




 本文介绍了数据预处理中的归一化技术,讲解了为什么需要进行归一化,通过公式展示了归一化的操作,并给出了如何在Python的sklearn库中实现这一过程。内容包括导入数据、理解归一化的概念、使用示例以及实际操作步骤。
本文介绍了数据预处理中的归一化技术,讲解了为什么需要进行归一化,通过公式展示了归一化的操作,并给出了如何在Python的sklearn库中实现这一过程。内容包括导入数据、理解归一化的概念、使用示例以及实际操作步骤。
导入
什么是特征预处理?
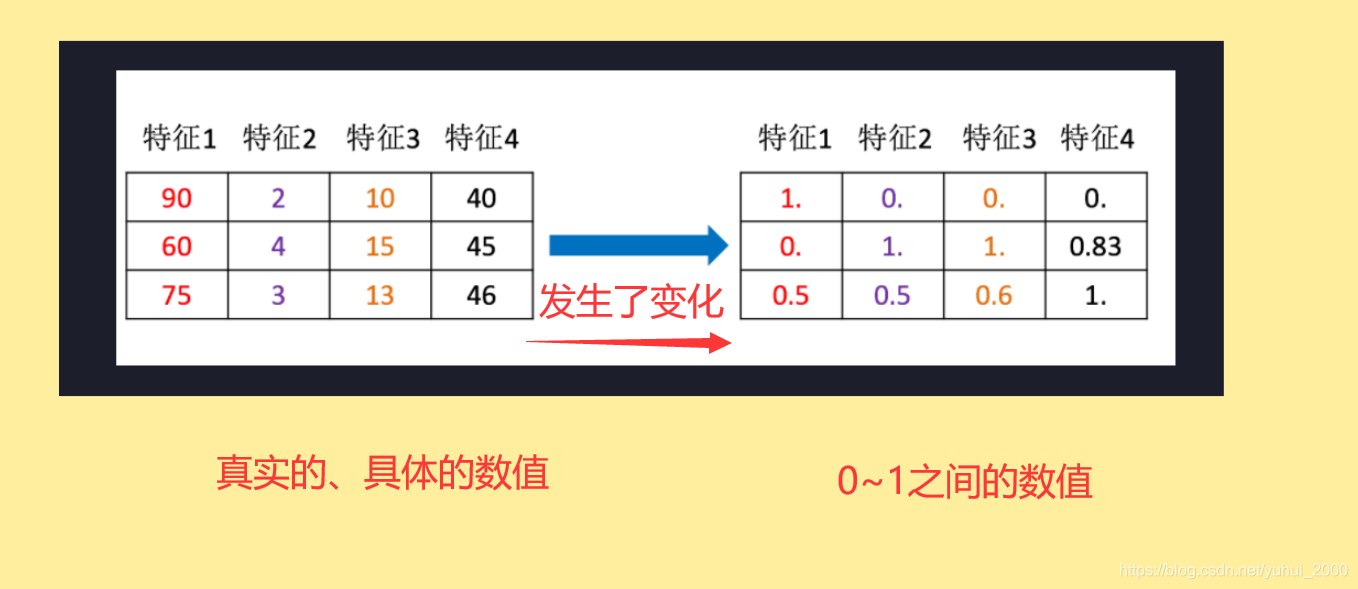
特征预处理
什么是特征预处理?
# scikit-learn的解释
provides several common utility functions and transformer classes to change raw feature vectors into a representation that is more suitable for the downstream estimators.

包含内容

如何在sklearn中实现特征预处理
sklearn.preprocessing
思考:我们为什么要进行归一化/标准化?

举例说明
约会对象数据
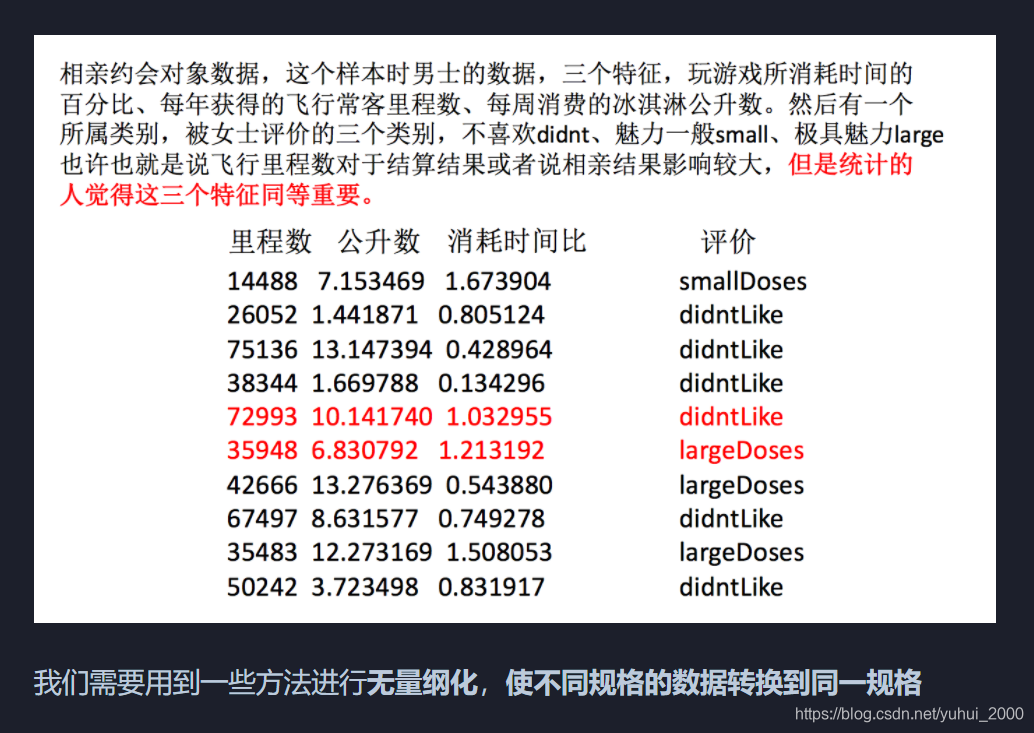
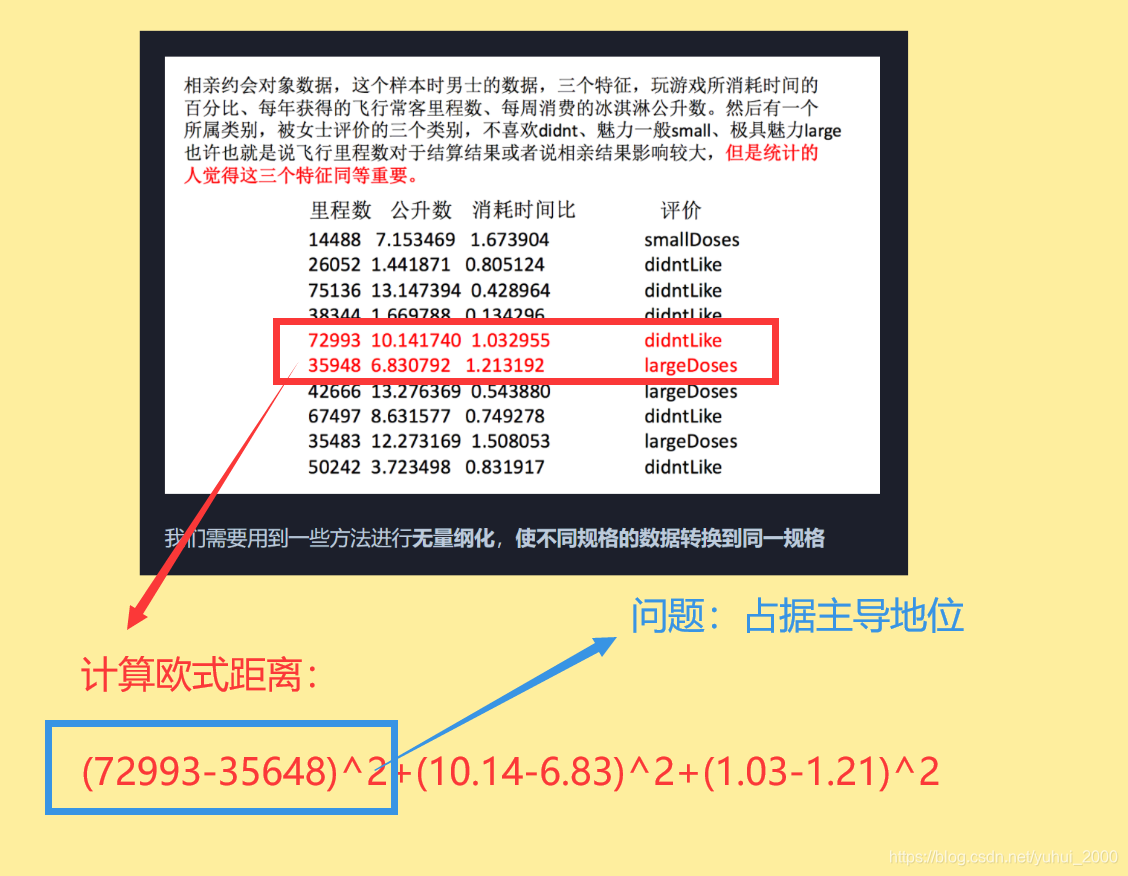
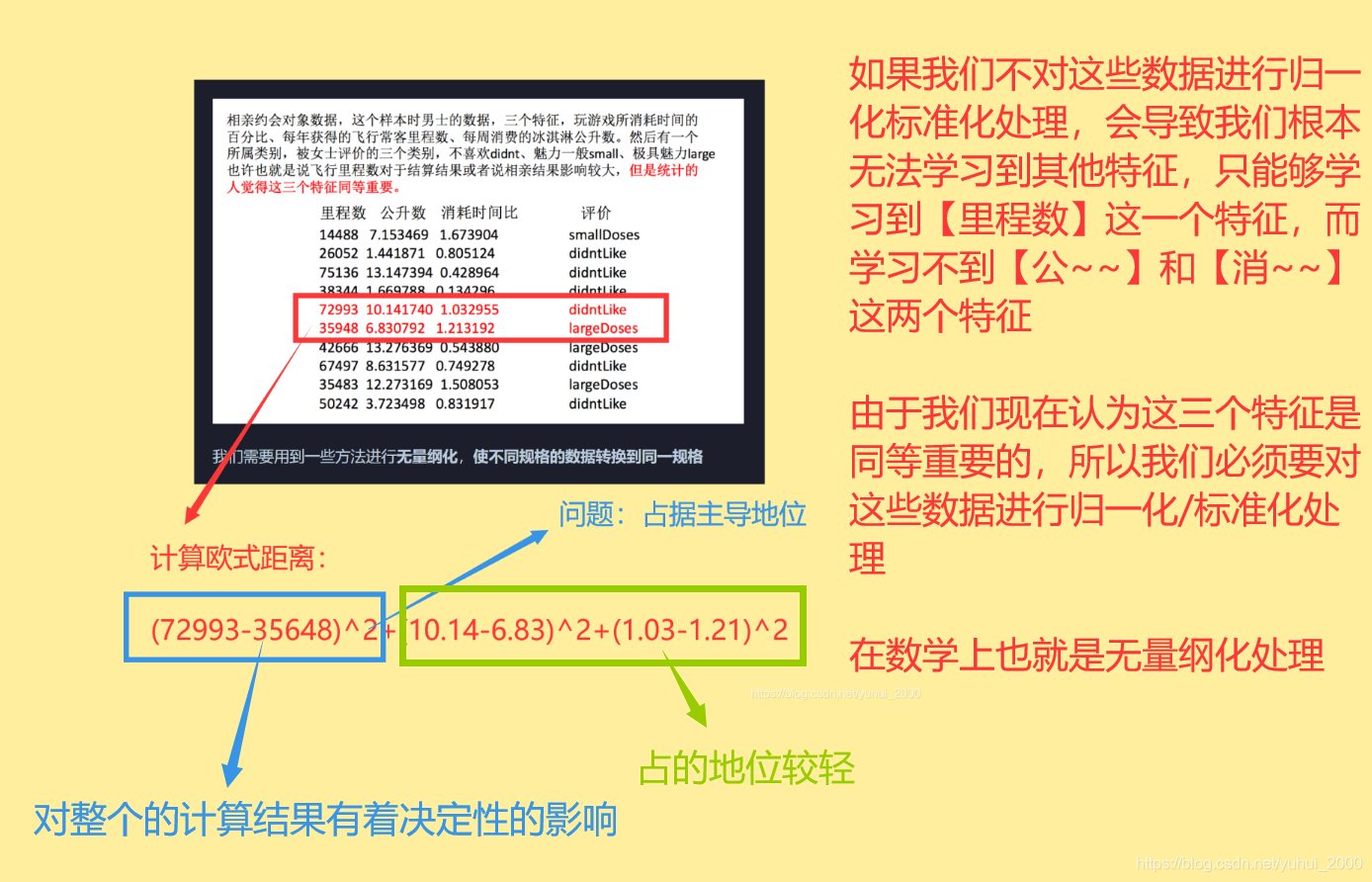
我们需要采取一些措施对数据进行无量纲化处理,使得不同规格的数据转到同一规格。
归一化
什么是归一化呢?
通过对原始数据进行变换把数据映射到(默认为[0,1],可以根据需要调整)之间
公式
X′=x−minmax−min X^{\prime}=\frac{x-min}{max-min} X′=max−minx−min
X′′=X′∗(mx−mi)+mi X^{\prime\prime}=X^{\prime}*(mx-mi)+mi X
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









