




 本文介绍 Discuz!NT 社区软件中缓存机制的设计与实现过程,探讨了.NET 缓存机制的局限性,并提出了一种基于策略模式的缓存架构。文章详细介绍了缓存设计中采用的技术,包括 XML 和 XPath 的使用,单件模式的应用以及如何解决跨 Web 园共享数据的问题。
本文介绍 Discuz!NT 社区软件中缓存机制的设计与实现过程,探讨了.NET 缓存机制的局限性,并提出了一种基于策略模式的缓存架构。文章详细介绍了缓存设计中采用的技术,包括 XML 和 XPath 的使用,单件模式的应用以及如何解决跨 Web 园共享数据的问题。
现在将Discuz!NT的缓存架构说明如下,先请大家看一下Discuz!NT架构图:
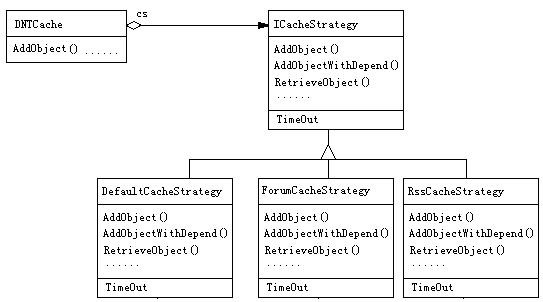 其实这个构架说白了就是一个标准的“策略”模式,为了对比方便,我把策略模式的结构
图放在下面:
其实这个构架说白了就是一个标准的“策略”模式,为了对比方便,我把策略模式的结构
图放在下面:
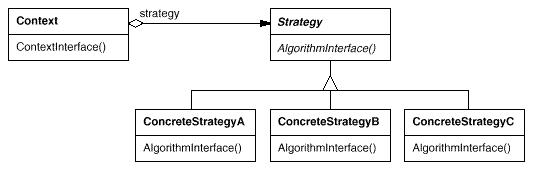
看到了吧,里面的DNTCache就是“策略”模式的应用场景,而DefaultCache , ForumCache ,RssCache等等就是相应的具体策略,每一种策略都会对.net所提供的缓存机制进行一番“订制” ,以实现不同的用途。比如系统DefaultCache在对象到期时提供数据再次加载机制,而ForumCache 而不使用这种机制,另外还有缓存的到期时间几种策略也各不相同,这都是根据具体的应用场景 "量身订制"的。
说到这里,您所要做的就是下载一份源码按上图索骥就可以把整个缓存机制搞清楚。
下面对缓存设计所采用的几种技术做一下简要说明。包括XML,XPATH ,"单件模式" 以及跨 web园共享数据。
首先请看一下代码:(xml xpath)
 3 public virtual void AddObject(string xpath, object o ,string[] files)
4 {
5
6 //整理XPATH表达式信息
7 string newXpath = PrepareXpath(xpath);
8 int separator = newXpath.LastIndexOf("/");
9 //找到相关的组名
10 string group = newXpath.Substring(0,separator );
11 //找到相关的对象
12 string element = newXpath.Substring(separator + 1);
13
14 XmlNode groupNode = objectXmlMap.SelectSingleNode(group);
15 //建立对象的唯一键值, 用以映射XML和缓存对象的键
16 string objectId="";
17
18 XmlNode node = objectXmlMap.SelectSingleNode(PrepareXpath(xpath));
19 if ( node != null)
20 {
21 objectId = node.Attributes["objectId"].Value;
22 }
23 if(objectId=="")
24 {
25 groupNode = CreateNode(group);
26 objectId= Guid.NewGuid().ToString();
27 //建立新元素和一个属性 for this perticular object
28 XmlElement objectElement = objectXmlMap.OwnerDocument.CreateElement(element);
29 XmlAttribute objectAttribute =objectXmlMap.OwnerDocument.CreateAttribute("objectId");
30 objectAttribute.Value = objectId;
31 objectElement.Attributes.Append(objectAttribute);
32 //为XML文档建立新元素
33 groupNode.AppendChild(objectElement);
34 }
35 else
36 {
37 //建立新元素和一个属性 for this perticular object
38 XmlElement objectElement = objectXmlMap.OwnerDocument.CreateElement(element);
39 XmlAttribute objectAttribute =objectXmlMap.OwnerDocument.CreateAttribute("objectId");
40 objectAttribute.Value = objectId;
41 objectElement.Attributes.Append(objectAttribute);
42 //为XML文档建立新元素
43 groupNode.ReplaceChild(objectElement,node);
44 }
45 //向缓存加入新的对象
46 cs.AddObjectWithFileChange(objectId,o,files);
47
48 }
49
3 public virtual void AddObject(string xpath, object o ,string[] files)
4 {
5
6 //整理XPATH表达式信息
7 string newXpath = PrepareXpath(xpath);
8 int separator = newXpath.LastIndexOf("/");
9 //找到相关的组名
10 string group = newXpath.Substring(0,separator );
11 //找到相关的对象
12 string element = newXpath.Substring(separator + 1);
13
14 XmlNode groupNode = objectXmlMap.SelectSingleNode(group);
15 //建立对象的唯一键值, 用以映射XML和缓存对象的键
16 string objectId="";
17
18 XmlNode node = objectXmlMap.SelectSingleNode(PrepareXpath(xpath));
19 if ( node != null)
20 {
21 objectId = node.Attributes["objectId"].Value;
22 }
23 if(objectId=="")
24 {
25 groupNode = CreateNode(group);
26 objectId= Guid.NewGuid().ToString();
27 //建立新元素和一个属性 for this perticular object
28 XmlElement objectElement = objectXmlMap.OwnerDocument.CreateElement(element);
29 XmlAttribute objectAttribute =objectXmlMap.OwnerDocument.CreateAttribute("objectId");
30 objectAttribute.Value = objectId;
31 objectElement.Attributes.Append(objectAttribute);
32 //为XML文档建立新元素
33 groupNode.AppendChild(objectElement);
34 }
35 else
36 {
37 //建立新元素和一个属性 for this perticular object
38 XmlElement objectElement = objectXmlMap.OwnerDocument.CreateElement(element);
39 XmlAttribute objectAttribute =objectXmlMap.OwnerDocument.CreateAttribute("objectId");
40 objectAttribute.Value = objectId;
41 objectElement.Attributes.Append(objectAttribute);
42 //为XML文档建立新元素
43 groupNode.ReplaceChild(objectElement,node);
44 }
45 //向缓存加入新的对象
46 cs.AddObjectWithFileChange(objectId,o,files);
47
48 }
49
为什么要用XML, 主要是为了使用XML中的层次化功能以及相关的结点添加,替换,移除, 还有就是当希望对缓存的结构信息进行“持久化”操作时会很方便等。 XPATH 便于能过层次表达式(hierarchical expression) 对XML文件进行查找搜索。 通过上面或其它的类似代码,就可以构建起一个xml树来管理已加入到系统的缓存对象了。
使用"单件模式"模式生成全局唯一的“应用场景”,因为缓存这种东西通常在存储共享 数据时它的效果最好,编码也最容易实现和管理,同时项目本身基本上就是对经常访问但不 经常改变的数据库数据(可看成是共享数据)进行缓存,所以使用单件模式就顺理成章了。 请看如下代码:
小插曲:
1.项目到了beta版时出现了无法跨web园共享数据的问题。它的表现是这样的,当你在IIS 服务的应用程序池中设置2个或以上的WEB园时,这时你在后台更新缓存时,就是出现缓存 “隔三差五”数据不更新或轮换更新的情况。说白了,就是只有一个应用进程中的数据缓存 被更新,而其余的进程中所有数据还没事人似的保留原有的面貌。这个问题主要是因为static 的数据实例(也就是上面所有的单体代码中的对象)虽然而当前进程中“唯一”,但在其它进程 中却各自都有一个造成的。一开始我也很惊讶,为什么微软不能像提供“全局”钩子那样的技术 一样提供一种跨WEB园来共享数据的技术或关键字呢,不过一转念也猜出了一二分,必定多WEB园 是一种让程序(WEB)跑起来更加安全,稳定快速的“解决方案”。 因为谁都不好说自己的程序 一点BUG没有,即有真有这样的代码,但当遇上运行环境这个因素后,也会表现得有些难以控制。 但微软通过web园这个技术就会把运行在几个不同进程下的程序相互隔离,使其谁也不影响到谁, 即使其中一个进程down了,而其它进程依就会继续正常 "工作" 。因此程序中的对象实例和所有 资源每个进程中都会保存一份,完全相同。而如果引用共享机制就有可能出现当进程共享的数据 或程序对象出现问题时,所有进程就可能都玩完了, 因此就需要进程隔离。
说是这么说,但总也要想个办法解决当时面临的问题吧。记得在豪杰工作期间,一次老梁 给我们开会,其中的一段话我至今还记忆犹新,他说CPU访问内存的速度和访问硬盘的速度在某些 情况下是相近的,如果我没理解的话比如说“虚拟缓存”或最新频繁访问的硬盘区段,这些地方 的代码或文件会有比较高的运行和访问效率。因此,我想到了使用文件标志关联的方法来解决这 个多进程问题。接着就顺理成章的使用了文件修改日期这个属性进行在多进程下缓存是否更新的 依据了,大家可以到开源下载包中的config文件夹下把一个cache.config的文件,对应最新的数 据项再回过头来看如下代码就会一清二楚了:
2.另外需要说明的是在4月份时缓存机制出现了一些问题,比如缓存数据丢失以及在.net2下 的死循环的问题,后来在雪人的建议下采用每个缓存都有缓存标志来解决数据丢失的问题。也就 是如下的代码段:
46 }
47
而死循环的问题主要是因为.net2下的缓存回调加载机制和程序本身的一个BUG造成的,目前 已修正, 大家请放心使用。
目前已开发但还未使用的功能: 1.一键多值:请看DNTCache代码段中的AddMultiObjects(string xpath,object[] objValue) ,获取时使用object[] RetrieveObjectList(string xpath)方法返回即可,这样就可以用一个xpath 来存取一组对象了。 它的实现代码也相对简单,这里就不多说了,只把代码贴在此处。
2.批量移除缓存 它主要是利用XML有按路径层次存储的特点才这样做的,主要是去掉位于当前路径下的所有 子结点的缓存数据。 它的函数声明如下:RemoveObject(string xpath, bool writeconfig) 它的实现代码也相对简单,这里就不多说了, 只把代码贴在此处。
已开发出来,但却去掉了的功能。 在正式版出现之前,后台管理中有记录缓存日志的功能,它的实现方式是基于"访问者"模式实现的 (大家应该可以在项目中找到这个类LogVisitor)。但因为后来不少站长反映日志表操作的过于频繁导 致日志记录急剧增加,而把这部分功能拿下了。我在这里说出来就是想给大家提个醒,对于新功能或新 技术的追求要非常谨慎,要不就会出现您费尽千辛万苦开发的功能,最后却没人买帐就郁闷了。 最后需要说明的就是,为什么要先把这块功能先发到园子里来。因为我们产品的Discuz!NT2.0产品 即将发布,而整个产品的架构也出现了不少变化,而由于缓存结构相对稳定,所以变化的不大。这才在 今天发个BLOG讲给大家的,下一篇关于DISCUZ!NT架构的文章要等到正式版发布之后了。到时大家下 载代码之后再对照新代码给大家聊聊这个产品的其它设计思路(按我的理解)。

















 8517
8517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









