






 本文介绍了Fork/Join框架,主要用于处理分而治之的问题,通过将大任务拆分为小任务,提高CPU利用率。ForkJoinPool中的线程会自动获取并执行其他线程的任务,实现工作密取。文章还提到了Fork-Join的使用范式,通常通过继承ForkJoinTask的子类来创建任务。
本文介绍了Fork/Join框架,主要用于处理分而治之的问题,通过将大任务拆分为小任务,提高CPU利用率。ForkJoinPool中的线程会自动获取并执行其他线程的任务,实现工作密取。文章还提到了Fork-Join的使用范式,通常通过继承ForkJoinTask的子类来创建任务。
Fork-Join:
主要用来处理 分而治之 的问题。
将一个大问题,分割成为一些规模较小的相同问题,以便各个击破,分而治之
注:这些子问题之间没有联系, 如果子问题之间存在联系,就变成了动态规范算法
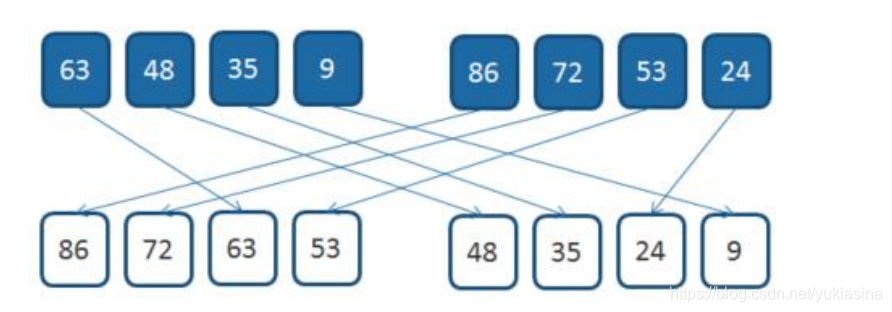
归并排序:
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法 的一个非常典型的应用。将已有序的子序列合并,得到
完全有序的序列;即先使 每个子序列有序,再使子序列段间有序。
若将两个有序表合并成一个有序表,称为
2-
路归并,与之对应的还有多路归 并。
对于给定的一组数据,利用递归与分治技术将数据序列划分成为越来越小的半子表,在对半子表排序后,再用递归方法将排好序的
半子表合并成为越来越大 的有序序列。
为了提升性能,有时我们在半子表的个数小于某个数(比如
15
)的情况下,
对半子表的排序采用其他排序算法,比如插入排序。
归并排序示例如下:

合并后的子表继续合并:
Fork-Join原理:
在必要的情况下,将一个大任务,拆分成若干个小任务,再将一个个小任务运算的结果join汇总。
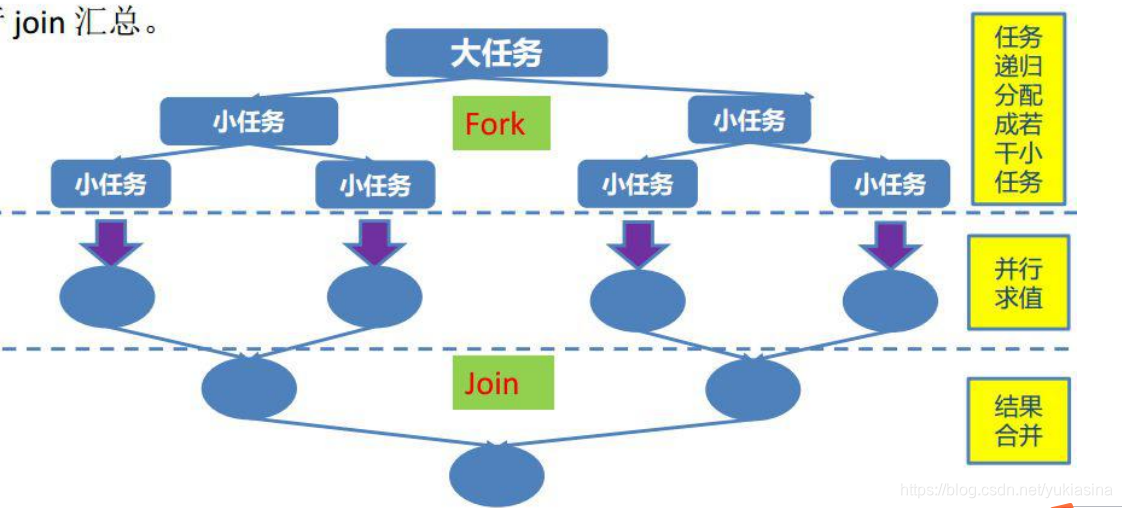
注:工作密取:
即当前线程的task已经被全部执行完毕,则自动取到其他线程的Task池中取出task继续执行
ForkJoinPool 中维护着多个线程(一般为 CPU 核数)在不断地执行 Task,每 个线程除了执行自己职务内的 Task 之外,还会根
据自己工作线程的闲置情况去 获取其他繁忙的工作线程的 Task,如此一来就能能够减少线程阻塞或是闲置的时间,提高 CPU 利
用率。
Fork-Join 使用的标准范式:
我们要使用 ForkJoin 框架,必须首先创建一个 ForkJoin 任务。它提供在任务中执行 fork 和 join 的操作机制,通常我们不直接继
承 ForkjoinTask 类,只需要直接继承其子类。
1. RecursiveAction
,用于没有返回结果的任务
2. RecursiveTask
,用于有返回值的任务
task
要通过
ForkJoinPool
来执行,使用
submit
或
invoke
提交,两者的区别是:invoke
是同步执行,调用之后需要等待任务完
成,才能执行后面的代码; submit 是异步执行。
join()
和
get
方法当任务完成的时候返回计算结果。
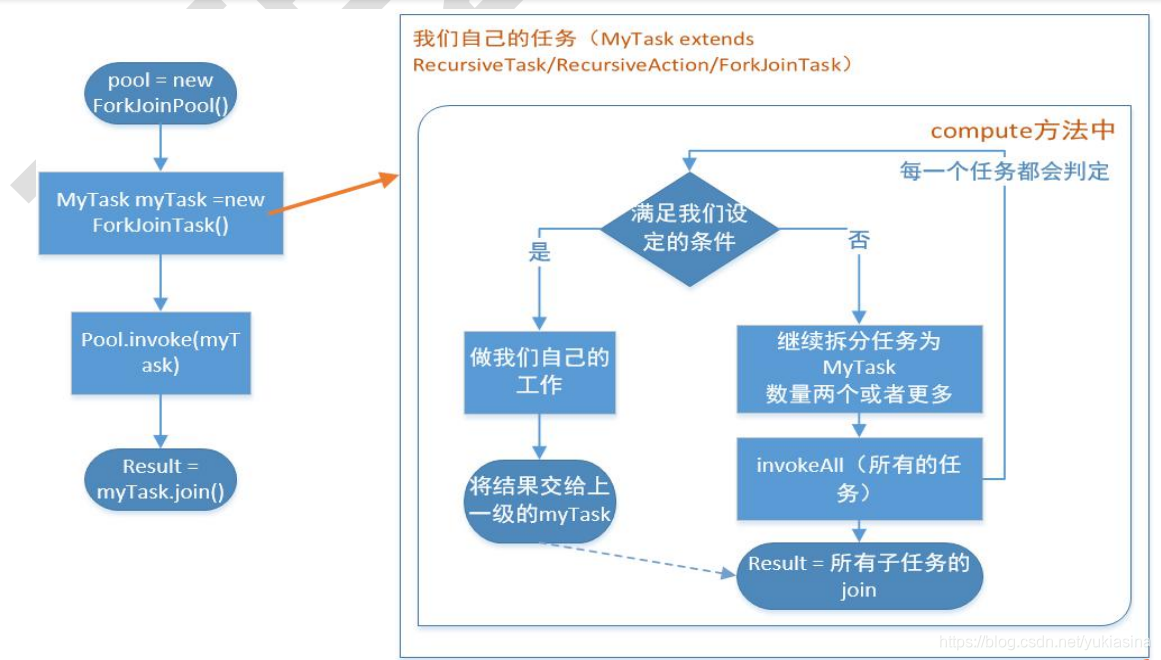
在我们自己实现的
compute
方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成
两个子任务,每个子任务在调用
invokeAll
方法时,又会进入
compute
方法,看看当前子任务是否需要继续分割成孙任务,如果
不需要继续分割,则执行当前子任务并返回结果。使用 join方法会等待子任务执行完并得到其结果。
CountDownLatch:
闭锁,
CountDownLatch
这个类能够使一个线程等待其他线程完成各自的工作后再执行。例如,应用程序的主线程希望在负责启
动框架服务的线程已经启动所有的框架服务之后再执行。
CountDownLatch
是通过一个计数器来实现的,计数器的初始值为初始任务的数量。每当完成了一个任务后,计数器的值就会减
1(CountDownLatch.countDown()
方法)。当计数器值到达
0
时,它表示所有的已经完成了任务,然后在闭锁上等待
CountDownLatch.await()
方法的线程就可以恢 复执行任务。
应用场景:
实现最大的并行性:有时我们想同时启动多个线程,实现最大程度的并行性。
例如,我们想测试一个单例类。如果我们创建一个初始计数为
1
的
CountDownLatch
,并让所有线程都在这个锁上等待,那么我们可以很轻松地完成测试。我们只需调用 一次 countDown()
方法就
可以让所有的等待线程同时恢复执行。
开始执行前等待
n
个线程完成各自任务:例如应用程序启动类要确保在处理用户请求前,所有 N
个外部系统已经启动和运行了
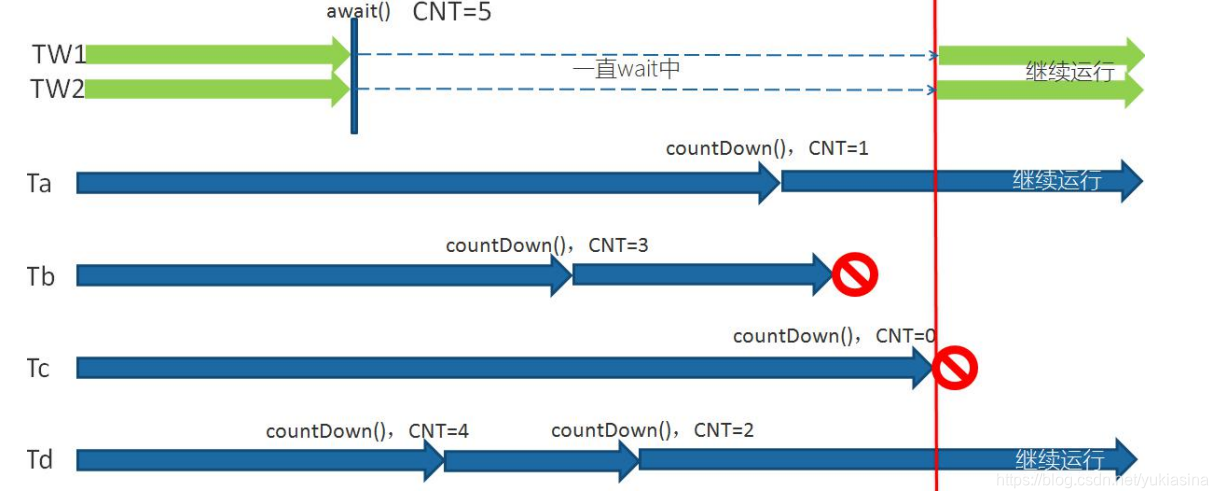
有两个注意点:1.可以await的可以不止一个线程
2.一个线程可以减两次数

















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









