







摘要: NLP领域即将巨变,你准备好了吗?
自然语言处理(NLP)领域正在发生变化。
作为NLP的核心表现技术——词向量,其统治地位正在被诸多新技术挑战,如:ELMo,ULMFiT及OpenAI变压器。这些方法预示着一个分水岭:它们在 NLP 中拥有的影响,可能和预训练的 ImageNet 模型在计算机视觉中的作用一样广泛。
由浅到深的预训练
预训练的词向量给NLP的发展带来了很好的方向。2013年提出的语言建模近似——word2vec,在硬件速度慢且深度学习模型得不到广泛支持的时候,它的效率和易用性得到了采用。此后,NLP项目的标准方式在很大程度上保持不变:经由算法对大量未标记数据进行预处理的词嵌入被用于初始化神经网络的第一层,其它层随后在特定任务的数据上进行训练。这种方法在大多数训练数据量有限的任务中表现的不错,通过模型都会有两到三个百分点的提升。尽管这些预训练的词嵌入模型具有极大的影响力,但它们有一个主要的局限性:它们只将先验知识纳入模型的第一层,而网络的其余部分仍然需要从头开始训练。
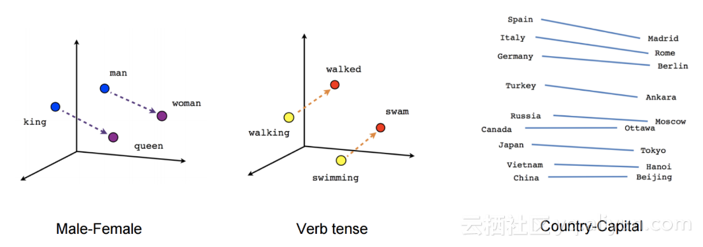
word2vec捕获的关系(来源:TensorFlow教程)
Word2vec及其他相关方法是为了实现效率而牺牲表达性的笨方法。使用词嵌入就像初始化计算机视觉模型一样,只有编码图像边缘的预训练表征:它们对许多任务都有帮助,但是却无法捕获可能更有用的信息。利用词嵌入初始化的模型需要从头开始学习,不仅要消除单词的歧义,还要从单词序列中提取意义,这是语言理解的核心。它需要建模复杂的语言现象:如语义组合、多义性、长期依赖、一致性、否定等等。因此,使用这些浅层表示初始化的NLP模型仍然需要大量示例才能获得良好性能。
ULMFiT、ELMo和OpenAI transformer最新进展的核心是一个关键的范式转变:从初始化我们模型的第一层到分层表示预训练整个模型。如果学习词向量就像学习图像的边一样,那么这些方法就像学习特征的完整层次结构一样,从边到形状再到高级语义概念。
有趣的是,计算机视觉(CV)社区多年来已经做过预训练整个模型以获得低级和高级特征。大多数情况下,这是通过学习在ImageNet数据集上对图像进行分类来完成的。ULMFiT、ELMo和OpenAI transformer现已使NLP社区接近拥有“ ImageNet for language ”的能力,即使模型能够学习语言的更高层次细微差别的任务,类似于ImageNet启用训练的方式学习图像通用功能的CV模型。在本文的其余部分,我们将通过扩展和构建类比的ImageNet来解开为什么这些方法看起来如此有前途。
ImageNet

ImageNet对机器学习研究过程的影响几乎是不可取代的。该数据集最初于2009年发布,并迅速演变为ImageNet大规模视觉识别挑战赛(ILSVRC)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2025
2025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









