







 本文详细介绍了HDFS的fsck命令,用于检查文件系统的健康状况,包括文件问题、块丢失和不一致等。fsck命令通过HTTP发送请求到NameNode,NameNode通过内部的Servlet响应并执行实际的检查。fsck命令的参数解析、执行逻辑以及NameNode如何处理请求的过程被详细阐述,展示了HDFS系统内部的工作机制。
本文详细介绍了HDFS的fsck命令,用于检查文件系统的健康状况,包括文件问题、块丢失和不一致等。fsck命令通过HTTP发送请求到NameNode,NameNode通过内部的Servlet响应并执行实际的检查。fsck命令的参数解析、执行逻辑以及NameNode如何处理请求的过程被详细阐述,展示了HDFS系统内部的工作机制。
fsck命令分析
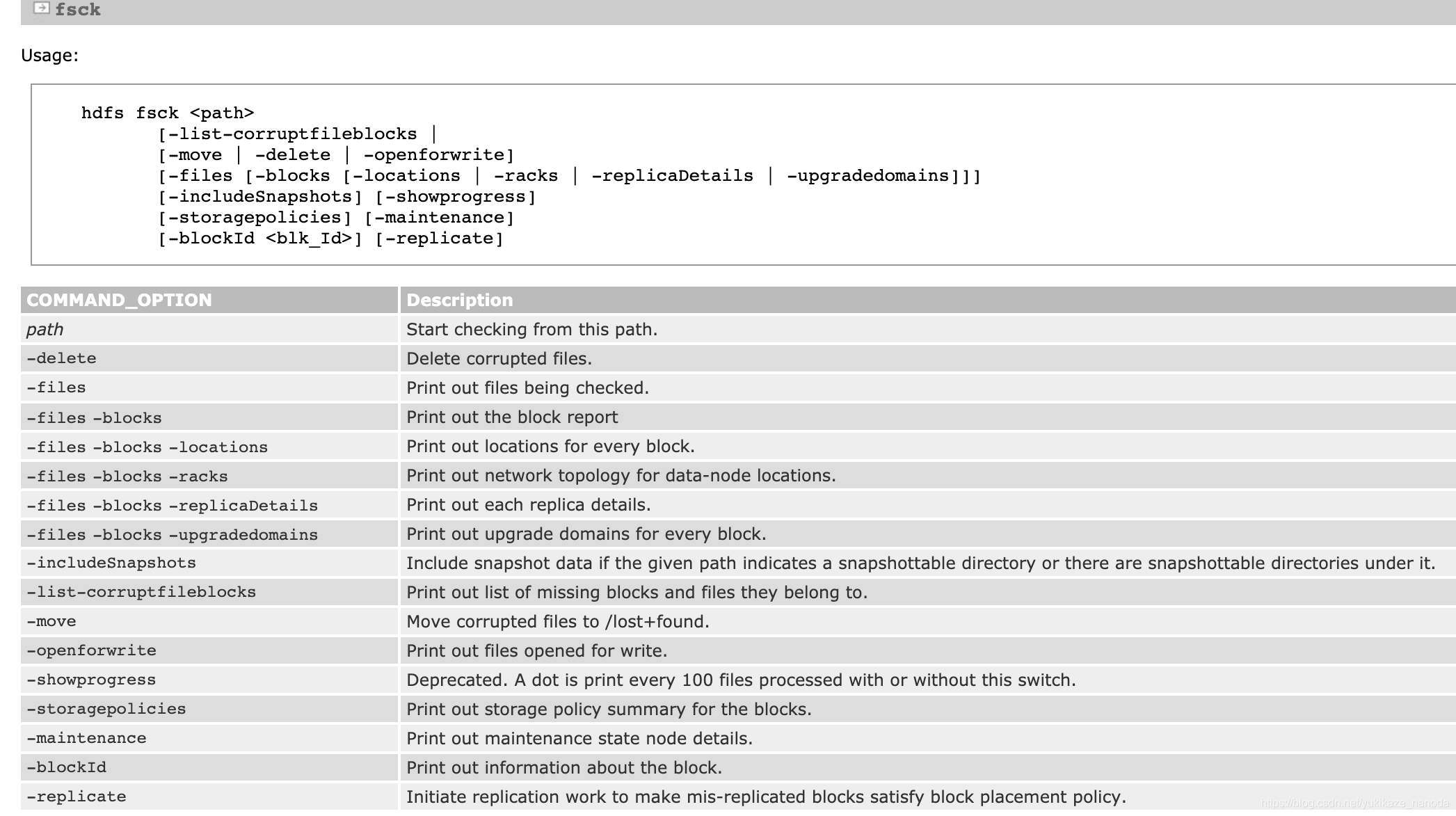
HDFS支持fsck命令用以检查各种不一致。fsck用以报告各种文件问题,如block丢失或缺少block等。fsck命令用法如下:
$HADOOP_HOME/bin/ hdfs fsck <path>
[-list-corruptfileblocks |
[-move | -delete | -openforwrite]
[-files [-blocks [-locations | -racks | -replicaDetails | -upgradedomains]]]
[-includeSnapshots] [-showprogress]
[-storagepolicies] [-maintenance]
[-blockId <blk_Id>] [-replicate]
<path> 检查的起始目录
-move 将损坏的文件移动到/lost+found下面
-delete 删除损坏的文件
-openforwrite 打印出正在写的文件
-files 打印出所有被检查的文件
-blocks 打印出block报告
-locations 打印出每个block的位置
-racks 打印出datanode的网络拓扑结构
默认情况下,fsck会忽略正在写的文件,使用-openforwrite选项可以汇报这种文件。
官网对fsck命令的介绍如下:
一个fsck命令运行的结果示例如下:
[hadoop@master1 ~]$ hadoop-current/bin/hdfs fsck hdfs://mycluster/test/tail.txt -files -blocks -locations
Connecting to namenode via http://master1:50070/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Ftest%2Ftail.txt
FSCK started by hadoop(null) (auth:SIMPLE) from /XX.XX.XX.XX for path /test/tail.txt at Thu Aug 26 15:28:38 CST 2021
/test/tail.txt 27 bytes, replicated: replication=3, 1 block(s): Under replicated BP-465154060-10.96.83.87-1627619151215:blk_1073741841_1017. Target Replicas is 3 but found 2 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
0. BP-465154060-10.96.83.87-1627619151215:blk_1073741841_1017 len=27 Live_repl=2 [DatanodeInfoWithStorage[XX.XX.XX.XX:9866,DS-f0c50895-ebae-4285-8a05-c7c05c5715a1,DISK], DatanodeInfoWithStorage[XX.XX.XX.XX:9866,DS-84cd2957-a0cf-4e79-af55-93e938d84ecd,DISK]]
Status: HEALTHY
Number of data-nodes: 2
Number of racks: 1
Total dirs: 0
Total symlinks: 0
Replicated Blocks:
Total size: 27 B
Total files: 1
Total blocks (validated): 1 (avg. block size 27 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (100.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 2.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 1 (33.333332 %)
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
FSCK ended at Thu Aug 26 15:28:38 CST 2021 in 1 milliseconds
The filesystem under path '/test/tail.txt' is HEALTHY
客户端发出fsck请求
测试代码如下
@Test
public void FsckShell() throws Exception{
Configuration conf = new Configuration();
conf.addResource(new Path("/Users/didi/hdfs-site.xml"));
conf.addResource(new Path("/Users/didi/core-site.xml"));
FsShell fsShell = new FsShell();
fsShell.setConf(conf);
String[] args = {"-openforwrite", "/test"};
ByteArrayOutputStream bStream = new ByteArrayOutputStream();
PrintStream out = new PrintStream(bStream, true);
DFSck dfsck = new DFSck(conf, out);
int errCode = ToolRunner.run(dfsck, args);
System.out.println(errCode);
System.out.println(bStream.toString());
}
从ToolRunner.run()方法step into。
fsck工具的启动入口在org.apache.hadoop.hdfs.tools.DFSck类,主要运行逻辑在doWork方法中
private int doWork(final String[] args) throws IOException {
final StringBuilder url = new StringBuilder();
url.append("/fsck?ugi=").append(ugi.getShortUserName());
String dir = null;
boolean doListCorruptFileBlocks = false;
for (int idx = 0; idx < args.length; idx++) {
if (args[idx].equals("-move")) { url.append("&move=1"); }
else if (args[idx].equals("-delete")) { url.append("&delete=1"); }
else if (args[idx].equals("-files")) { url.append("&files=1"); }
else if (args[idx].equals("-openforwrite")) { url.append("&openforwrite=1"); }
else if (args[idx].equals("-blocks")) { url.append("&blocks=1"); }
else if (args[idx].equals("-locations")) { url.append("&locations=1"); }
else if (args[idx].equals("-racks")) { url.append("&racks=1"); }
else if (args[idx].equals("-storagepolicies")) { url.append("&storagepolicies=1"); }
else if (args[idx].equals("-list-corruptfileblocks")) {
url.append("&listcorruptfileblocks=1");
doListCorruptFileBlocks = true;
} else if (args[idx].equals("-includeSnapshots")) {
url.append("&includeSnapshots=1");
} else if (args[idx].equals("-blockId")) {
StringBuilder sb = new StringBuilder();
idx++;
while(idx < args.length && !args[idx].startsWith("-")){
sb.append(args[idx]);
sb.append(" ");
idx++;
}
url.append("&blockId=").append(URLEncoder.encode(sb.toString(), "UTF-8"));
} else if (!args[idx].startsWith("-")) {
if (null == dir) {
dir = args[idx];
} else {
System.err.println("fsck: can only operate on one path at a time '"
+ args[idx] + "'");
printUsage(System.err);
return -1;
}
} else {
System.err.println("fsck: Illegal option '" + args[idx] + "'");
printUsage(System.err);
return -1;
}
}
//整个for循环其实只干了一件事:解析传过来的参数,加上从conf里得到的用户名称,并将其拼接成一个url
//到这里,url的值为/fsck?ugi=XXX&openforwrite=1
if (null == dir) {
dir = "/";
}
Path dirpath = null;
URI namenodeAddress = null;
try {
dirpath = getResolvedPath(dir); // 注意!!!这里进行了一次RPC,调用了DistributedFileSystem.getFileStatus()与namenode交互,获得了参数中的路径所在的HDFS集群的绝对地址
// 此时, dirpath = hdfs://mycluster/test
namenodeAddress = getCurrentNamenodeAddress(dirpath); // 这里获得了namenode的地址,具体代码见下文
} catch (IOException ioe) {
System.err.println("FileSystem is inaccessible due to:\n"
+ StringUtils.stringifyException(ioe));
}
///......
///......
这里贴上getCurrentNamenodeAddress()方法
private URI getCurrentNamenodeAddress(Path target) throws IOException {
//String nnAddress = null;
Configuration conf = getConf();
//get the filesystem object to verify it is an HDFS system
final FileSystem fs = target.getFileSystem(conf);
if (!(fs instanceof DistributedFileSystem)) {
System.err.println("FileSystem is " + fs.getUri());
return null;
}
return DFSUtil.getInfoServer(HAUtil.getAddressOfActive(fs), conf,
DFSUtil.getHttpClientScheme(conf));
//这里,getAddressOfActive()方法进行了RPC,再次与namenode交互获得了当前处于active状态的namenode上的fs路径的地址
}
DFSUtil.getInfoServer()方法如下,主要拼接了一个URI:
public static URI getInfoServer(InetSocketAddress namenodeAddr,
Configuration conf, String scheme) throws IOException {
String[] suffixes = null;
if (namenodeAddr != null) {
// if non-default namenode, try reverse look up
// the nameServiceID if it is available
suffixes = getSuffixIDs(conf, namenodeAddr, // 这个方法返回了存储目标路径的socketaddress:master1/XX.XX.XX.XX:8020
DFSConfigKeys.DFS_NAMENODE_SERVICE_RPC_ADDRESS_KEY,
DFSConfigKeys.DFS_NAMENODE_RPC_ADDRESS_KEY);
}
String authority;
if ("http".equals(scheme)) {
authority = getSuffixedConf(conf, DFS_NAMENODE_HTTP_ADDRESS_KEY,
DFS_NAMENODE_HTTP_ADDRESS_DEFAULT, suffixes);
} else if ("https".equals(scheme)) {
//...
//...
return URI.create(scheme + "://" + authority);
}
我们接着step into
static String[] getSuffixIDs(final Configuration conf,
final InetSocketAddress address, final String... keys) {
AddressMatcher matcher = new AddressMatcher() {
@Override
public boolean match(InetSocketAddress s) {
return address.equals(s);
}
};
for (String key : keys) {
String[] ids = getSuffixIDs(conf, key, null, null, matcher);
if (ids != null && (ids [0] != null || ids[1] != null)) {
return ids;
}
}
return null;
}
在这个方法中,通过本地conf中的dfs.namenode.rpc-address,来匹配RPC得到的地址(置放于matcher),如匹配成功,则返回所在NS和NN
static String[] getSuffixIDs(final Configuration conf, final String addressKey,
String knownNsId, String knownNNId,
final AddressMatcher matcher) {
String nameserviceId = null;
String namenodeId = null;
int found = 0;
Collection<String> nsIds = getNameServiceIds(conf);
for (String nsId : emptyAsSingletonNull(nsIds)) {
if (knownNsId != null && !knownNsId.equals(nsId)) {
continue;
}
Collection<String> nnIds = getNameNodeIds(conf, nsId);
for (String nnId : emptyAsSingletonNull(nnIds)) {
if (LOG.isTraceEnabled()) {
LOG.trace(String.format("addressKey: %s nsId: %s nnId: %s",
addressKey, nsId, nnId));
}
if (knownNNId != null && !knownNNId.equals(nnId)) {
continue;
}
String key = addKeySuffixes(addressKey, nsId, nnId);
String addr = conf.get(key);
if (addr == null) {
continue;
}
InetSocketAddress s = null;
try {
s = NetUtils.createSocketAddr(addr);
} catch (Exception e) {
LOG.warn("Exception in creating socket address " + addr, e);
continue;
}
if (!s.isUnresolved() && matcher.match(s)) {
nameserviceId = nsId;
namenodeId = nnId;
found++;
}
}
}
if (found > 1) { // Only one address must match the local address
String msg = "Configuration has multiple addresses that match "
+ "local node's address. Please configure the system with "
+ DFS_NAMESERVICE_ID + " and "
+ DFS_HA_NAMENODE_ID_KEY + ". Choose the last address.";
throw new HadoopIllegalArgumentException(msg);
}
return new String[] { nameserviceId, namenodeId };
}
这里是FsckShell()方法最后的部分,
if (namenodeAddress == null) {
//Error message already output in {@link #getCurrentNamenodeAddress()}
System.err.println("DFSck exiting.");
return 0;
}
url.insert(0, namenodeAddress.toString());//这里,将url和namenode的地址拼在了一块
//此时,url值为http://master1:50070/fsck?ugi=XXX&openforwrite=1
url.append("&path=").append(URLEncoder.encode(
Path.getPathWithoutSchemeAndAuthority(dirpath).toString(), "UTF-8"));
//这次,拼接dir,url值为http://master1:50070/fsck?ugi=XXX&openforwrite=1&path=%2Ftest
//其实,namenode实现了fsck的servlet,这个fsck命令行脚本只不过去向这个接口提交请求。
System.err.println("Connecting to namenode via " + url.toString());
if (doListCorruptFileBlocks) {
return listCorruptFileBlocks(dir, url.toString());
}//如有坏块,执行坏块汇报
URL path = new URL(url.toString());
URLConnection connection;
try {
connection = connectionFactory.openConnection(path, isSpnegoEnabled);
} catch (AuthenticationException e) {
throw new IOException(e);
}
InputStream stream = connection.getInputStream();
BufferedReader input = new BufferedReader(new InputStreamReader(
stream, "UTF-8"));
String line = null;
String lastLine = null;
int errCode = -1;
try {
while ((line = input.readLine()) != null) {
out.println(line);
lastLine = line;
}
} finally {
input.close();
}
if (lastLine.endsWith(NamenodeFsck.HEALTHY_STATUS)) {
errCode = 0;
} else if (lastLine.endsWith(NamenodeFsck.CORRUPT_STATUS)) {
errCode = 1;
} else if (lastLine.endsWith(NamenodeFsck.NONEXISTENT_STATUS)) {
errCode = 0;
} else if (lastLine.contains("Incorrect blockId format:")) {
errCode = 0;
} else if (lastLine.endsWith(NamenodeFsck.DECOMMISSIONED_STATUS)) {
errCode = 2;
} else if (lastLine.endsWith(NamenodeFsck.DECOMMISSIONING_STATUS)) {
errCode = 3;
}
return errCode;
}
NameNode响应fsck命令
在idea里使用全局搜索,在NameNodeHttpServer类的setupServlets方法中,找到httpServer.addInternalServlet(“fsck”, “/fsck”, FsckServlet.class, true),证明namenode确实使用Servlet响应请求
在FsckServlet类的doGet方法中,找到new NamenodeFsck(conf, nn, bm.getDatanodeManager().getNetworkTopology(), pmap, out,
totalDatanodes, remoteAddress).fsck()。
我们看看这个NamenodeFsck类的构造方法:
NamenodeFsck(Configuration conf, NameNode namenode,
NetworkTopology networktopology,
Map<String,String[]> pmap, PrintWriter out,
int totalDatanodes, InetAddress remoteAddress) {
this.conf = conf;
this.namenode = namenode;
this.networktopology = networktopology;
this.out = out;
this.totalDatanodes = totalDatanodes;
this.remoteAddress = remoteAddress;
this.bpPolicy = BlockPlacementPolicy.getInstance(conf, null,
networktopology,
namenode.getNamesystem().getBlockManager().getDatanodeManager()
.getHost2DatanodeMap());
//
for (Iterator<String> it = pmap.keySet().iterator(); it.hasNext();) {
String key = it.next();
if (key.equals("path")) { this.path = pmap.get("path")[0]; }
else if (key.equals("move")) { this.doMove = true; }
else if (key.equals("delete")) { this.doDelete = true; }
else if (key.equals("files")) { this.showFiles = true; }
else if (key.equals("blocks")) { this.showBlocks = true; }
else if (key.equals("locations")) { this.showLocations = true; }
else if (key.equals("racks")) { this.showRacks = true; }
else if (key.equals("storagepolicies")) { this.showStoragePolcies = true; }
else if (key.equals("openforwrite")) {this.showOpenFiles = true; }
else if (key.equals("listcorruptfileblocks")) {
this.showCorruptFileBlocks = true;
} else if (key.equals("startblockafter")) {
this.currentCookie[0] = pmap.get("startblockafter")[0];
} else if (key.equals("includeSnapshots")) {
this.snapshottableDirs = new ArrayList<String>();
} else if (key.equals("blockId")) {
this.blockIds = pmap.get("blockId")[0];
}
}
}
可以看到,pmap保存了命令的参数,如匹配成功,则把对应的标志位置为true。而fsck方法真正响应了请求
public void fsck() {
final long startTime = Time.monotonicNow();
try {
//如果blockIDs不为空,则说明这条命令希望检查这些块的信息
if(blockIds != null) {
String[] blocks = blockIds.split(" ");
StringBuilder sb = new StringBuilder();
sb.append("FSCK started by " +
UserGroupInformation.getCurrentUser() + " from " +
remoteAddress + " at " + new Date());
out.println(sb.toString());
sb.append(" for blockIds: \n");
for (String blk: blocks) {
if(blk == null || !blk.contains(Block.BLOCK_FILE_PREFIX)) {
out.println("Incorrect blockId format: " + blk);
continue;
}
out.print("\n");
blockIdCK(blk);
sb.append(blk + "\n");
}
LOG.info(sb.toString());
namenode.getNamesystem().logFsckEvent("/", remoteAddress);
out.flush();
return;
}
String msg = "FSCK started by " + UserGroupInformation.getCurrentUser()
+ " from " + remoteAddress + " for path " + path + " at " + new Date();
LOG.info(msg);//用户的fsck操作会被打到namenode的log里。
out.println(msg);
namenode.getNamesystem().logFsckEvent(path, remoteAddress);
if (snapshottableDirs != null) {
SnapshottableDirectoryStatus[] snapshotDirs = namenode.getRpcServer()
.getSnapshottableDirListing();
if (snapshotDirs != null) {
for (SnapshottableDirectoryStatus dir : snapshotDirs) {
snapshottableDirs.add(dir.getFullPath().toString());
}
}
}
//这里就是找到文件对应的inode
final HdfsFileStatus file = namenode.getRpcServer().getFileInfo(path);
if (file != null) {
//根据是否汇报错误块决定流程
if (showCorruptFileBlocks) {
listCorruptFileBlocks();
return;
}
//根据标志位决定是否展示存储方法
if (this.showStoragePolcies) {
storageTypeSummary = new StoragePolicySummary(
namenode.getNamesystem().getBlockManager().getStoragePolicies());
}
Result res = new Result(conf);
check(path, file, res);//进一步根据构造方法中赋予的标志位决定打印信息
out.println(res);
out.println(" Number of data-nodes:\t\t" + totalDatanodes);
out.println(" Number of racks:\t\t" + networktopology.getNumOfRacks());
if (this.showStoragePolcies) {
out.print(storageTypeSummary.toString());
}
out.println("FSCK ended at " + new Date() + " in "
+ (Time.monotonicNow() - startTime + " milliseconds"));
// If there were internal errors during the fsck operation, we want to
// return FAILURE_STATUS, even if those errors were not immediately
// fatal. Otherwise many unit tests will pass even when there are bugs.
if (internalError) {
throw new IOException("fsck encountered internal errors!");
}
// DFSck client scans for the string HEALTHY/CORRUPT to check the status
// of file system and return appropriate code. Changing the output
// string might break testcases. Also note this must be the last line
// of the report.
if (res.isHealthy()) {
out.print("\n\nThe filesystem under path '" + path + "' " + HEALTHY_STATUS);
} else {
out.print("\n\nThe filesystem under path '" + path + "' " + CORRUPT_STATUS);
}
} else {
out.print("\n\nPath '" + path + "' " + NONEXISTENT_STATUS);
}
} catch (Exception e) {
String errMsg = "Fsck on path '" + path + "' " + FAILURE_STATUS;
LOG.warn(errMsg, e);
out.println("FSCK ended at " + new Date() + " in "
+ (Time.monotonicNow() - startTime + " milliseconds"));
out.println(e.getMessage());
out.print("\n\n" + errMsg);
} finally {
out.close();
}
}
我们最后看看check方法如何决定打印信息的,基本都写在了if里
void check(String parent, HdfsFileStatus file, Result res) throws IOException {
String path = file.getFullName(parent);
boolean isOpen = false;
if (file.isDir()) {
if (snapshottableDirs != null && snapshottableDirs.contains(path)) {
String snapshotPath = (path.endsWith(Path.SEPARATOR) ? path : path
+ Path.SEPARATOR)
+ HdfsConstants.DOT_SNAPSHOT_DIR;
HdfsFileStatus snapshotFileInfo = namenode.getRpcServer().getFileInfo(
snapshotPath);
check(snapshotPath, snapshotFileInfo, res);
}
byte[] lastReturnedName = HdfsFileStatus.EMPTY_NAME;
DirectoryListing thisListing;
if (showFiles) {
out.println(path + " <dir>");
}
res.totalDirs++;
do {
assert lastReturnedName != null;
thisListing = namenode.getRpcServer().getListing(
path, lastReturnedName, false);
if (thisListing == null) {
return;
}
HdfsFileStatus[] files = thisListing.getPartialListing();
for (int i = 0; i < files.length; i++) {
check(path, files[i], res);
}
lastReturnedName = thisListing.getLastName();
} while (thisListing.hasMore());
return;
}
if (file.isSymlink()) {
if (showFiles) {
out.println(path + " <symlink>");
}
res.totalSymlinks++;
return;
}
long fileLen = file.getLen();
// Get block locations without updating the file access time
// and without block access tokens
LocatedBlocks blocks = null;
FSNamesystem fsn = namenode.getNamesystem();
fsn.readLock();
try {
blocks = fsn.getBlockLocations(
fsn.getPermissionChecker(), path, 0, fileLen, false, false)
.blocks;
} catch (FileNotFoundException fnfe) {
blocks = null;
} finally {
fsn.readUnlock();
}
if (blocks == null) { // the file is deleted
return;
}
isOpen = blocks.isUnderConstruction();
if (isOpen && !showOpenFiles) {
// We collect these stats about open files to report with default options
res.totalOpenFilesSize += fileLen;
res.totalOpenFilesBlocks += blocks.locatedBlockCount();
res.totalOpenFiles++;
return;
}
res.totalFiles++;
res.totalSize += fileLen;
res.totalBlocks += blocks.locatedBlockCount();
if (showOpenFiles && isOpen) {
out.print(path + " " + fileLen + " bytes, " +
blocks.locatedBlockCount() + " block(s), OPENFORWRITE: ");
} else if (showFiles) {
out.print(path + " " + fileLen + " bytes, " +
blocks.locatedBlockCount() + " block(s): ");
} else {
out.print('.');
}
if (res.totalFiles % 100 == 0) { out.println(); out.flush(); }
int missing = 0;
int corrupt = 0;
long missize = 0;
int underReplicatedPerFile = 0;
int misReplicatedPerFile = 0;
StringBuilder report = new StringBuilder();
int i = 0;
for (LocatedBlock lBlk : blocks.getLocatedBlocks()) {
ExtendedBlock block = lBlk.getBlock();
boolean isCorrupt = lBlk.isCorrupt();
String blkName = block.toString();
DatanodeInfo[] locs = lBlk.getLocations();
NumberReplicas numberReplicas =
namenode.getNamesystem().getBlockManager().countNodes(block.getLocalBlock());
int liveReplicas = numberReplicas.liveReplicas();
res.totalReplicas += liveReplicas;
short targetFileReplication = file.getReplication();
res.numExpectedReplicas += targetFileReplication;
if(liveReplicas < res.minReplication){
res.numUnderMinReplicatedBlocks++;
}
if (liveReplicas > targetFileReplication) {
res.excessiveReplicas += (liveReplicas - targetFileReplication);
res.numOverReplicatedBlocks += 1;
}
//keep track of storage tier counts
if (this.showStoragePolcies && lBlk.getStorageTypes() != null) {
StorageType[] storageTypes = lBlk.getStorageTypes();
storageTypeSummary.add(Arrays.copyOf(storageTypes, storageTypes.length),
fsn.getBlockManager().getStoragePolicy(file.getStoragePolicy()));
}
// Check if block is Corrupt
if (isCorrupt) {
corrupt++;
res.corruptBlocks++;
out.print("\n" + path + ": CORRUPT blockpool " + block.getBlockPoolId() +
" block " + block.getBlockName()+"\n");
}
if (liveReplicas >= res.minReplication)
res.numMinReplicatedBlocks++;
if (liveReplicas < targetFileReplication && liveReplicas > 0) {
res.missingReplicas += (targetFileReplication - liveReplicas);
res.numUnderReplicatedBlocks += 1;
underReplicatedPerFile++;
if (!showFiles) {
out.print("\n" + path + ": ");
}
out.println(" Under replicated " + block +
". Target Replicas is " +
targetFileReplication + " but found " +
liveReplicas + " replica(s).");
}
// count mis replicated blocks
BlockPlacementStatus blockPlacementStatus = bpPolicy
.verifyBlockPlacement(lBlk.getLocations(), targetFileReplication);
if (!blockPlacementStatus.isPlacementPolicySatisfied()) {
res.numMisReplicatedBlocks++;
misReplicatedPerFile++;
if (!showFiles) {
if(underReplicatedPerFile == 0)
out.println();
out.print(path + ": ");
}
out.println(" Replica placement policy is violated for " +
block + ". " + blockPlacementStatus.getErrorDescription());
}
report.append(i + ". " + blkName + " len=" + block.getNumBytes());
if (liveReplicas == 0) {
report.append(" MISSING!");
res.addMissing(block.toString(), block.getNumBytes());
missing++;
missize += block.getNumBytes();
} else {
report.append(" repl=" + liveReplicas);
if (showLocations || showRacks) {
StringBuilder sb = new StringBuilder("[");
for (int j = 0; j < locs.length; j++) {
if (j > 0) { sb.append(", "); }
if (showRacks)
sb.append(NodeBase.getPath(locs[j]));
else
sb.append(locs[j]);
}
sb.append(']');
report.append(" " + sb.toString());
}
}
report.append('\n');
i++;
}
if ((missing > 0) || (corrupt > 0)) {
if (!showFiles && (missing > 0)) {
out.print("\n" + path + ": MISSING " + missing
+ " blocks of total size " + missize + " B.");
}
res.corruptFiles++;
if (isOpen) {
LOG.info("Fsck: ignoring open file " + path);
} else {
if (doMove) copyBlocksToLostFound(parent, file, blocks);
if (doDelete) deleteCorruptedFile(path);
}
}
if (showFiles) {
if (missing > 0) {
out.print(" MISSING " + missing + " blocks of total size " + missize + " B\n");
} else if (underReplicatedPerFile == 0 && misReplicatedPerFile == 0) {
out.print(" OK\n");
}
if (showBlocks) {
out.print(report.toString() + "\n");
}
}
}
小结:
fsck是namenode本身提供的对外接口,通过servlet方式访问调用,至于访问方式,随便,只要提交这个接口请求就行了,hadoop的shell命令行是通过一个工具类使用java提交的,你也可指直接在浏览器拼接url,例如:
http://10.4.19.42:50070/fsck?ugi=hadoop&path=/tmp/hadoop/wordcountjavain&files=1&blocks=1&locations=1&racks=1
等价于hadoop fsck /tmp/hadoop/wordcountjavain -files -blocks -locations -racks
fsck的实质是通过name的大管家FsNamesystem对象(FSDirectory)管理的那套命名空间,及其块汇报上来的信息,从namenode的内存中读取inode的属性及其block信息等,副本数,多少个块,有木有顺坏,这些结果都是现成的,并不需要namenode再去dn找找到对应的块,然后让datanode去检查,所以这种“现成”的结果,即存在namenode内存的信息,就是你fsck得到的结果有时候是过时的,你更改文件一段时间后,才能从fsck到准确的记过,比如我把dn上得文件blk给换一个坏的,这时候namenode没有拿到块汇报信息,你不会从fsck结果立即感知到它坏了。
但是删除等会从fsck得到信息,因为删除的原理前面也介绍过了无论是trash还是skiptrash,都只是把要删除的文件进行标记(寄一本台账,有清理线程周期发布rpc调用对应的dn去删除blk),它直接影响namenode的内存和命名空间(还包括块汇报信息,即dn弄过来的块信息也会因为删除操作而被修改)。
部分参考:https://blog.youkuaiyun.com/tracymkgld/article/details/18044577

















 5709
5709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









