 Flink+Hologres实时UV去重
Flink+Hologres实时UV去重





简介: Flink+Hologres亿级用户实时UV精确去重最佳实践
UV、PV计算,因为业务需求不同,通常会分为两种场景:
- 离线计算场景:以T+1为主,计算历史数据
- 实时计算场景:实时计算日常新增的数据,对用户标签去重
针对离线计算场景,Hologres基于RoaringBitmap,提供超高基数的UV计算,只需进行一次最细粒度的预聚合计算,也只生成一份最细粒度的预聚合结果表,就能达到亚秒级查询。具体详情可以参见往期文章>>Hologres如何支持超高基数UV计算(基于RoaringBitmap实现)
对于实时计算场景,可以使用Flink+Hologres方式,并基于RoaringBitmap,实时对用户标签去重。这样的方式,可以较细粒度的实时得到用户UV、PV数据,同时便于根据需求调整最小统计窗口(如最近5分钟的UV),实现类似实时监控的效果,更好的在大屏等BI展示。相较于以天、周、月等为单位的去重,更适合在活动日期进行更细粒度的统计,并且通过简单的聚合,也可以得到较大时间单位的统计结果。
主体思想
- Flink将流式数据转化为表与维表进行JOIN操作,再转化为流式数据。此举可以利用Hologres维表的insertIfNotExists特性结合自增字段实现高效的uid映射。
- Flink把关联的结果数据按照时间窗口进行处理,根据查询维度使用RoaringBitmap进行聚合,并将查询维度以及聚合的uid存放在聚合结果表,其中聚合出的uid结果放入Hologres的RoaringBitmap类型的字段中。
- 查询时,与离线方式相似,直接按照查询条件查询聚合结果表,并对其中关键的RoaringBitmap字段做or运算后并统计基数,即可得出对应用户数。
- 处理流程如下图所示
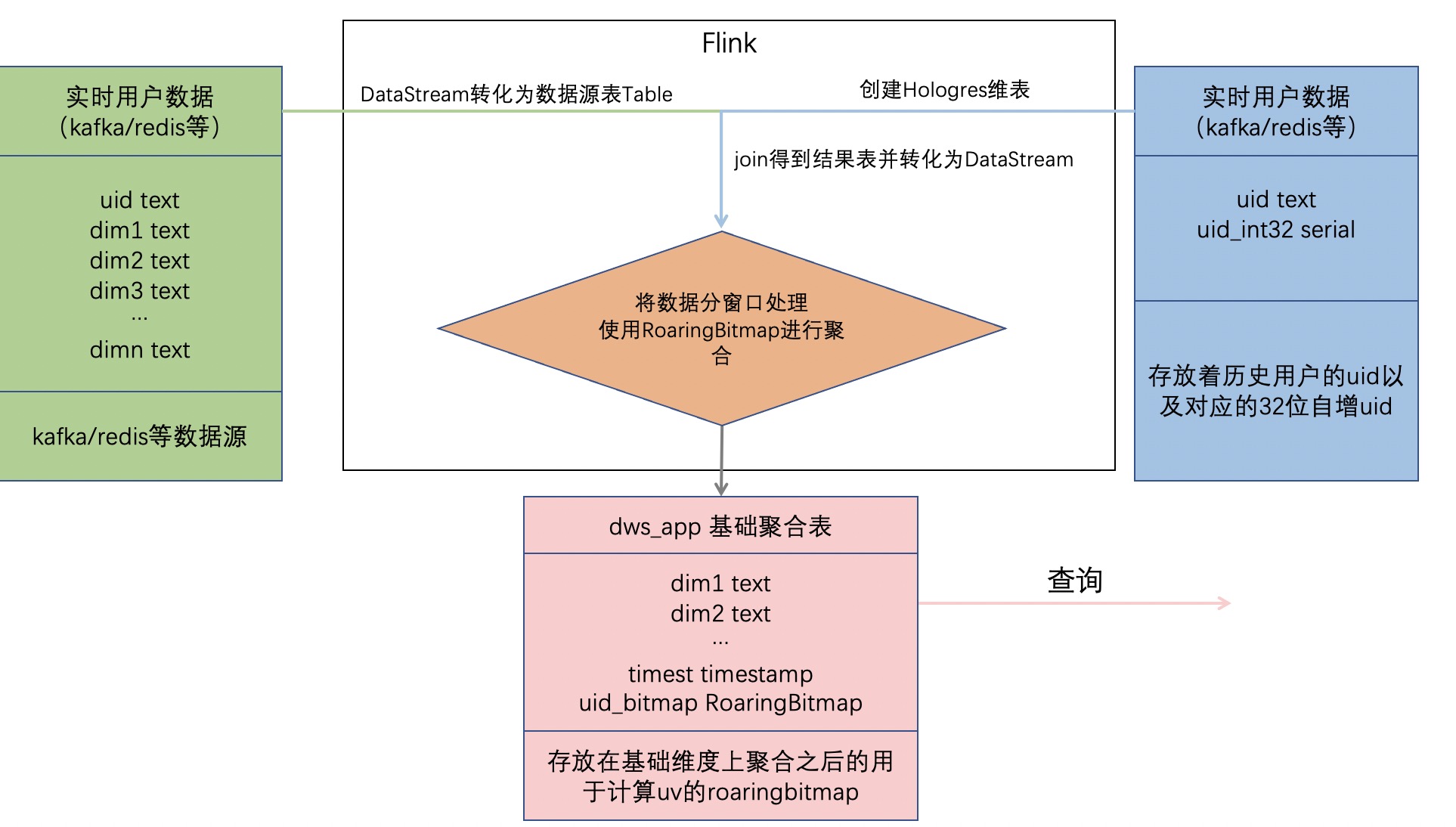
方案最佳实践
1.创建相关基础表
1)创建表uid_mapping为uid映射表,用于映射uid到32位int类型。
- RoaringBitmap类型要求用户ID必须是32位int类型且越稠密越好(即用户ID最好连续)。常见的业务系统或者埋点中的用户ID很多是字符串类型或Long类型,因此需要使用uid_mapping类型构建一张映射表。映射表利用Hologres的SERIAL类型(自增的32位int)来实现用户映射的自动管理和稳定映射。
- 由于是实时数据, 设置该表为行存表,以提高Flink维表实时JOIN的QPS。
BEGIN;
CREATE TABLE public.uid_mapping (
uid text NOT NULL,
uid_int32 serial,
PRIMARY KEY (uid)
);
--将uid设为clustering_key和distribution_key便于快速查找其对应的int32值
CALL set_table_property('public.uid_mapping', 'clustering_key', 'uid');
CALL set_table_property('public.uid_mapping', 'distribution_key', 'uid');
CALL set_table_property('public.uid_mapping', 'orien
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2236
2236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









