









第一部分:登陆并进入淘宝首页
import time
import random
import undetected_chromedriver as uc # 正确的导入方式
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
# 设置 Chrome 浏览器选项
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 禁用自动化检测
options.add_argument("start-maximized") # 窗口最大化
options.add_argument("disable-infobars") # 禁用信息栏
options.add_argument("--disable-extensions") # 禁用扩展
# 如果你不想显示浏览器窗口,使用无头模式
# options.add_argument("--headless")
# 使用 undetected-chromedriver 启动浏览器,绕过反爬虫机制
driver = uc.Chrome(options=options)
print("正在加载网站!")
print("加载中...........................")
# 打开淘宝登录页面
driver.get('https://login.taobao.com/')
# 设置显式等待,最多等待 30 秒
wait = WebDriverWait(driver, 30)
print("网站加载完成!")
print("正在加载二维码!")
print("加载中...........................")
# 使用随机等待时间避免被检测
def random_sleep(min_seconds, max_seconds):
time.sleep(random.uniform(min_seconds, max_seconds))
try:
# 等待二维码元素加载,假设二维码的 ID 是 'qrcode-img'(确认二维码 ID 正确)
qr_code = wait.until(EC.presence_of_element_located((By.ID, 'qrcode-img')))
print("二维码已加载,等待扫码登录...")
# 模拟用户滚动行为:在等待过程中滚动页面,模拟用户活动,防止被检测为自动化脚本
for _ in range(5):
driver.execute_script("window.scrollBy(0, 100);") # 向下滚动页面
random_sleep(1, 2) # 每次滚动后暂停1-2秒
# 等待人工扫码登录,最多等待 300 秒
print("请在 180 秒内扫码登录! 并在扫码登录成功后手动切换到首页!")
print("正在人工登录中....")
print("等待首页用户Id元素出现中....")
print("等待中.........................................")
random_sleep(5, 10) # 稍微延时,防止反爬虫检测过快
time.sleep(180) # 等待扫码登录
# 确认扫码后页面元素加载,确认登录成功
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'user'))) # 查看首页用户Id元素是否出现在DOM容器
print("首页用户Id元素出现在DOM容器,登录成功,进入淘宝首页!")
# 获取当前页面的URL
current_url = driver.current_url # 获取当前页面 URL
print("当前页面[首页] URL:", current_url) # 出现的是首页的url第二部分:手动跳转到商品链接,然后采集数据的源码保存到HTML文件中,以便提取数据
# 手动跳转到新页面
print("在180秒手动跳转需要的新页面!并手动点击全部评论 !")
time.sleep(180) # 观察登录是否成功!
# 模拟鼠标滚动,加载全部评论
print("模拟鼠标滚动,加载全部评论!")
print("模拟中.................")
# 初始化 ActionChains
actions = ActionChains(driver)
# 将鼠标移动到指定位置 (x, y)
actions.move_by_offset(10, 10).perform()
# 暂停一下,模拟人的操作
time.sleep(random.uniform(0.5, 1.5))
# 定位 class 为 comments--vOMSBfi2 beautify-scroll-bar 的 div 元素
div_element = driver.find_element_by_xpath("//div[@class='content--ew3Y4lVg']//div[@class='comments--vOMSBfi2 beautify-scroll-bar']")
# 模拟鼠标滚动,加载全部评论
for i in range(30):
# 随机生成滚动的距离,模拟人操作的不规律性8
scroll_distance = random.randint(100, 300)
# 使用 JavaScript 滚动 div 元素
driver.execute_script(f"arguments[0].scrollTop += {scroll_distance};", div_element)
# 暂停一段时间,模拟人操作的延迟
time.sleep(random.uniform(0.5, 1.5))
time.sleep(10)
print("模拟完成!")
print("自动滚动完成!开始人工查看!【是否加载完全部评论】如果没有请在10秒内手动滚动,以加载全部数据!")
# 获取当前页面的 HTML 内容和 URL
page_source = driver.page_source # 获取页面源码
current_url = driver.current_url # 获取当前页面 URL
# print("页面源码:\n", page_source)
print("当前页面 URL:", current_url)
# 获取到页面源码之后保存起来,以便获取评论数据
with open('淘宝商品链接评论数据.html','w',encoding="utf-8") as f:
f.write(page_source)
print("数据爬取成功!")
print("数据[页面源码]已保存到"+"淘宝商品链接评论数据.html"+"文件中!")
except Exception as e:
print(f"发生错误: {e}")
finally:
# 关闭浏览器
driver.quit()
第三部分:从源码从提取评论数据【日期,评论】,保存到csv文件
import csv
import logging
from lxml import etree
from datetime import datetime
def setup_logging():
# 设置日志配置,只记录错误信息
logging.basicConfig(level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s')
def parse_date(date_str):
# 将日期字符串转换为 datetime 对象
try:
# 这里假设日期字符串格式为 "2024年12月10日",请根据实际情况修改格式
return datetime.strptime(date_str, "%Y年%m月%d日")
except ValueError as e:
logging.error(f"日期转换错误: {e}")
return None
def write_to_csv(file_name, data_list):
unique_data = set() # 存储唯一的数据
sorted_data = [] # 存储最终排序后的数据
with open(file_name, "w", encoding="utf-8-sig", newline='') as file:
writer = csv.writer(file)
writer.writerow(["日期", "评论"]) # 写入表头
for data in data_list:
try:
# 提取日期信息
date_text = data.xpath(".//div[@class='meta--TDfRej2n']/text()")
date = date_text[0].split("·")[0].strip() if date_text else ""
# 提取评论信息
comment_text = data.xpath(".//div[@class='content--FpIOzHeP']/text()")
comment = comment_text[0] if comment_text else ""
# 检查数据是否重复
if (date, comment) not in unique_data:
unique_data.add((date, comment))
sorted_data.append((date, comment))
except (IndexError, AttributeError) as e:
logging.error(f"解析某条评论信息时出错:{e}")
# 对数据按日期排序
sorted_data.sort(key=lambda x: parse_date(x[0]) if parse_date(x[0]) else datetime.min)
for date, comment in sorted_data:
# 写入 CSV 文件
writer.writerow([date, comment])
print(f"最终结果的数据条数: {len(sorted_data)}")
def main():
setup_logging()
# 读取爬取的文件数据
with open('淘宝商品链接评论数据.html', 'r', encoding='utf-8') as f:
html = f.read()
# 使用 lxml.etree.HTML 解析 HTML 内容
html_tree = etree.HTML(html)
# 批量提取评论数据
data_list = html_tree.xpath("//div[@class='Comment--KkPcz74T']")
print(f"成功提取 {len(data_list)} 条评论信息!")
# 保存到文件
file_name = "淘宝商品评论数据.csv"
write_to_csv(file_name, data_list)
print("数据提取成功!已保存到{}!".format(file_name))
if __name__ == "__main__":
main()
第四部分:数据结果展示
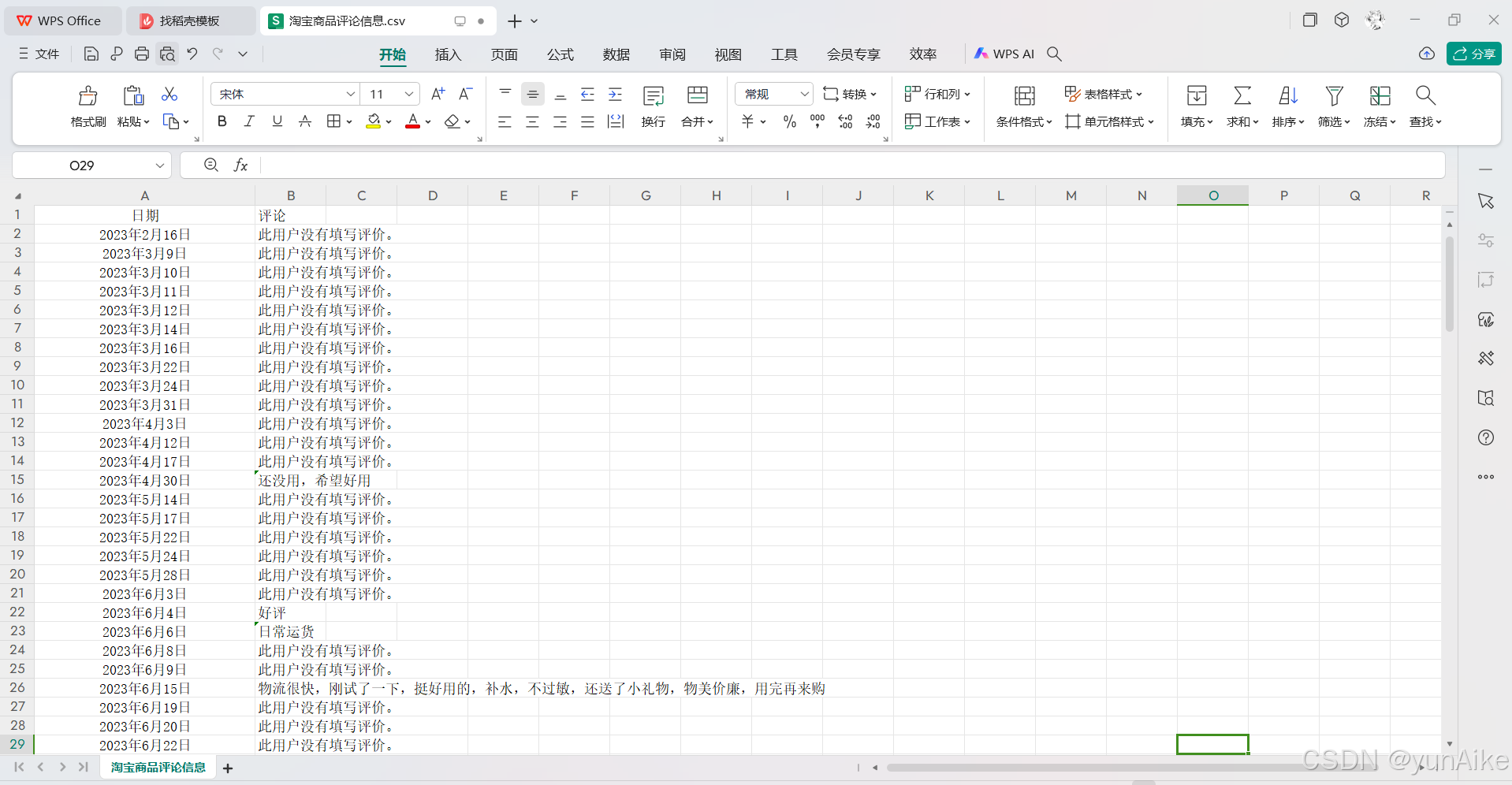


















 1644
1644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









