







摘要:本文整理自阿里巴巴开发工程师,Apache Flink Contributor 俞航翔,在 Flink Forward Asia 2022 核心技术专场的分享。本篇内容主要分为四个部分:
- Checkpoint 性能优化之路
- Changelog 机制解析
- Changelog 性能测试
- 总结与规划
一、Checkpoint 性能优化之路
1.1 Checkpoint 总览
众所周知,Flink 是有状态的分布式计算引擎,状态是 Flink 中非常重要的概念,而在 Flink 中状态和 Checkpoint 机制是密不可分的,因此在讨论 Flink 在 Checkpoint 上优化历程之前,先来看下为什么 Checkpoint 这么重要, Checkpoint 到底做了些什么呢?
Checkpoint 概念并不陌生,它在各种系统中都出现过,其主要目的就是容错及保证应用在发生故障后依然能够正常运行。故障对长期应用的系统是无法避免的,而数据处理延迟是流计算系统中非常重要的指标。如何在发生故障后保证应用尽快恢复并追上最新的数据是流计算系统需要重点解决的问题。而相比基于容机制的故障恢复,Checkpoint 机制会更轻量、更易用。

进一步,很多业务对故障恢复后的数据一致性提出了更高的要求。Flink 的 Checkpoint 机制支持了 Exactly-once 语义,在 Source 支持回放和 Sink 支持事务后,可以做到端到端的 Exactly-once 语义。在 Checkpoint 和恢复性能优化到一定程度后,应用可以做到真正的、仿佛没有出现故障似的长期运行。
Flink 是如何基于 Checkpoin 机制做到的呢?
在作业的运行过程中,Flink 的 Stateful 算子会通过 State 记录多个 events 之间的信息,Flink 会定期执行 Checkpoint 把这些状态持久化,将全局一致性快照上传到远端存储中,而在发生故障后,Flink 的每个 Task 将会下载持久化的状态数据到本地并重新构建本地的状态数据结构。如果 Source 支持重放,整个 Pipeline 会从记录的上一个位点开始重放,作业开始正常运行。
基于这两个部分的讨论,可以了解到 Checkpoint 需要围绕两个重要目标设计:轻量级和快速的 Failover。
1.2 更轻量、更快速的 Checkpoint
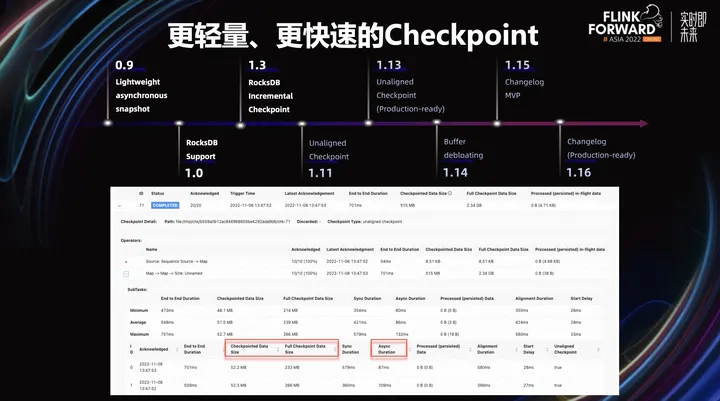
基于以上两个设计目标,Flink 在 Checkpoint 做了诸多优化,我们可以结合 Checkpoint Metrics 来一览这些优化的作用。
在 0.9 这个版本中,Flink 引入了轻量的异步快照算法。这个算法有两个核心点:
- 一是在作业粒度,将 Barrier 作为特殊的 Record 在 Graph 中传递,收到 Barrier 算子将执行 Checkpoint。
- 二是在算子粒度,Checkpoint 的执行步骤分成了同步阶段和异步阶段,并将较重的操作,如文件上传等,放到了异步阶段。
在 Metrics 中我们可以看到 Checkpoint 端到端的耗时被分成了多个时间段,其中我们在遇到 Checkpoint 性能问题时,首先会查看的就是同步阶段的耗时和异步阶段的耗时。之后出现的各项技术就是主要针对这两个阶段的优化。
在 1.0 这个版本中,Flink 支持了 RocksDB StateBackend,让大状态作业拥有了更高的稳定性,然而大状态的 Checkpoint 却成为了瓶颈。随着状态增大,我们可以看到 Full Checkpoint Data Size,即全量 Checkpoint 的数据量会有明显增大,进而导致 Checkpoint 异步部分的耗时增加明显。
因此在 1.3 版本中,Flink 支持了基于 RockDB 的 Incremental Checkpoint。在这种机制下,State Backend 在异步阶段只需要上传增量文件即可,大大减少了 Checkpoint 在异步阶段上传的文件量,从而缩短了 Checkpoint 的异步耗时。
通常,在 Metrics 中看到异步阶段耗时过长,同时 Full Checkpoint Data Size 较大时,可以首先考虑开启该配置。开启之后,可以通过 Checkpointed Data Size 看到增量部分的大小。
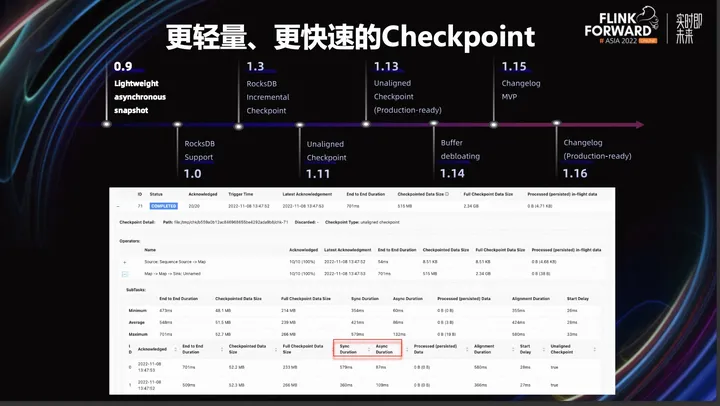
那么同步阶段的耗时可以进一步缩小吗?
在生产实践过程中,在刚才的算法下,Alignment Duration,即对齐时间,通常是同步阶段耗时较长的部分。例如,作业中间的一个算子可能会收到多个上游算子的输入,而在刚刚提及的算法中,为了保证 Exactly-once 语义,需要等到多个 Barries 对齐后,算子才会触发整个 Checkpoint,这会导致整体 Checkpoint 可能会因为链路的算子处理过慢而让整个 Checkpoint 做不出来。这个时候对齐时间就会变长。因此在 1.11 中,Flink 支持了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1965
1965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









