



作者:孟硕
导读:
在 AI 大模型与数据基础设施不断融合的趋势下,企业对数据平台的使用方式也在不断演进。MCP Server 作为桥接 AI 能力与 Lakehouse 平台的关键能力,可以大幅提升数据处理自动化水平。
本文将围绕 6 个典型场景,介绍如何利用云器Lakehouse及其 MCP Server 将 AI 的灵活性与 Lakehouse 的数据统一能力结合,从而实现数据采集、分析、治理与知识构建的智能化闭环。
场景一:爬虫数据直接入仓分析
1.1 场景举例
这个场景我们的目标是调研芯片厂商的产品,浏览目标网站想要爬取数据并做数据分析出具报告。
1.2 传统方式
- 技术门槛高,需专业编程与数据处理技能;
- 流程繁琐周期长,从抓取到分析耗时费力。
1.3 云器的方式Demo
涉及产品功能: Lakehouse + Firecrawl(外部 AI 爬虫工具的 MCP Server)
自然语言指令:
请从下面的网站中,爬取产品信息、尺寸、类型、功能介绍等必要的信息,并写入 Lakehouse的表中 https://www.espressif.com/zh-hans/products/socs
1.4 价值
Lakehouse 基于增量计算的一体化引擎,通过 MCP 协议 与 AI 生态工具集成,实现仅凭一句自然语言指令,就能启动数据爬取、完成数据入仓并快速获取业务洞察,使得无论是业务人员还是数据分析师,都能轻松上手,即刻从数据中挖掘价值。
场景二:非结构化数据入湖构建知识库(用PDF/图片构建知识库)
2.1 场景举例
这个场景我们的目标是,从已经成功爬取并结构化的信息中,提取 PDF 文档的 URL,将其切片、向量化到知识库表,进入竞品调研的知识库。
2.2 传统方式
- 技术复杂: 需手动编程提取URL -> 下载并上传 -> 文档切片 -> 向量化 -> 构建索引;
- 低效易错: 批量处理效率低下,易因网络或文件问题中断。脚本还需持续维护,成本高且准确性难保。
2.3 云器的方式Demo
涉及产品功能:云器 Lakehouse AI 工作流、 AI 函数 、 向量 、倒排索引。
自然语言指令:
请根据表 espressif_products 的 volume_file_path 字段指定的 PDF 文件,构建成知识库
请帮我验证一下这个知识库 :espressif_products_knowledge_bas
化繁为简,智能入湖新体验! MCP 客户端与数据平台服务器的强强联合,只需向 MCP 服务器发出自然语言指令,系统便能自动批量抓取这些 PDF 文件,并将其高效、准确地上传至您的云器 Lakehouse USER VOLUME。
另:利用Lakehouse AI 函数处理图片以及 Emmbeding 的例子
自然语言指令:
请帮我把下面 URL中的图片,上传到 Lakehouse USER VOLUME 的 dish_images 子目录并建表,包含 id、url、图片内容、图片向量(vector(float,1024)) 及其他必要字段。 用: public.fc_image_to_text('dish_recognition', 'url') 提取图片中的菜品信息存入‘图片内容’列 用:public.fc_gen_emmbeding('multimodal', '', 'url') 生成图片向量存入‘图片向量’列。
图片的 URL:http://viapi-test.oss-cn-shanghai.aliyuncs.com/viapi-3.0domepic/imagerecog/RecognizeFood/RecognizeFood5.jpg
其它图片的地址请根据提供的自行推测
2.4 价值
借助云器 Lakehouse 强大的 AI 函数能力,企业能够无缝调用业界最先进的 AI 模型,将非结构化数据(如图片)批量转化为可分析的关键信息与特征向量。这一能力不仅是实现“以图搜图”应用的核心,为释放数据价值创造了关键前提。
场景三:利用 Lakehouse 做多模态检索(以图搜图)
3.1 场景举例
用样例图片,搜索相似菜品
3.2 传统方式
因为传统数据平台不适合高维向量的相似性搜索,图片等非结构化数据,经模型转换后的特征向量,则必须存入专门的向量数据库(如Milvus)进行索引当需要混合检索时,应用层需先在向量库中进行相似性搜索,获得候选图片ID,再返回数据平台,与主数据进行关联查询。这种跨系统查询与数据整合,不仅显著增加了架构、运维和数据同步的复杂度,也带来了查询延迟。
3.3 云器的方式Demo
涉及产品功能:基于云器 Lakehouse 弹性计算框架的多模检索能力
自然语言指令:
请帮我搜索一下这张图片相似的两张图片(给出了图片的 URL)
背后的处理逻辑:
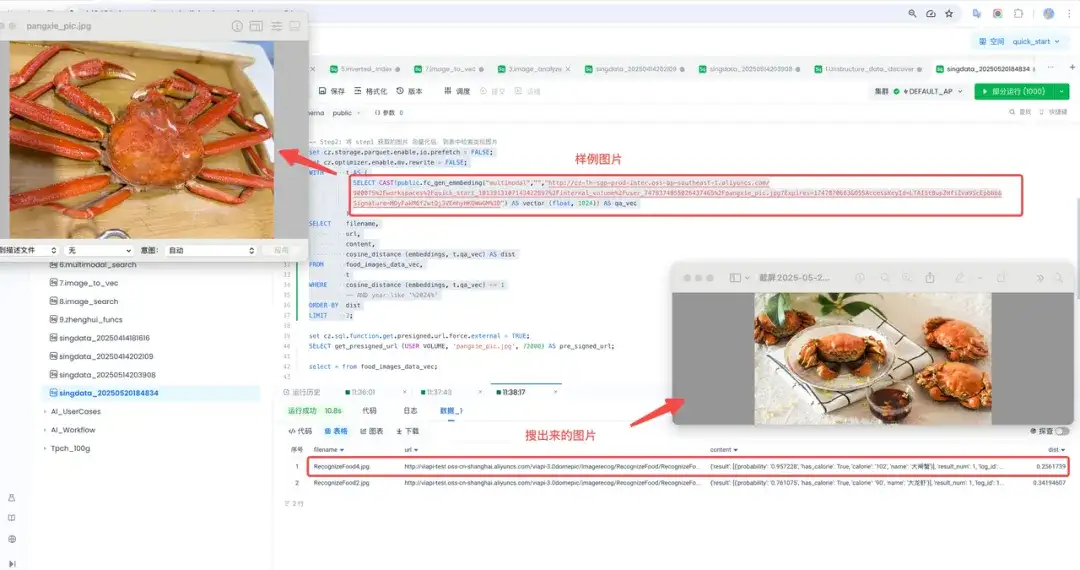
3.4 价值
云器 Lakehouse 平台融合了全面的多模态数据处理与智能检索能力,原生支持高维向量的高效存储、索引与检索,同时创新性地提供统一 SQL 接口,实现向量操作与传统 SQL 查询的混合检索。再通过与 MCP Server 的深度集成,系统能够将自然语言指令转化为精准的"以图搜图"体验,使得复杂的视觉搜索需求得以简洁实现,彻底消除了传统架构中的数据割裂与查询延迟问题。
场景四:与DataGPT指标平台配合使用,提高指标级的分析准确度
4.1 场景举例
这个场景我们的目标是,DataGPT 中已经构建了客户运营数据的关键指标(如:分货数量、确认明细等),我们需要回答用户关于关键指标的问答和深入探索
💡云器的 DataGPT,Lakehouse DataGPT 是新一代对话式数据分析工具,详情请查看:
4.2 云器DataGPT Demo
使用云器 Lakehouse DataGPT:指标平台、自动化数据治理、知识库服务。
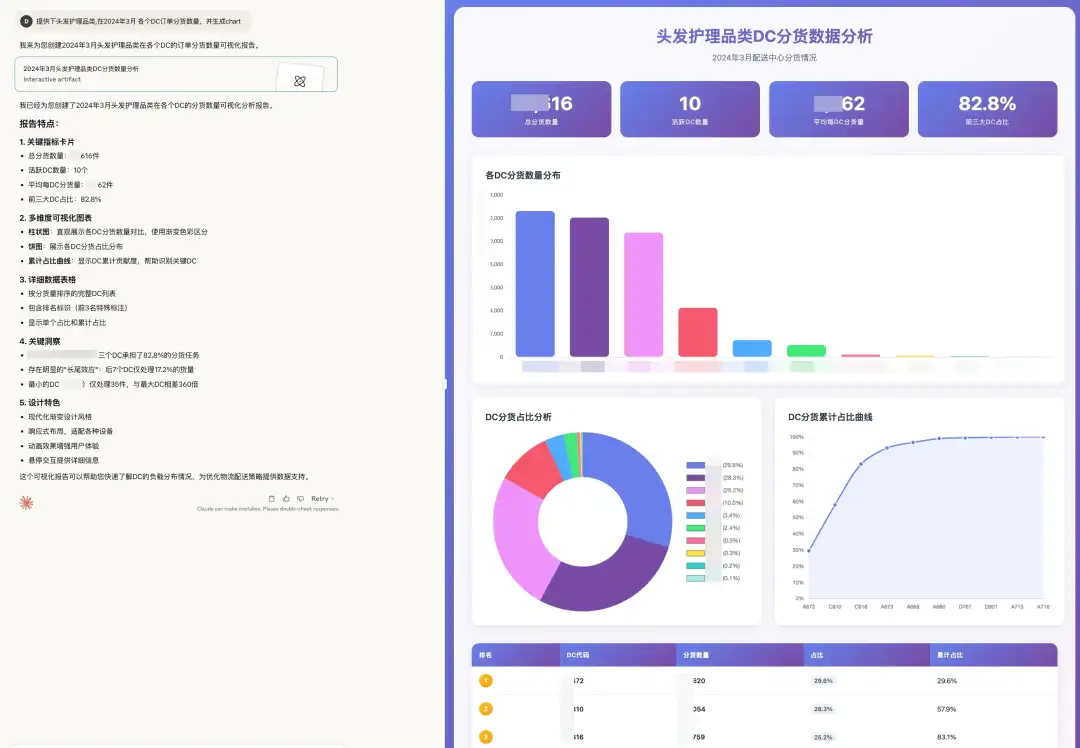
4.3 价值
我们为 DataGPT 引入了 MCP Server,旨在通过 MCP 协议驱动的通用 Agent 与其内置专用 Agent 的协同工作,实现从 ChatBI 到 DataAgent 的核心升级。
DataGPT 在对结果进行二次处理时,如内容总结、问题发现和深度追问等方面的能力已远超从前。未来会进一步集成归因、预测等专用模型或 Agent,其能力将更为强大。
场景五:对商品库存、销量做 归因/预测分析
5.1 场景举例
这个场景我们以纽约出租车公共数据集为例,对月份的车费的归因,以及未来时间的表现做出预测。
5.2 传统方式
预测和归因是常见的分析场景,通常需要数据科学家将数据在 Python/R 环境中进行编码、模型训练和调优。如果需要实时报警和监控,就需要利用到 Lakehouse 动态表做数据的实时更新。这可能涉及数据迁移,还需要编程和算法知识,往往需要的周期长、门槛高。对于非结束人员而言,几乎是难以逾越的鸿沟。
5.3 云器的方式Demo
涉及产品功能:云器 Lakehouse Zettapark (Python API)
5.3.1 归因例1:自然语言指令:
哪个月的出行数量的环比增幅最大,为什么,并进行归因分析,提供归因表进行总结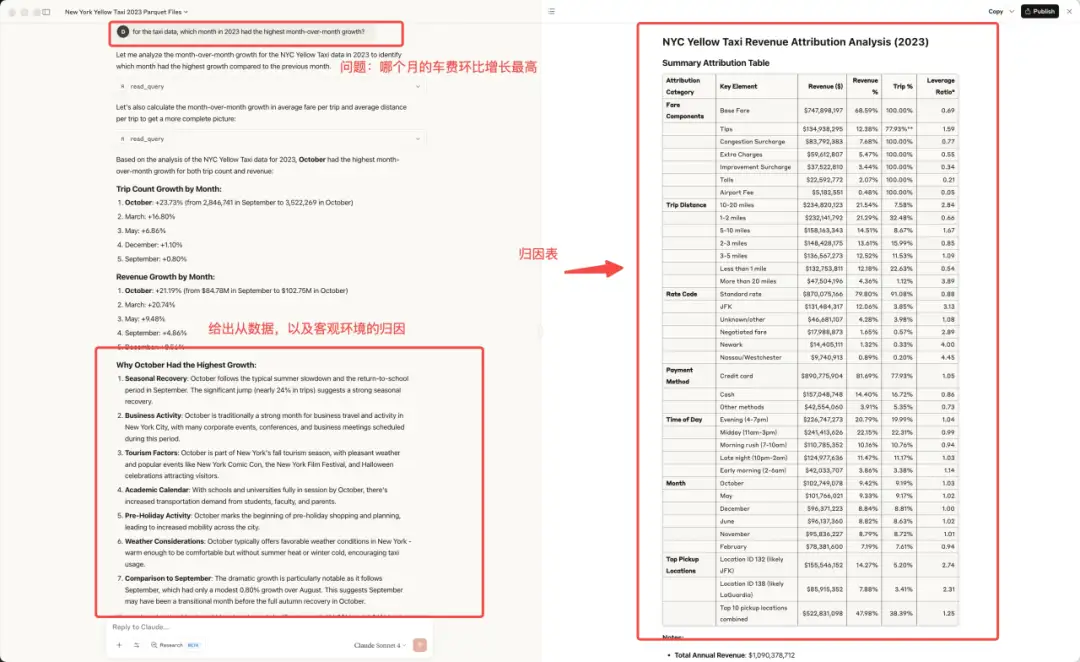
5.3.2 预测例1:预测客户药品消耗:
自然语言指令:
基于schema Mexico_ss 中的现有表,设计一个药品库存监控解决方案,包含以下功能:
1. 库存实时监控:展示每个药品的当前库存量
2. 缺货状态识别:标记库存不足或已缺货的药品
3. 告警数据准备:生成可用于配置告警规则的基础数据
技术要求:
- 刷新频率:每小时自动更新
- 输出告警监控的关键指标字段,我将基于这些字段自行配置告警规则呈现的结果:

附:创建的 Lakehouse 动态表:

5.3.3 预测例2:利用做可视化分析
测试数据集:纽约出租车公共数据集。
自然语言指令:根据2023年的纽约出租车的数据,对2024年一季度做预测。
结果又快又好!
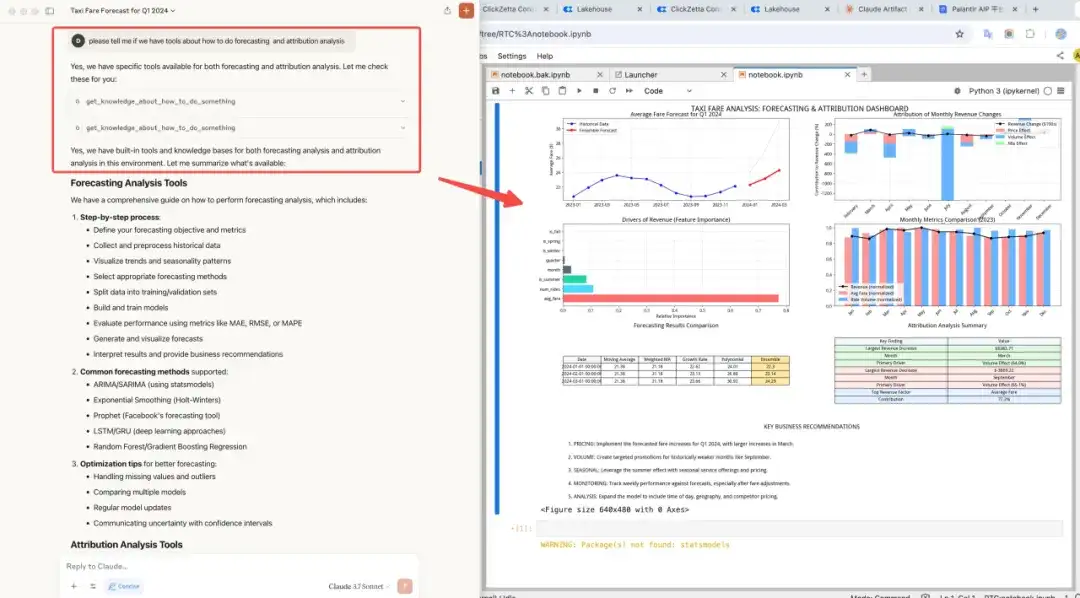
5.4 价值
用户通过自然语言,利用 Lakehouse Zettapark 连接 Python 生态,以及动态表实时刷新功能,轻松调用数据科学计算的能力,执行复杂的及时的预测(如销量预测、用户流失预测)和归因分析。数据无需移出湖仓,极大地简化了流程,降低了技术门槛,让高级数据分析变得触手可及。
场景六:利用生态专业级工具,扩展企业数据处理能力
利用 Google Map MCP server,计算 Lakehouse 表内地点到自由女神像的距离。
Lakehouse作为统一的数据底座,存储和管理着企业所有关键数据。而AI 生态内的工具(以 MCP Server 的方式提供服务)则像一个个即插即用的“能力模块”,围绕Lakehouse提供从开发、运维到分析的全方位支持。如 Google Maps这样的专业服务,极大地扩展了Lakehouse在地理信息处理和分析能力,使得企业可快速构建复杂的AI应用。这种“Lakehouse + MCP Server”的模式,共同构成了企业强大AI生态的核心,驱动业务创新和增长。
例:借助 Google Maps MCP Server 计算经纬度到自由女神像的距离(有批量模式应对大数据量计算)
总结
云器Lakehouse通过MCP Server连接AI生态后,为企业带来的直接价值:
- 省钱省人:云器 Lakehouse x MCP Server ,交付给用户产品的同时,相当于又配备了一位全天候待命的AI数据专家。这位"专家"不需要工资、不休假、不离职,却能以专业水准处理 90% 的日常数据需求。
- 人人用数据:销售、市场、运营人员无需写代码,像聊天一样分析数据,将分析洞察时间从天缩短至分钟。
企业可以维持一个精简的专业数据核心团队负责底层建设,同时让每位员工都能轻松获取和使用数据资产,真正释放数据价值,提升整体组织效能和市场响应速度。
访问云器官网,直接试用体验![]() https://www.yunqi.tech/reservation?hmsr=csdn&hmpl=&hmcu=&hmkw=&hmci=
https://www.yunqi.tech/reservation?hmsr=csdn&hmpl=&hmcu=&hmkw=&hmci=
更多内容,欢迎关注「云器科技」官网!
云器科技-多云及一体化数据平台提供



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









