




1. 写在前面
map应该是java程序员在日常工作中用的比较多的,主要用来存储key-value键值对。在正式看HashMap的源码之前我先来抛出几个问题:
- HashMap底层是采用什么结构来存储数据可以做到根据key快速找到value
- 作为存储数据的容器,当数据量多了,HashMap是怎么扩容的?旧数据是怎么迁移的?
- HashMap为什么线程不安全
- 往HashMap中放入元素的过程是怎样的?怎么算出某个元素应该放在哪?
2. 全局视角
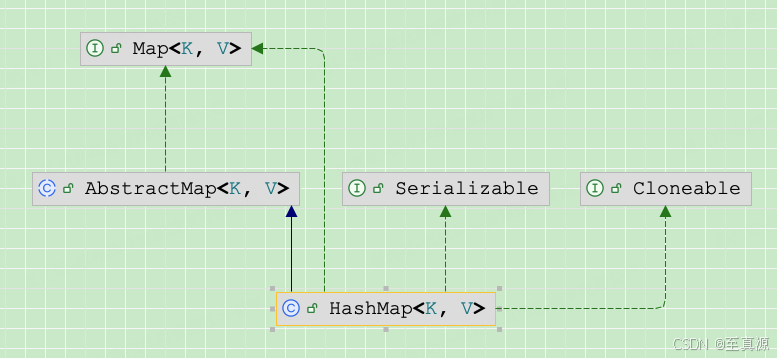
上图展现了HashMap的类继承关系。HashMap 实现了以下接口:
- Map<K, V>: 基本的键值对映射接口。
- Cloneable: 表示该类支持克隆。
- Serializable: 表示该类可以序列化。
2.1 主要类关系和继承关系
2.1.1 Object
HashMap 直接或间接继承自 java.lang.Object,因此它继承了 Object 类的所有方法,例如 equals(), hashCode(), toString(), clone(), 等等。
2.1.2 AbstractMap<K, V>
HashMap 继承自 java.util.AbstractMap<K, V>,这是一个提供 Map 接口的骨架实现的抽象类。AbstractMap 提供了一些基本的方法实现,例如 equals(), hashCode(), toString(), 以及一些其他方法。
2.1.3 Map<K, V>
HashMap 实现了 java.util.Map<K, V> 接口。Map 接口定义了一些基本的操作方法,例如 put(), get(), remove(), containsKey(), containsValue(), size(), isEmpty(), 等等。
2.1.4 Cloneable
HashMap 实现了 java.lang.Cloneable 接口,表示它支持克隆。HashMap 重写了 clone() 方法,可以创建其自身的浅拷贝。
2.1.5 Serializable
HashMap 实现了 java.io.Serializable 接口,表示它可以被序列化。这样可以将 HashMap 的实例通过网络传输或存储到文件中。
2.2 重要内部类
- HashMap.Node<K, V>: 这是 HashMap 的基本单元,表示一个键值对。
- HashMap.Entry<K, V>: 实现了 Map.Entry<K, V> 接口,表示一个条目(键值对)。
- HashMap.TreeNode<K, V>: 用于在哈希表中存储红黑树节点,以解决哈希冲突。
- HashMap.KeySet: 表示键的集合,实现了 Set 接口。
- HashMap.Values: 表示值的集合,实现了 Collection 接口。
- HashMap.EntrySet: 表示条目的集合,实现了 Set<Map.Entry<K, V>> 接口。
2.3 主要方法
- V put(K key, V value): 将指定的值与该映射中的指定键关联。如果映射以前包含一个键的映射,则旧值将被替换。
- V get(Object key): 返回指定键所映射的值;如果此映射不包含键的映射关系,则返回 null。
- V remove(Object key): 如果存在,则从映射中移除指定键的映射关系。
- boolean containsKey(Object key): 如果此映射包含指定键的映射关系,则返回 true。
- boolean containsValue(Object value): 如果此映射将一个或多个键映射到指定值,则返回 true。
- int size(): 返回此映射中的键值映射关系的数量。
- boolean isEmpty(): 如果此映射不包含键值映射关系,则返回 true。
- void clear(): 从此映射中移除所有键值映射关系。
3. 从往HashMap中放入元素说起
Map<String, String> map = new HashMap<>();
map.put("aa", "bb");
上面这两行代码,应该是我们在日常工作中用的最多的,就是定义一个Map,然后往里面放入键值对。这里面涉及两个重要操作:
- 创建Map
- 往Map中放入元素
我们接下来分别详细看下。
3.1 创建HashMap
HashMap的构造方法的源代码如下:
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
上面这个构造方法里就1行代码,就是指定了默认的加载因子。
3.1.1 默认加载因子 (Default Load Factor)
- 默认加载因子为 0.75。加载因子是哈希表在其容量自动增加之前可以达到的填充度的度量。
- 具体来说,当哈希表中的条目数量超过 容量 * 加载因子 时,哈希表将进行一次 rehash 操作,增加其容量并重新分配所有条目。
- 0.75 是一个折中值,既可以保证较高的空间利用率,又可以保持较低的查找成本。
3.1.2 其他构造方法
3.1.2.1 指定初始容量的构造方法:
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
- 初始容量是哈希表在创建时分配的桶(bucket)数量。桶是存储键值对的基础结构,通常是一个链表或红黑树。
- 用户可以通过这个构造方法指定初始容量,以便在预期哈希表将存储大量条目时,减少扩容操作的次数,从而提高性能。
3.1.2.2 指定初始容量和加载因子的构造方法
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
- 参数检查
- 如果 initialCapacity 小于 0,会抛出 IllegalArgumentException
- 如果 initialCapacity 大于最大容量(MAXIMUM_CAPACITY),则将初始容量设置为最大容量
- 如果 loadFactor 小于等于 0 或者是 NaN,也会抛出 IllegalArgumentException
-
设置加载因子
this.loadFactor = loadFactor; 将加载因子设置为传入的值。 -
计算阈值
this.threshold = tableSizeFor(initialCapacity); 计算并设置哈希表的阈值。阈值是哈希表在需要扩容之前所能容纳的最大条目数
3.1.2.3 从另一个 Map 构造 HashMap
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
这个构造方法将传入的 Map 中的所有键值对复制到新的 HashMap 中,并使用默认的加载因子(0.75)。
putMapEntries 方法是一个私有方法,用于将另一个 Map 中的所有条目放入当前 HashMap 中。以下是 putMapEntries 方法的实现:
/**
* Implements Map.putAll and Map constructor.
*
* @param m the map
* @param evict false when initially constructing this map, else
* true (relayed to method afterNodeInsertion).
*/
private void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
- 计算新的容量和阈值
- 如果当前哈希表的桶数组 table 为空,则根据传入的 Map 的大小 s 计算新的容量和阈值
- 计算公式为 ft = ((float)s / loadFactor) + 1.0F,然后将其转换为整数 t
- 如果计算得到的 t 大于当前阈值 threshold,则调整阈值
- 调整大小
如果当前哈希表的桶数组不为空,并且传入的 Map 的大小 s 超过当前阈值,则调用 resize() 方法调整哈希表的大小 - 复制条目
使用 for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) 遍历传入的 Map 中的所有条目,并调用 putVal 方法将每个键值对放入新的 HashMap 中
put
说完了Map的创建,我们再来看看put方法的底层实现。源代码如下:
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
可以发现直接调了putVal方法,往HashMap中放入元素的核心代码都在这个方法里。源代码如下:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
详细来分析下。
- 参数说明
- hash: 键的哈希值
- key: 要插入的键
- value: 要插入的值
- onlyIfAbsent: 如果为 true,则不改变已经存在的键的值
- evict: 如果为 false,表示哈希表处于创建模式
-
哈希表初始化或扩容
如果哈希表的桶数组 table 为空或者长度为 0,则调用 resize() 方法初始化或扩容哈希表 -
计算桶索引
使用 (n - 1) & hash 计算键在哈希表中的桶索引 i -
插入新节点
如果桶 tab[i] 为空,则创建一个新节点并插入到该桶中 -
处理哈希冲突
如果桶 tab[i] 不为空,则检查当前桶中的节点
- 如果当前节点的哈希值与键相同,并且键也相同,则表示键已经存在,记录该节点。
- 如果当前节点是 TreeNode 类型,则调用 putTreeVal 方法将键值对插入到红黑树中
- 否则,遍历链表,处理链表中的节点:
- 如果找到相同的键,则记录该节点
- 如果遍历到链表末尾,则插入新节点。如果链表长度达到阈值 TREEIFY_THRESHOLD,则将链表转换为红黑树
- 更新节点值
如果找到相同的键,并且 onlyIfAbsent 为 false 或当前值为 null,则更新节点的值 - 维护哈希表状态
- 增加修改计数 modCount
- 如果哈希表的大小超过阈值 threshold,则调用 resize() 方法扩容
- 调用 afterNodeInsertion(evict) 方法进行插入后的处理




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











