







RoPE 介绍
Motivation
在基于视频的 multimodal large language model 中,更好地利用视频提供的时序信息。
Method
Temporal-Aware Dual RoPE
之前的 RoPE 公式:
A
(
q
T
m
,
k
F
n
V
z
)
=
R
e
[
q
T
m
k
F
n
V
z
e
i
(
P
(
T
m
)
−
P
(
F
n
V
z
)
)
θ
]
A_{(q_{T_m},k_{F_nV_z})}=Re[q_{T_m}k_{F_nV_z}e^{i(P(T_m)-P(F_nV_z))\theta}]
A(qTm,kFnVz)=Re[qTmkFnVzei(P(Tm)−P(FnVz))θ],在这种形式的公式里,每个 visual token 的编码时独立的,且无法区分哪些 visual token 属于同一帧,哪些属于不同的帧。
TAD-RoPE 在原本的 position id 的基础上,增加了 temporal position id:
I
t
(
n
)
=
{
n
,
i
f
n
<
v
s
,
v
s
+
⌊
n
−
v
s
m
⌋
,
i
f
v
s
≤
n
≤
v
e
,
n
−
(
v
e
−
v
s
+
1
−
⌊
v
e
−
v
s
m
⌋
)
,
i
f
n
>
v
e
\begin{align} I_t(n)= \begin{cases} n,&if\ n<v_s, \\ v_s+\lfloor\frac{n-v_s}{m}\rfloor,&if\ v_s\le n\le v_e, \\ n-(v_e-v_s+1-\lfloor\frac{v_e-v_s}{m}\rfloor),&if\ n>v_e \end{cases} \end{align}
It(n)=⎩
⎨
⎧n,vs+⌊mn−vs⌋,n−(ve−vs+1−⌊mve−vs⌋),if n<vs,if vs≤n≤ve,if n>ve
调整后的位置编码为:
n
^
=
n
+
γ
⋅
I
t
(
n
)
\hat{n}=n+\gamma\cdot I_t(n)
n^=n+γ⋅It(n)
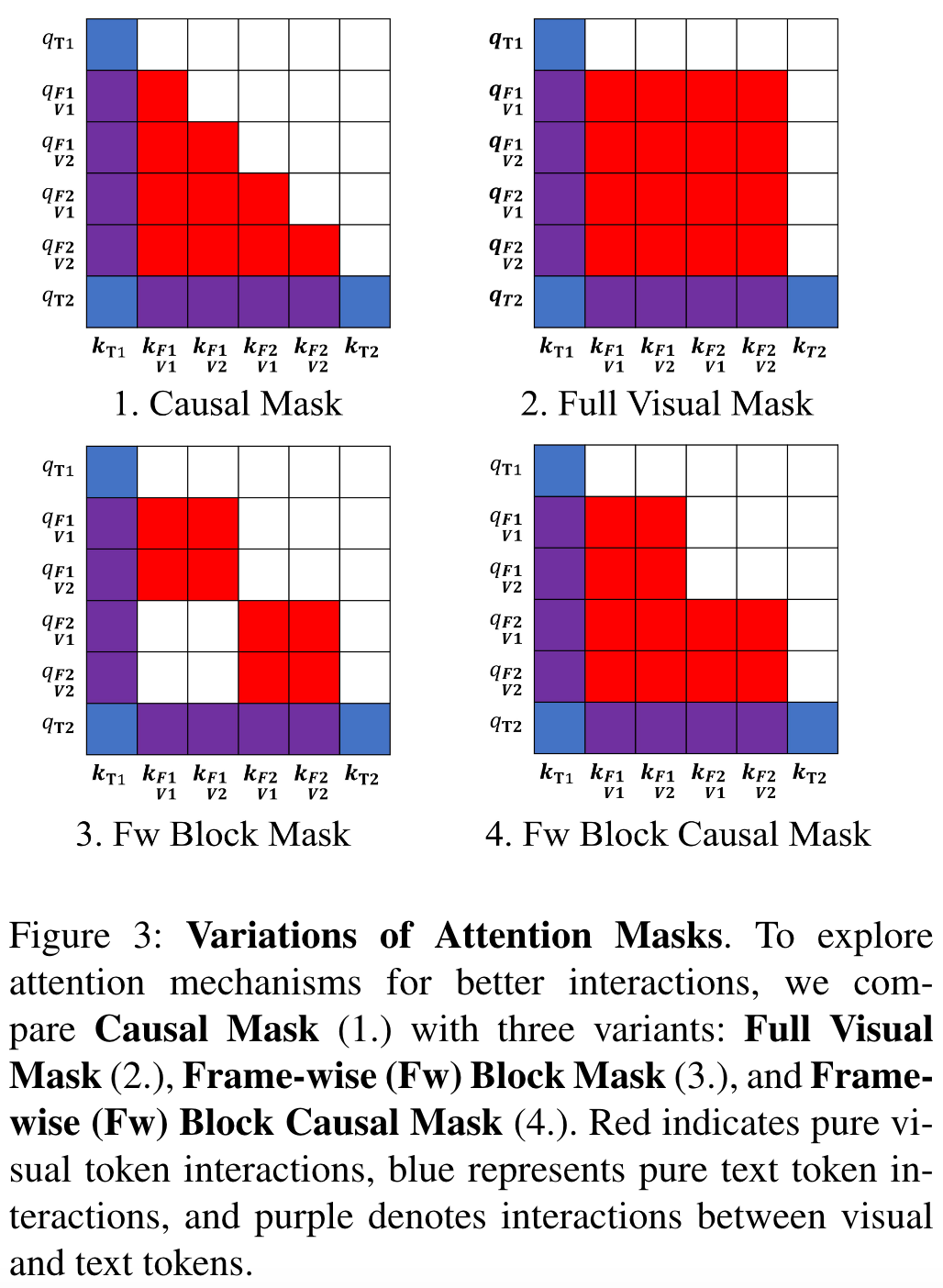
Frame-wise Block Causal Attention Mask
通常语言模型中,采用后面的 token 能看到前面 token,但前面的 token 无法看到后面 token 的设计。这种设计在文本 token 中很自然,但是在 visual token 里会导致 visual token 交互不充分,因此本文尝试了几种不同的 token 设计。
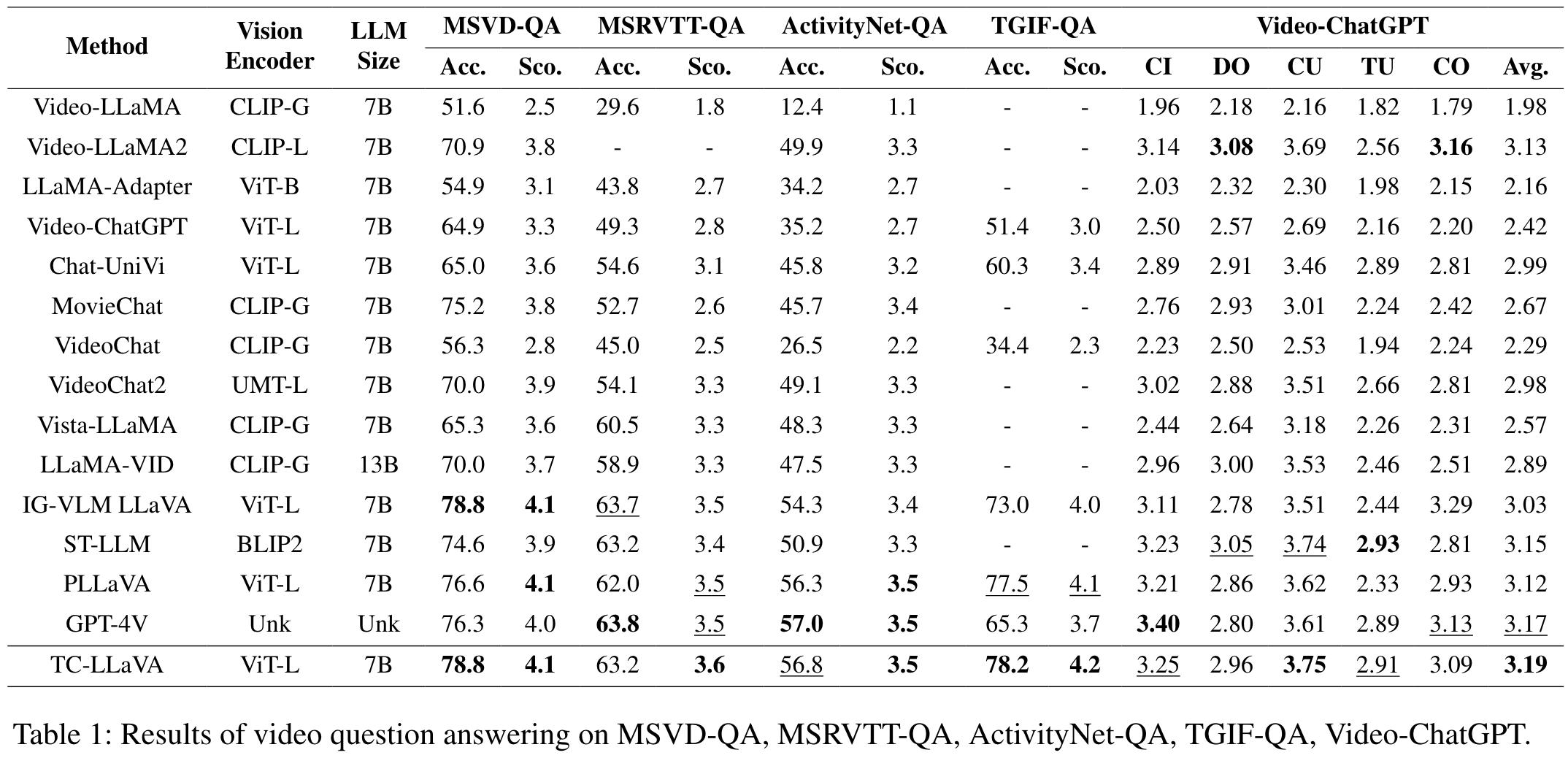
实验结果
与 SOTA 相比
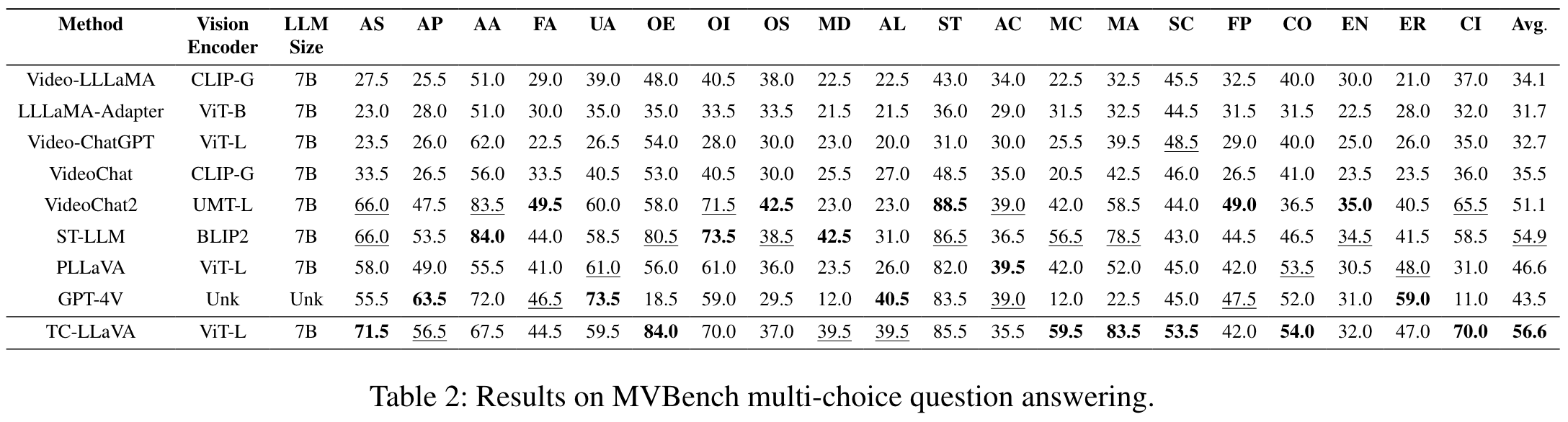
Ablation Studies
通过实验证明了 TAD-RoPE 及 Frame-wise Block Causal Attention Mask 的性能优势。

















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









