










什么是微信机器人
通过技术手段(如模拟用户操作或调用接口)自动执行微信相关任务的程序,例如自动回复消息、管理群聊、推送通知等。
什么是wechaty
Wechaty 是一个开源的微信机器人框架,支持通过简洁的 API 快速构建微信自动化工具。它底层兼容多种协议(如网页版、iPad 协议等),并提供了跨平台、多语言的支持。

- 多协议支持:适配微信网页版、iPad、Mac 等协议,降低被封禁风险。
- 多语言开发:支持 JavaScript/TypeScript(主流)、Python、Go、Java 等。
- 模块化设计:提供插件系统(如消息持久化、状态管理),扩展性强。
- 活跃社区:GitHub 上有大量开源项目案例和开发者讨论。
正文
文献自动检索架构
因为经常写文章和专利文档,需要大量文献做支撑,但检索实在麻烦,就萌生了给团队写一个微信机器人自动检索文献的想法。
架构如下:
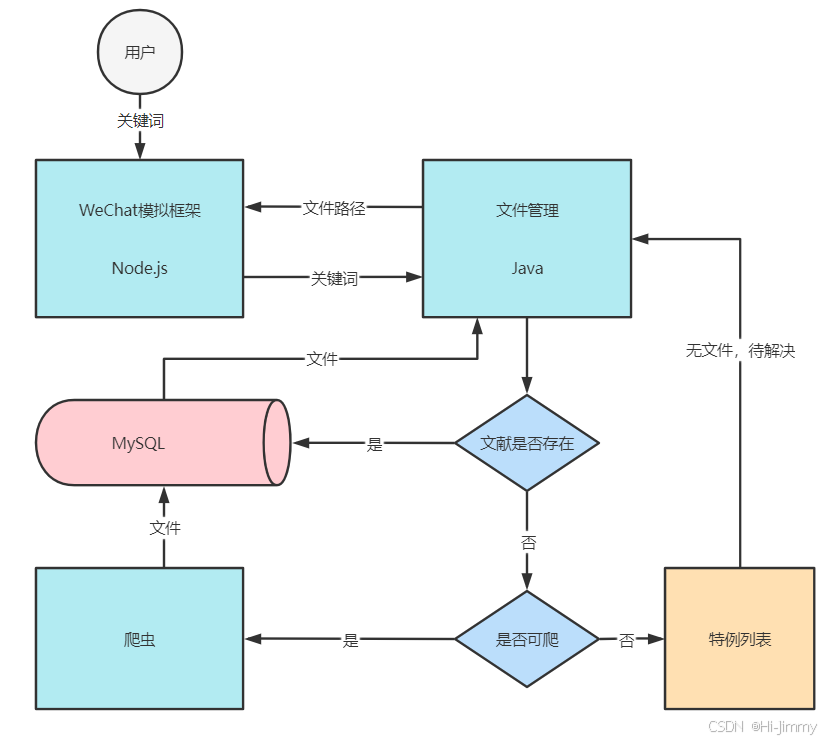
- 在加入微信机器人的微信群内输入文献编号或名称
- WeChat架构捕获聊天内容,并获取关键词并通过Java程序判断是否在数据库已存在该文献,若存在直接返回,若不存在进行下一步
- 数据库缓存不存在文献时,通过Python的是否可爬程序判断,若可爬,则爬虫尝试获取文献(是否可爬取决于是否是免费开源的文献)
- 若不可爬则放入特例数据库并通过Java做记录,以后直接返回不可爬
WeChat架构(Node.js)
环境:node 版本 >16
先克隆代码,该代码基于WeChat:
git clone https://github.com/lizhounet/wx-intimate-pro
注册天行数据账号
1、注册: 天行数据
2、申请接口权限
配置后台参数
- 配置天行参数,和其他配置
- 按需求配置定时任务
运行机器人
直接本地运行
Step 1: 安装
克隆本项目,并进入项目根目录执行 npm install安装项目依赖
Step 2: 配置
src/index.js代码中配置applictionToken和platformHostUrl
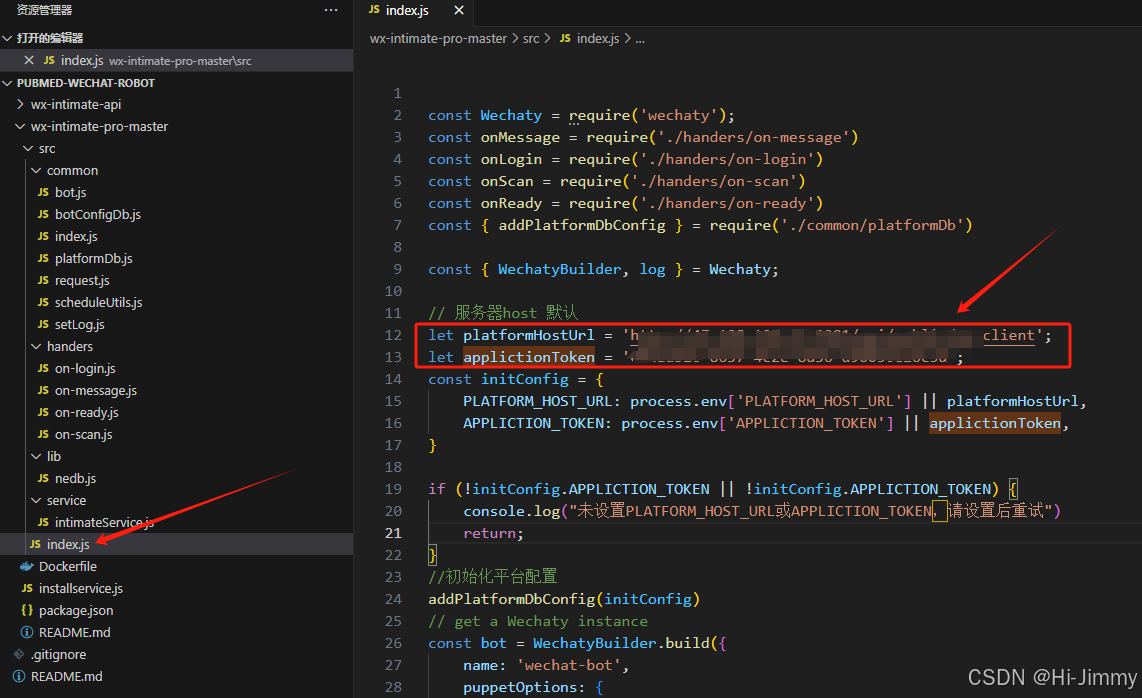
Step 3: 运行
执行命令npm run start,终端会显示二维码,直接扫码登录
爬虫架构(Python)
逻辑思路:
- 使用
Selenium对指定web界面进行解析 - 获取指定关键词,如:
download等 - 尝试下载,若失败表示可能需订阅缴费
- 下载成功后将文件发送给Java文件管理程序
核心代码如下:
driver.py 负责主要使用Selenium的webdriver:
# -*-coding:utf-8 -*-
import os
from selenium import webdriver
import time
import config
from tools.log import Log
log = Log()
class Action():
def __init__(self, driver=None):
if (driver == None):
self.driver = self.create_driver()
else:
self.driver = driver
def create_driver(self):
options = webdriver.ChromeOptions()
profile = {"plugins.plugins_list": [{"enabled": False,
"name": "Chrome PDF Viewer"}],
"download.default_directory": config.platform_config.directory_path,
"download.extensions_to_open": "applications/pdf", # application/pdf
"plugins.always_open_pdf_externally": True}
# 浏览器不提供可视化界面。Linux下如果系统不支持可视化不加这条会启动失败
# options.add_argument('--headless')
if not os.path.exists(config.platform_config.directory_path):
os.mkdir(config.platform_config.directory_path)
options.add_experimental_option('prefs', profile)
# 配置chrome目录
options.binary_location = config.platform_config.chrome_path
try:
return webdriver.Chrome(options=options)
except Exception as e:
log.err("create driver err.")
pass
def find_pdf_element(self, url, value=None, wait_time=15):
href = ""
try:
self.driver.get(url)
self.driver.implicitly_wait(wait_time)
link = self.driver.find_elements_by_xpath(value)
time.sleep(2)
if (len(link) > 0):
href = link[0].get_attribute('href')
except Exception as e:
log.err("find download pdf element href err.")
pass
return href
def get(self, url, wait_time=15):
self.driver.get(url)
self.driver.implicitly_wait(wait_time)
def quit(self):
self.driver.quit()
def find_element(self, value):
return self.driver.find_elements_by_xpath(value)
def get_href(self, element):
return element.get_attribute('href')
def scroll_click(self, link):
try:
self.driver.execute_script("arguments[0].click();", link)
except Exception as e:
log.err("scroll_click err.")
pass
def restart_if_need(self, url):
for i in range(config.platform_config.retry_count):
self.driver.get(url)
time.sleep(config.platform_config.wiat_web_time)
if (self.driver.page_source.upper().find(config.platform_config.verified_protection) > -1):
self.restart()
else:
return
time.sleep(config.platform_config.wiat_web_time)
self.driver.get(url)
def is_verified_protection(self):
return self.driver.page_source.upper().find(config.platform_config.verified_protection) > -1
# 解决安全验证问题
def restart(self):
self.driver.service.stop()
time.sleep(config.platform_config.wiat_web_time)
self.driver = self.create_driver()
def stop(self):
self.driver.delete_all_cookies()
self.driver.service.stop()
time.sleep(config.platform_config.wiat_web_time)
# 判断期刊是否需要订阅
def is_need_subscribe(self):
for item in config.platform_config.no_subscribe_keywords:
if (self.driver.page_source.upper().find(item.upper()) > -1):
return False
for item in config.platform_config.subscribe_keywords:
if (self.driver.page_source.upper().find(item.upper()) > -1):
return True
else:
continue
return False
def is_no_file(self):
for item in config.platform_config.no_file_keywords:
if (self.driver.page_source.upper().find(item.upper()) > -1):
return True
else:
continue
return False
"""
下载文件
返回文件路径
"""
def download_pdf_file(self):
file_nmae = self.get_downloaded_fileName()
# 如果路径为空,认为是下载失败
if (file_nmae == "" or file_nmae == None):
return ""
for i in range(config.platform_config.retry_download_count):
if os.path.exists(file_nmae + ".crdownload") is True:
time.sleep(config.platform_config.wiat_download_time)
else:
return file_nmae # 正常完成
# 如果下载文件不为空,但多次轮循依然没有下载完成,认为是网速过慢导致的下载失败
return "failed"
# 获取下载文件名称
def get_downloaded_fileName(self):
self.driver.execute_script("window.open()")
# switch to new tab
self.driver.switch_to.window(self.driver.window_handles[-1])
# navigate to chrome downloads
self.driver.get('chrome://downloads')
time.sleep(3)
try:
# get downloaded percentage
return config.platform_config.directory_path + self.driver.execute_script(
"return document.querySelector('downloads-manager').shadowRoot.querySelector('#downloadsList downloads-item').shadowRoot.querySelector('div#content #file-link').text")
except Exception as e:
log.err("get pdf file name err.")
pass
doiAnalyze.py负责逻辑判断及主干:
# -*-coding:utf-8 -*-
import requests
from driver import Action
import config
import time
import json
from web_analyze import test as test_search
from web_analyze import ieeexplore_ieee
from web_analyze import onlinelibrary_wiley,actaitalica,mdpi,sciencedirect
from web_analyze import common
from tools.log import Log
log = Log()
def test(driver, url):
return test_search.search(driver,url)
def ieeexplore_ieee_search(driver, url):
return ieeexplore_ieee.search(driver, url)
def onlinelibrary_wiley_search(driver, url):
return onlinelibrary_wiley.search(driver, url)
def actaitalica_search(driver,url):
return actaitalica.search(driver,url)
def mdpi_search(driver,url):
return mdpi.search(driver,url)
def sciencedirect_search(driver,url):
return sciencedirect.search(driver,url)
def other(driver, url):
return common.search(driver, url)
def get_file_by_py(name, driver, url):
names = {
'www.test.com': test,
'ieeexplore.ieee.org': ieeexplore_ieee_search,
'onlinelibrary.wiley.com': onlinelibrary_wiley_search,
'aapm.onlinelibrary.wiley.com':onlinelibrary_wiley_search,
'www.actaitalica.it':actaitalica_search,
'www.mdpi.com':mdpi_search,
'www.sciencedirect.com':sciencedirect_search
}
method = names.get(name, other)
if method:
return method(driver, url)
def directly_download(driver,pdf_href):
log.info(f"pdf href:{pdf_href}")
file_path=""
chrome_action = Action(driver)
chrome_action.restart_if_need(pdf_href)
if (chrome_action.is_need_subscribe() == True):
file_path = "-1"
else:
file_path = chrome_action.download_pdf_file()
if (file_path == ""):
file_path = "-2"
elif (file_path == "failed"):
file_path = "-3"
log.info("-------------------------finished search-------------------------")
return file_path
# 根据文章DOI获取pdf
def get_file_by_doi(doi):
log.info("#########################start doi#########################")
log.info("doi:"+str(doi))
state = 0 # 0=无结果,1=需要订阅,2=正常
pdf_path = "" # pdf路径
domain_url = ""
try:
# 根据doi获取对应的文章地址
doi_web_url = config.platform_config.doi_path+doi
chrome_action = Action()
chrome_action.get(doi_web_url)
# 获取文章真正的地址
article_web_url = chrome_action.driver.current_url
log.info("文章地址article_web_url:"+article_web_url)
if article_web_url=="data:,":#文件直接下载了,没有打开另一网页
pdf_path = directly_download(chrome_action.driver,doi_web_url)
# 统一由本py关闭driver
# 使用quit而非close
chrome_action.quit()
if (pdf_path == None or len(pdf_path) < 1):
state = 0
pdf_path = ""
log.info("下载失败。")
elif (pdf_path == "-1"):
state = 1
pdf_path = ""
log.info("文章需要订阅!")
elif (pdf_path == "-2"):
state = 0
pdf_path = ""
log.info("无可下载的pdf文件。")
elif (pdf_path == "-3"):
state = 0
pdf_path = ""
log.info("网速过慢等原因导致的下载超时。")
else:
state = 2
log.info("文章解析完成,pdf本地地址:" + pdf_path)
else:#需要打开另一网页,解析网页后下载
# 获取域名
domain_url = article_web_url.replace("https://", "").replace("http://", "")
domain_url = domain_url[0: domain_url.find("/")]
if chrome_action.is_no_file(): # 打开doi页面发现不存在文件,但是有域名
state = 0
pdf_path = ""
raise Exception("无可下载的pdf文件。")
# 有部分网址此处会有安全验证,重启以解决
if (chrome_action.is_verified_protection()):
chrome_action.restart()
chrome_action.get(article_web_url)
if (chrome_action.is_need_subscribe() == True):
log.info("文章需要订阅!")
state = 1
else:
# 执行分类查找
pdf_path = get_file_by_py(
domain_url, chrome_action.driver, article_web_url)
# 统一由本py关闭driver
# 使用quit而非close
chrome_action.quit()
if (pdf_path == None or len(pdf_path) < 1):
state = 0
pdf_path = ""
raise Exception("下载失败。")
elif (pdf_path == "-1"):
state = 1
pdf_path = ""
log.info("文章需要订阅!")
elif (pdf_path == "-2"):
state = 0
pdf_path = ""
raise Exception("无可下载的pdf文件。")
elif (pdf_path == "-3"):
state = 0
pdf_path = ""
log.info("网速过慢等原因导致的下载超时。")
else:
state = 2
log.info("文章解析完成,pdf本地地址:"+pdf_path)
except Exception as e:
log.err("执行py异常。")
state = 0
pdf_path = ""
add_unresolve_to_DB(doi, domain_url)#如果没有域名,如直接下载的情况,就不调用该Java接口
pass
data = {
"state": str(state),
"pdf_path": pdf_path
}
log.info("#########################finished doi#########################")
return json.dumps(data)
# 将无法解析的域名及doi调用java接口存至数据库
def add_unresolve_to_DB(doi, domain_url):
try:
requests.get(config.platform_config.unResolveAPI +
"?doi="+doi+"&domain="+domain_url)
except Exception as e:
log.err("调用JAVA的unResolveAPI异常")
pass
main.py主函数:
# -*- coding: UTF-8 -*-
from spyne import Application
from spyne.protocol.soap import Soap11
from spyne.server.wsgi import WsgiApplication
from spyne.protocol.json import JsonDocument
from spyne.protocol.http import HttpRpc
import config
from wsgiref.simple_server import make_server
from app import PyWebService
if __name__ == '__main__':
soap_app = Application([PyWebService], 'WebAnalyzeService',
in_protocol=HttpRpc(validator='soft'),
out_protocol=JsonDocument())
wsgi_app = WsgiApplication(soap_app)
host = config.platform_config.ip
port = config.platform_config.port
server = make_server(host, port, wsgi_app)
print('WebService Started')
print('http://' + host + ':' + str(port) + '/WebAnalyzeService/?wsdl')
server.serve_forever()
文件管理(Java)
主要逻辑思路:
- wechaty首先通过文件管理接口获取文件
- 文件管理接口判断此文件是否有缓存
- 若有缓存直接返回,若没有调用爬虫程序
- 爬虫若有结果返回文件管理,若爬取失败则记录到特例库
WxIntimateController.java实现两个主要接口:
package com.wx.intimate.controller;
import com.wx.intimate.common.ComResult;
import com.wx.intimate.service.WxIntimateService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiImplicitParam;
import io.swagger.annotations.ApiImplicitParams;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
/**
* @Description: 微信机器人调用接口
* @Author: liuxk
* @Date: 2022/10/11 17:08
*/
@RestController
@RequestMapping("/wxIntimate")
@Api(value = "微信机器人调用接口")
public class WxIntimateController {
@Autowired
private WxIntimateService wxIntimateService;
/**
* 下载网站文件
*
* @param keyWord 文章id或者文章名称
* @return
*/
@ApiOperation(value = "下载网站文件", notes = "下载网站文件")
@ApiImplicitParams({
@ApiImplicitParam(name = "keyWord", value = "关键字", dataType = "String", paramType = "query")})
@GetMapping("/getWebFile")
public ComResult getWebFile(@RequestParam("keyWord") String keyWord) {
return wxIntimateService.getWebFile(keyWord);
}
/**
* 存储python爬虫的特例数据
*
* @param
* @return
*/
@ApiOperation(value = "存储python爬虫的特例数据", notes = "存储python爬虫的特例数据")
@ApiImplicitParams({
@ApiImplicitParam(name = "domain", value = "域名", dataType = "String", paramType = "query")})
@GetMapping("/saveUnResolve")
public ComResult saveUnResolve(@RequestParam("domain") String domain,@RequestParam("doi")String doi) {
return wxIntimateService.saveUnResolve(domain,doi);
}
}
效果



















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









