单明细事务事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_order_detail_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');
2.3 首日装载
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_order_detail_inc partition (dt)
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_format(create_time, 'yyyy-MM-dd') date_id,
create_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount,
date_format(create_time,'yyyy-MM-dd')
from
(
select
data.id,
data.order_id,
data.sku_id,
data.create_time,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) od
left join
(
select
data.id,
data.user_id,
data.province_id
from ods_order_info_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
2.4 每日装载
ods层的ods_order_detail_inc表里的数据都是每日变更数据,但是这个表里的type类型只有insert,即所有的数据都是新增数据,把当日数据全部插入到dwd层对应当日的表中即可。
insert overwrite table dwd_trade_order_detail_inc partition (dt='2020-06-15')
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_id,
create_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount
from
(
select
data.id,
data.order_id,
data.sku_id,
date_format(data.create_time, 'yyyy-MM-dd') date_id,
data.create_time,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where dt = '2020-06-15'
and type = 'insert'
) od
left join
(
select
data.id,
data.user_id,
data.province_id
from ods_order_info_inc
where dt = '2020-06-15'
and type = 'insert'
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where dt = '2020-06-15'
and type = 'insert'
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where dt = '2020-06-15'
and type = 'insert'
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
3.交易域取消订单事实表
首先说明,取消订单是完完全全的取消,把订单里的所有商品都取消,而不能取消一部分。
3.1 建表语句
业务总线矩阵如下图:
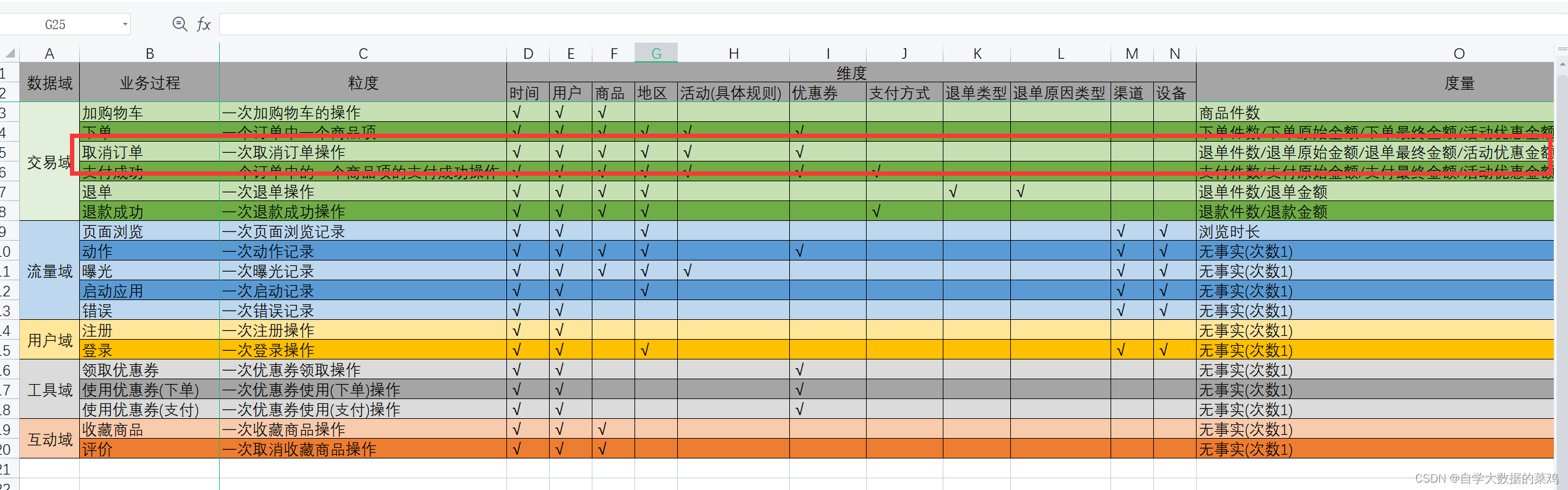
取消订单业务其实和下单业务里的表差不多,这个一行是一个用户取消了一个商品项,下单一行数据是一个用户下单了一个商品项,这里的下单件数改为退单件数,因此建表语句如下:
DROP TABLE IF EXISTS dwd_trade_cancel_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_cancel_detail_inc
(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单id',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`province_id` STRING COMMENT '省份id',
`activity_id` STRING COMMENT '参与活动规则id',
`activity_rule_id` STRING COMMENT '参与活动规则id',
`coupon_id` STRING COMMENT '使用优惠券id',
`date_id` STRING COMMENT '取消订单日期id',
`cancel_time` STRING COMMENT '取消订单时间',
`source_id` STRING COMMENT '来源编号',
`source_type_code` STRING COMMENT '来源类型编码',
`source_type_name` STRING COMMENT '来源类型名称',
`sku_num` BIGINT COMMENT '商品数量',
`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',
`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',
`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',
`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域取消订单明细事务事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_cancel_detail_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.2 首日数据装载
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cancel_detail_inc partition (dt)
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_format(canel_time,'yyyy-MM-dd') date_id,
canel_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount,
date_format(canel_time,'yyyy-MM-dd')
from
(
select
data.id,
data.order_id,
data.sku_id,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) od
join
(
select
data.id,
data.user_id,
data.province_id,
data.operate_time canel_time
from ods_order_info_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
and data.order_status='1003'
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
装载语句说明:
1)如何获取取消订单的数据:在order_info这个表中有一个字段order_status,它为1003时代表订单已取消。因为首日时order_info都是插入的数据,所以直接根据order_status=1003获取首日中取消订单的数据
2)其它字段怎么获取:其它的字段大部分是从order_detail_info获取的,所以需要这两个表进行关联。有两种关联方式,第一种是inner join,可以获取双方都存在的数据;第二种是把order_info筛选出来的取消订单的数据放到左边,跟order_detail_info的数据进行left join(筛选出来的订单不可能订单明细里没有吧,除非数据有问题!!!)
3)退单时间的确定:退单时间直接使用order_info里的operate_time即可,因为在取消订单这个操作之后,没有其他的操作了,那些取消订单的操作的operate_time是最后一次操作的时间,也必是取消订单的时间。
3.3 每日数据装载
insert overwrite table dwd_trade_cancel_detail_inc partition (dt='2020-06-15')
select
od.id,
order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
date_format(canel_time,'yyyy-MM-dd') date_id,
canel_time,
source_id,
source_type,
dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount
from
(
select
data.id,
data.order_id,
data.sku_id,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where (dt='2020-06-15' or dt=date_add('2020-06-15',-1))
and (type = 'insert' or type= 'bootstrap-insert')
) od
join
(
select
data.id,
data.user_id,
data.province_id,
data.operate_time canel_time
from ods_order_info_inc
where dt = '2020-06-15'
and type = 'update'
and data.order_status='1003'
and array_contains(map_keys(old),'order_status')
) oi
on order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where (dt='2020-06-15' or dt=date_add('2020-06-15',-1))
and (type = 'insert' or type= 'bootstrap-insert')
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where (dt='2020-06-15' or dt=date_add('2020-06-15',-1))
and (type = 'insert' or type= 'bootstrap-insert')
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='24'
)dic
on od.source_type=dic.dic_code;
每日装载语句说明:
1)如何获取取消订单的数据:每日装载时,order_info的变更数据中有insert和update操作,insert操作都是下单的数据,所以我们要获取update操作的数据,并且这些数据中修改的值包含order_status这个字段,且修改后的值为1003(实际上只需要确定type=update且order_status=1003即可)。
2)跟订单明细表的关联:当天取消的订单可能是前一天下的单,那么这个订单的明细表中的数据可能在前一天,所以跟订单明细表关联的时候要选择前一天和今天两天的数据。订单明细表的数据一旦插入,后面是不会发生变化的,即表中只有insert和bootstrap类型的数据,所以可以不写type,若是写type,要改成insert or bootstrap。
4.交易域支付成功事务事实表
4.1建表语句
表的字段依旧根据业务总线矩阵确定…
DROP TABLE IF EXISTS dwd_trade_pay_detail_suc_inc;
CREATE EXTERNAL TABLE dwd_trade_pay_detail_suc_inc
(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单id',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT '商品id',
`province_id` STRING COMMENT '省份id',
`activity_id` STRING COMMENT '参与活动规则id',
`activity_rule_id` STRING COMMENT '参与活动规则id',
`coupon_id` STRING COMMENT '使用优惠券id',
`payment_type_code` STRING COMMENT '支付类型编码',
`payment_type_name` STRING COMMENT '支付类型名称',
`date_id` STRING COMMENT '支付日期id',
`callback_time` STRING COMMENT '支付成功时间',
`source_id` STRING COMMENT '来源编号',
`source_type_code` STRING COMMENT '来源类型编码',
`source_type_name` STRING COMMENT '来源类型名称',
`sku_num` BIGINT COMMENT '商品数量',
`split_original_amount` DECIMAL(16, 2) COMMENT '应支付原始金额',
`split_activity_amount` DECIMAL(16, 2) COMMENT '支付活动优惠分摊',
`split_coupon_amount` DECIMAL(16, 2) COMMENT '支付优惠券优惠分摊',
`split_payment_amount` DECIMAL(16, 2) COMMENT '支付金额'
) COMMENT '交易域成功支付事务事实表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_pay_detail_suc_inc/'
TBLPROPERTIES ('orc.compress' = 'snappy');
4.2 首日数据装载
首日装载时,ods层里的支付表也可能存在很多天的记录,我们根据支付状态选取支付成功的数据,再用order_id跟order_detail_info等表进行关联获得所需的字段。
insert overwrite table dwd_trade_pay_detail_suc_inc partition (dt)
select
od.id,
od.order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
payment_type,
pay_dic.dic_name,
date_format(callback_time,'yyyy-MM-dd') date_id,
callback_time,
source_id,
source_type,
src_dic.dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount,
date_format(callback_time,'yyyy-MM-dd')
from
(
select
data.id,
data.order_id,
data.sku_id,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) od
join
(
select
data.user_id,
data.order_id,
data.payment_type,
data.callback_time
from ods_payment_info_inc
where dt='2020-06-14'
and type='bootstrap-insert'
and data.payment_status='1602'
) pi
on od.order_id=pi.order_id
left join
(
select
data.id,
data.province_id
from ods_order_info_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where dt = '2020-06-14'
and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='11'
) pay_dic
on pi.payment_type=pay_dic.dic_code
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='24'
)src_dic
on od.source_type=src_dic.dic_code;
首日装载语句说明:
1)支付成功数据的获取:ods层的payment_info表中的payment_status为1602时,代表是支付成功,所以直接在2020-06-14这个分区获取type='bootstrap-insert’且payment_status=1602的数据即可
2)支付成功时间的确定:payment_info表中的回调时间callback_time就是支付成功的时间
3)字典表的使用:这个dwd表中有两个编码字段,因此需要join两次字典表
4)left join和inner join:payment_info表和order_detail_info表的join类型选择,其实我认为这里left join和inner join效果一样,因为payment_info表是支付表,支付表存在的order_id肯定在订单表里也有,订单表里的order_id肯定在明细表里有,所以所有的支付成功的order_id都能在订单明细表找到对应的数据,可以把payment_info当作左表,把order_detail_info当作右表进行left join。
4.3 每日数据装载
insert overwrite table dwd_trade_pay_detail_suc_inc partition (dt='2020-06-15')
select
od.id,
od.order_id,
user_id,
sku_id,
province_id,
activity_id,
activity_rule_id,
coupon_id,
payment_type,
pay_dic.dic_name,
date_format(callback_time,'yyyy-MM-dd') date_id,
callback_time,
source_id,
source_type,
src_dic.dic_name,
sku_num,
split_original_amount,
split_activity_amount,
split_coupon_amount,
split_total_amount
from
(
select
data.id,
data.order_id,
data.sku_id,
data.source_id,
data.source_type,
data.sku_num,
data.sku_num * data.order_price split_original_amount,
data.split_total_amount,
data.split_activity_amount,
data.split_coupon_amount
from ods_order_detail_inc
where (dt = '2020-06-15' or dt = date_add('2020-06-15',-1))
and (type = 'insert' or type = 'bootstrap-insert')
) od
join
(
select
data.user_id,
data.order_id,
data.payment_type,
data.callback_time
from ods_payment_info_inc
where dt='2020-06-15'
and type='update'
and array_contains(map_keys(old),'payment_status')
and data.payment_status='1602'
) pi
on od.order_id=pi.order_id
left join
(
select
data.id,
data.province_id
from ods_order_info_inc
where (dt = '2020-06-15' or dt = date_add('2020-06-15',-1))
and (type = 'insert' or type = 'bootstrap-insert')
) oi
on od.order_id = oi.id
left join
(
select
data.order_detail_id,
data.activity_id,
data.activity_rule_id
from ods_order_detail_activity_inc
where (dt = '2020-06-15' or dt = date_add('2020-06-15',-1))
and (type = 'insert' or type = 'bootstrap-insert')
) act
on od.id = act.order_detail_id
left join
(
select
data.order_detail_id,
data.coupon_id
from ods_order_detail_coupon_inc
where (dt = '2020-06-15' or dt = date_add('2020-06-15',-1))
and (type = 'insert' or type = 'bootstrap-insert')
) cou
on od.id = cou.order_detail_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='11'
) pay_dic
on pi.payment_type=pay_dic.dic_code
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='24'
)src_dic
on od.source_type=src_dic.dic_code;
每日数据装载说明:
payment_info里的payment_status字段的含义:在用户点击完支付按钮后,往payment_info中插入一条数据,这时的payment_status字段的值是1601,表示已支付在等待回调结果;当值为1602时,表示已支付成功;当值为1603时,表示支付失败。
1)支付成功数据的获取:每日装载中,根据payment_info这个表的特点,可以得知这一天中的数据既有insert(值为1601),也有update(值为1602或1603),因此我们要找到type='update’且payment_status=1602的数据,这拿到的时当天的支付成功的数据
2)与order_detail_info的关联:同之前一样,既可以用left join也可以用inner join,同时order_detail_info里的数据是当天新增的明细数据,但是支付的订单可能是前一天的订单,那么订单明细也是前一天的,所以时间应该选取当天和前一天,type='insert’或type=‘bootstrap-insert’。
3)与orderl_info的关联:跟上面一样,支付的订单可能是前一天的订单,所以时间应该选取当天和前一天,type='insert’或type=‘bootstrap-insert’。
4)其他表的关联:活动明细表和优惠券明细表跟订单表一样,也是跟订单表数据一起产生的,因此也要两天内的数据,字典表是全量表,既然在2020-06-15日支付成功,那就用2020-06-15的全量表数据。
5.交易域退单事务事实表
5.1 建表语句
DROP TABLE IF EXISTS dwd_trade_order_refund_inc;
CREATE EXTERNAL TABLE dwd_trade_order_refund_inc
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户ID',
`order_id` STRING COMMENT '订单ID',
`sku_id` STRING COMMENT '商品ID',
`province_id` STRING COMMENT '地区ID',
`date_id` STRING COMMENT '日期ID',
`create_time` STRING COMMENT '退单时间',
`refund_type_code` STRING COMMENT '退单类型编码',
`refund_type_name` STRING COMMENT '退单类型名称',
`refund_reason_type_code` STRING COMMENT '退单原因类型编码',
`refund_reason_type_name` STRING COMMENT '退单原因类型名称',
`refund_reason_txt` STRING COMMENT '退单原因描述',
`refund_num` BIGINT COMMENT '退单件数',
`refund_amount` DECIMAL(16, 2) COMMENT '退单金额'
) COMMENT '交易域退单事务事实表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_order_refund_inc/'
TBLPROPERTIES ("orc.compress" = "snappy");
5.2 首日装载语句
insert overwrite table dwd_trade_order_refund_inc partition(dt)
select
ri.id,
user_id,
order_id,
sku_id,
province_id,
date_format(create_time,'yyyy-MM-dd') date_id,
create_time,
refund_type,
type_dic.dic_name,
refund_reason_type,
reason_dic.dic_name,
refund_reason_txt,
refund_num,
refund_amount,
date_format(create_time,'yyyy-MM-dd')
from
(
select
data.id,
data.user_id,
data.order_id,
data.sku_id,
data.refund_type,
data.refund_num,
data.refund_amount,
data.refund_reason_type,
data.refund_reason_txt,
data.create_time
from ods_order_refund_info_inc
where dt='2020-06-14'
and type='bootstrap-insert'
)ri
left join
(
select
data.id,
data.province_id
from ods_order_info_inc
where dt='2020-06-14'
and type='bootstrap-insert'
)oi
on ri.order_id=oi.id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code = '15'
)type_dic
on ri.refund_type=type_dic.dic_code
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code = '13'
)reason_dic
on ri.refund_reason_type=reason_dic.dic_code;
首日装载语句说明:
1)获取退单的数据:退单表中不管退单的状态是什么,每一行都是一个退单的数据,所以在第一天所有的bootstrap-insert数据都是退单数据
2)退单的时间:退单表中的create_time字段就是退单时间
3)表的关联:与order_info表进行关联时,拿的也是ods层所有的订单表的数据(很多天的数据)
5.3 每日装载语句
insert overwrite table dwd_trade_order_refund_inc partition(dt='2020-06-15')
select
ri.id,
user_id,
order_id,
sku_id,
province_id,
date_format(create_time,'yyyy-MM-dd') date_id,
create_time,
refund_type,
type_dic.dic_name,
refund_reason_type,
reason_dic.dic_name,
refund_reason_txt,
refund_num,
refund_amount
from
(
select
data.id,
data.user_id,
data.order_id,
data.sku_id,
data.refund_type,
data.refund_num,
data.refund_amount,
data.refund_reason_type,
data.refund_reason_txt,
data.create_time
from ods_order_refund_info_inc
where dt='2020-06-15'
and type='insert'
)ri
left join
(
select
data.id,
data.province_id
from ods_order_info_inc
where dt='2020-06-15'
and type='update'
and data.order_status='1005'
and array_contains(map_keys(old),'order_status')
)oi
on ri.order_id=oi.id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code = '15'
)type_dic
on ri.refund_type=type_dic.dic_code
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code = '13'
)reason_dic
on ri.refund_reason_type=reason_dic.dic_code;
每日装载语句说明:
1)获取退单数据:退单表每日的变更数据包括两部分,一部分时type=‘insert’,这部分的数据全都是新增的数据,即都是新增的退单数据;另一部分是type=‘update’,这部分的数据是修改退单状态的,但是这个原本的退单数据已经存在,所以这部分不需要。
2)退单的时间:退单表中type='insert’数据的create_time字段就是退单时间
3)表的关联:当新增一条退单数据时,order_info表的order_status会发生变化,因此order_info表同时也会产生变更数据且类型为type=‘update’。所以哪一天的退单数据可以根据order_info表的update里的order_status=1005来获取修改的order_info数据,所以order_info表的时间就是当天。
6.交易域退款成功事务事实表
6.1 每日装载语句
DROP TABLE IF EXISTS dwd_trade_refund_pay_suc_inc;
CREATE EXTERNAL TABLE dwd_trade_refund_pay_suc_inc
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户ID',
`order_id` STRING COMMENT '订单编号',
`sku_id` STRING COMMENT 'SKU编号',
`province_id` STRING COMMENT '地区ID',
`payment_type_code` STRING COMMENT '支付类型编码',
`payment_type_name` STRING COMMENT '支付类型名称',
`date_id` STRING COMMENT '日期ID',
`callback_time` STRING COMMENT '支付成功时间',
`refund_num` DECIMAL(16, 2) COMMENT '退款件数',
`refund_amount` DECIMAL(16, 2) COMMENT '退款金额'
) COMMENT '交易域提交退款成功事务事实表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dwd/dwd_trade_refund_pay_suc_inc/'
TBLPROPERTIES ("orc.compress" = "snappy");
6.2 首日装载语句
insert overwrite table dwd_trade_refund_pay_suc_inc partition(dt)
select
rp.id,
user_id,
rp.order_id,
rp.sku_id,
province_id,
payment_type,
dic_name,
date_format(callback_time,'yyyy-MM-dd') date_id,
callback_time,
refund_num,
total_amount,
date_format(callback_time,'yyyy-MM-dd')
from
(
select
data.id,
data.order_id,
data.sku_id,
data.payment_type,
data.callback_time,
data.total_amount
from ods_refund_payment_inc
where dt='2020-06-14'
and type = 'bootstrap-insert'
and data.refund_status='1602'
)rp
left join
(
select
data.id,
data.user_id,
data.province_id
from ods_order_info_inc
where dt='2020-06-14'
and type='bootstrap-insert'
)oi
on rp.order_id=oi.id
left join
(
select
data.order_id,
data.sku_id,
data.refund_num
from ods_order_refund_info_inc
where dt='2020-06-14'
and type='bootstrap-insert'
)ri
on rp.order_id=ri.order_id
and rp.sku_id=ri.sku_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='11'
)dic
on rp.payment_type=dic.dic_code;
首日装载语句说明:
1)退款成功数据获取:refund_payment表中全是insert字段,我们根据refund_status的值获取退款成功的数据
2)与order_detail_info表的关联:关联字段是order_id+sku_id
6.3 每日装载语句
insert overwrite table dwd_trade_refund_pay_suc_inc partition(dt='2020-06-15')
select
rp.id,
user_id,
rp.order_id,
rp.sku_id,
province_id,
payment_type,
dic_name,
date_format(callback_time,'yyyy-MM-dd') date_id,
callback_time,
refund_num,
total_amount
from
(
select
data.id,
data.order_id,
data.sku_id,
data.payment_type,
data.callback_time,
data.total_amount
from ods_refund_payment_inc
where dt='2020-06-15'
and type = 'update'
and array_contains(map_keys(old),'refund_status')
and data.refund_status='1602'
)rp
left join
(
select
data.id,
data.user_id,
data.province_id
from ods_order_info_inc
where dt='2020-06-15'
and type='update'
and data.order_status='1006'
and array_contains(map_keys(old),'order_status')
)oi
on rp.order_id=oi.id
left join
(
select
data.order_id,
data.sku_id,
data.refund_num
from ods_order_refund_info_inc
where dt='2020-06-15'
and type='update'
and data.refund_status='0705'
and array_contains(map_keys(old),'refund_status')
)ri
on rp.order_id=ri.order_id
and rp.sku_id=ri.sku_id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-15'
and parent_code='11'
)dic
on rp.payment_type=dic.dic_code;
每日装载语句说明:
1)退款成功数据的获取:从当日变更数据中找到type='update’且修改了refund_status字段且修改后的值为退单成功的值
2)关联表的数据获取:当日退款成功数据每新增一条,order_info(order_refund)中的order_status(refund_status)也会发生相应的改变,所以退单成功的order(order_refund)信息从当日的变更数据中就能够找到,我们找到type='update’且order_status(refund_status)修改了且修改后的值为退款完成的值。

















 3302
3302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









