




 文章探讨了Raft算法在极端网络条件下失去活性的问题,尤其是在Pre-Vote阶段可能导致的困境。通过增加Pre-Vote和CheckQuorum机制,解决了单点故障导致的不稳定性,确保了系统的正常运行。
文章探讨了Raft算法在极端网络条件下失去活性的问题,尤其是在Pre-Vote阶段可能导致的困境。通过增加Pre-Vote和CheckQuorum机制,解决了单点故障导致的不稳定性,确保了系统的正常运行。
极端情况下的活性问题
Raft算法存在一种失去活性的极端情况:如果有一条网络连接不可靠,那么当前领导者会不断被迫下台导致系统实际上毫无进展。
如图所示的4节点Raft集群有一个节点和其他三个网络不太稳定,假设它能发送消息给别的节点,但收不到其他节点的消息,那么它将一直收不到心跳消息,这会导致该节点转为候选者,然后自增任期并发起新的选举。该节点发送的更大任期的RequestVote请求会导致集群当前的领导者下台并重新选举。这样的情况会一直往复,导致集群无法正常工作。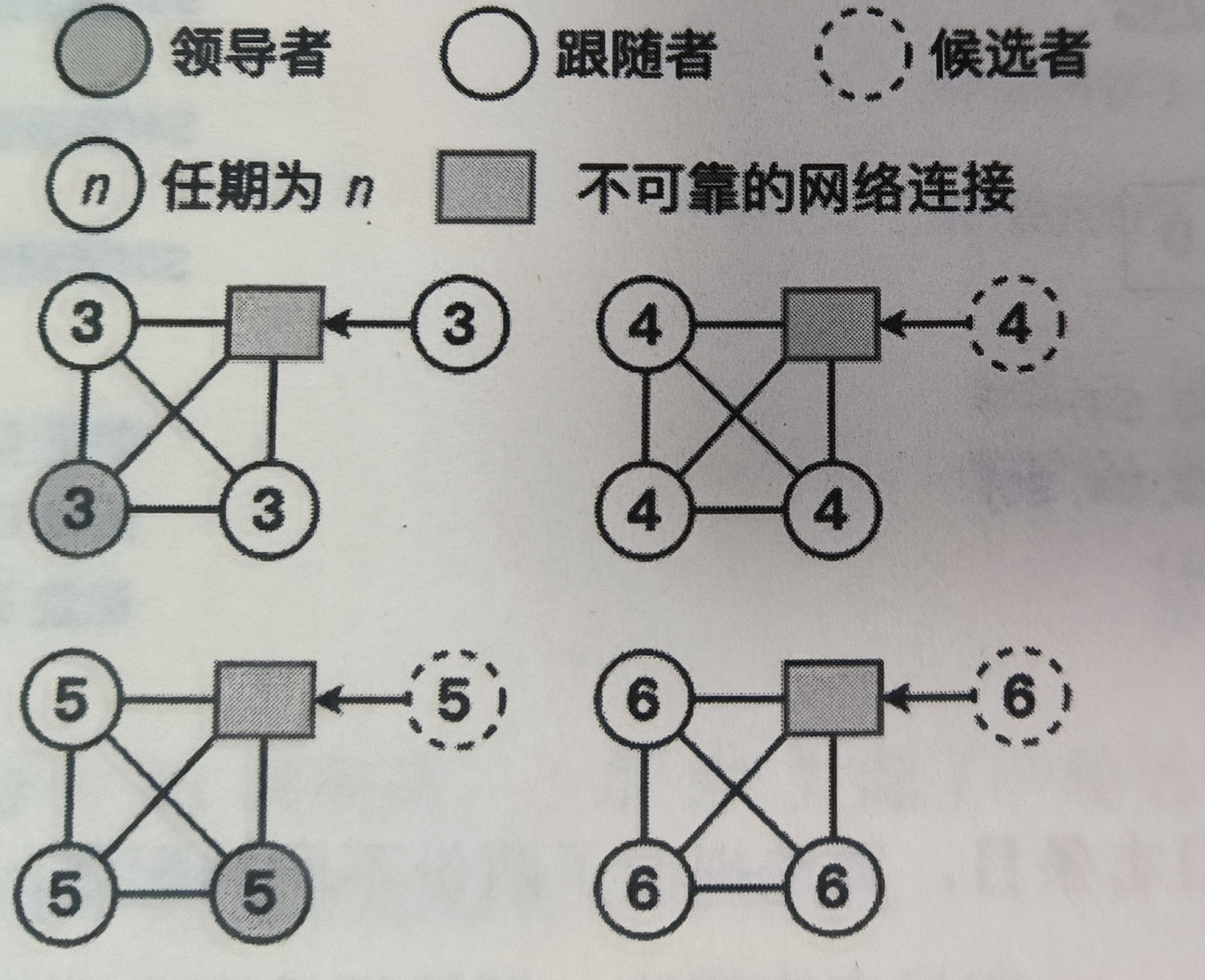
之前提到的Pre-Vote可以用来解决该问题。增加了预候选者状态后的Raft算法状态转移图如下
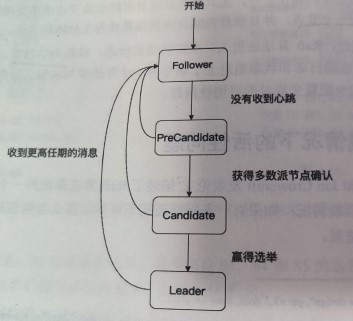
Pre-Vote请求只有超过半数的节点同意选举才能自增任期并发起新的选举。
在举的例子中,网络链路有问题的节点在Pre-Vote阶段无法赢得半数的选举(其他节点能收到心跳),因此不会自增任期去干扰领导者工作。
Pre-Vote的问题
只有Pre-Vote阶段还可能存在一种极端情况导致Raft算法失去活性。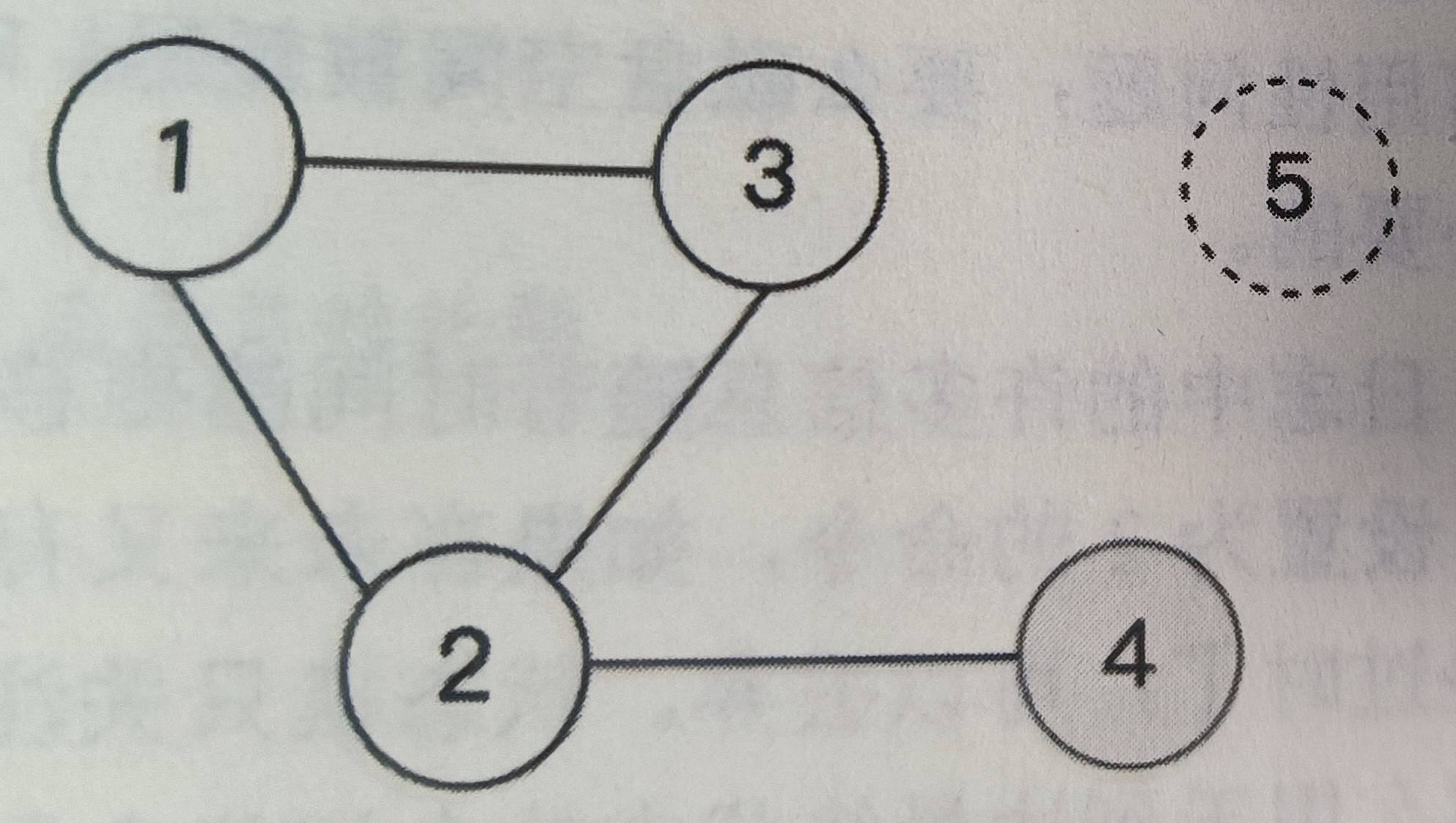
如图是一个由5个节点组成的Raft集群,故障发生之前节点4是领导者。现在故障发生了,节点5宕机了,同时节点4只和节点2保持连接,节点1、2、3互相保持连接。这种情况下节点1、3收不到节点4的心跳,会发起Pre-Vote请求,但由于节点2能收到节点4的心跳,所以节点2不会同意Pre-Vote请求,因此节点1、3无法满足超过半数节点同意Pre-Vote请求的条件,该请求以失败告终。
该集群的问题是无法选举出新的领导者,但旧的领导者的AppendEntries请求又只能到达两个节点(节点2和节点4),日志复制无法满足多数派条件,整个集群无法取得任何进展,依然不满足活性。
上图中的5节点Raft集群明明可以忍受2个节点发生故障(Quorum> N/2),但增加了Pre-Vote阶段后,反而无法容忍仅仅1个节点故障。其实如果没有Pre-Vote阶段,那么节点1和节点3反而有机会当选领导者从而推动整个系统正常工作。在这种情况下,Pre-Vote阶段起了反作用。
因此Raft算法需要增加一种机制使得领导者主动下台。
这个机制很简单,当领导者没有收到超过半数节点的AppendEntries响应就主动下台。这样,上图的节点1、2、3就都有机会当选新的领导者,整个集群依然可以正常工作。
etcd将这一优化叫做CheckQuorum。CheckQuorum确保了如果当前领导者无法连接到多数派节点,那么它会下台并选举出新的领导者。Pre-Vote确保一旦领导者当选,整个系统将是稳定的,领导者不会被迫下台。

















 147
147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









