







 本文介绍了Python爬虫中使用代理IP的四种方法:1) 利用urllib模块通过ProxyHandler处理代理;2) 使用requests模块设置proxies参数发起请求;3) 结合selenium模拟浏览器时设置代理;4) 在Scrapy框架中配置RandomProxyMiddleware中间件。文章还提及了一连代理提供的免费代理IP资源。
本文介绍了Python爬虫中使用代理IP的四种方法:1) 利用urllib模块通过ProxyHandler处理代理;2) 使用requests模块设置proxies参数发起请求;3) 结合selenium模拟浏览器时设置代理;4) 在Scrapy框架中配置RandomProxyMiddleware中间件。文章还提及了一连代理提供的免费代理IP资源。
前言
在互联网世界,客户端的IP地址是唯一的,所以目标网站会将IP地址作为客户端的身份标识。
通常目标网站的服务器会判断一个频繁的请求是不是来自于同一个IP地址发出的,对于访问速度过高或者访问次数过多的IP,则会对IP进行反爬虫限制访问。
因此,我们需要代理IP来协助我们完成工作。本期《一连百科》将会为大家整理4种python使用代理IP的方法。

方法一 使用urllib模块
Python中最基础的网络请求是使用urllib模块,我们可以利用它来使用代理IP。在使用urllib时,我们需要使用ProxyHandler类来处理代理信息,代码如下: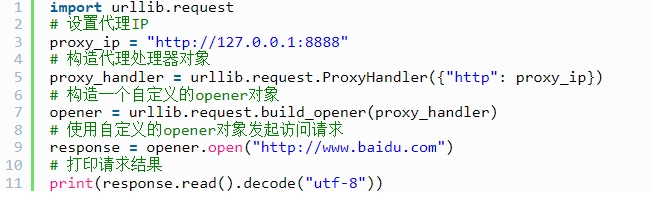
在以上代码中,我们使用了proxy_ip来设置代理IP,使用ProxyHandler来构造代理处理器对象,使用build_opener来构造一个自定义的opener对象,并使用opener对象来发起请求。如果需要设置HTTPS代理IP,只需要将"http"改为"https"即可。
方法二 使用requests模块
在Python中最常用的网络请求模块是requests,因为它非常易用和方便。我们也可以利用它来使用代理IP,代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









