










-
引言:AI "思考"的全新突破
近年来,人工智能(AI)的发展速度可谓惊人,尤其是大型语言模型(LLM)如 ChatGPT,它们能够回答各种问题。然而,面对复杂推理任务时,这些模型的表现却依然存在局限。例如,解决奥数题、编写复杂代码或执行多步逻辑推导等任务,都需要AI像人类一样"思考"多步骤的问题。过去的AI模型往往在这些复杂任务中出现错误。DeepSeek-R1的问世,标志着AI推理能力的一次重大突破:它通过强化学习的反复试错,帮助AI逐渐掌握复杂推理的技巧,像人类一样解决多步问题。而且,DeepSeek-R1是完全开源的,这意味着任何人都可以使用它,而无需依赖收费的商用AI服务。接下来,我们将用通俗易懂的方式,向您介绍DeepSeek-R1的核心思想、训练过程以及它的应用潜力。
核心理念:用强化学习赋予AI"逻辑思维"
DeepSeek-R1的核心理念是模拟人类解题的思维过程来训练AI。想象一下,我们教一个学生解数学题:刚开始,学生并不清楚如何入手,但通过不断尝试、犯错和改正,最终他能够找到正确的解题思路。DeepSeek-R1的训练过程就像这个例子,只不过这里的"学生"是AI,而"老师"则是奖励与惩罚机制。研究者让AI模型在面临复杂问题时尝试解答,然后通过程序自动评估答案是否正确,正确的推理过程会获得奖励,错误的则没有奖励。经过数以万计的训练循环,AI逐渐学会了高效的推理方法,能够解决更复杂的问题。
这种训练方法被称为强化学习(Reinforcement Learning),因为AI会通过"强化"正确的解题方式来不断优化自己的推理能力。DeepSeek-R1的独特之处在于:它在训练初期没有任何人工示范,完全依赖自主探索。研究人员首先让一个基础模型(DeepSeek-V3-Base)直接进入强化学习,就像让AI"孩子"自己玩谜题,而这个模型(称为DeepSeek-R1-Zero)居然自发地发掘了许多强大的解题技巧!例如,它学会了反思自己的答案,尝试不同思路等,这些都是人类解题时常用的策略。通过这种方式,AI逐步发展成了一个具备创造力的"数学家",虽然有时表述还不够完美。
然而,R1-Zero仅仅依靠自我探索,依然存在明显问题:它给出的答案有时难以理解,甚至出现中英文混杂,或者表述不清晰。这就像一个技术极客,思路很独特,但表达方式有时让人摸不着头脑。为了解决这一问题,研究者进行了两轮额外的调整:第一轮是通过一些**"冷启动"示例**来为模型打下基础,教会它基本的回答规范;第二轮是在强化学习后,收集模型在训练过程中表现优秀的解题示例,再混合一些人工整理的示例,进行重新训练。这一过程就像老师帮助学生整理学习笔记,巩固其解题技巧。通过这两轮调整后,模型的回答更加流畅、清晰,能够更好地满足实际需求。
简而言之,DeepSeek-R1的训练过程可以总结为以下几个步骤:
- 预热训练:通过人工整理的问答对,教会模型基本的回答规范。
- 自我尝试:不提供示范,让模型挑战各种推理任务,依靠试错积累经验(强化学习阶段)。
- 优例精炼:收集模型表现优秀的解题示例,再次训练模型,让其学会更清晰、更精确的表达。
- 综合考核:最后进行一次全面的强化学习,确保模型在多类型问题下均衡表现。
通过这样的过程,DeepSeek-R1就像一个通过自学、纠错、再学习的学生,最终成为了一个解决复杂问题的高手。
能力与表现:开源模型媲美顶尖AI
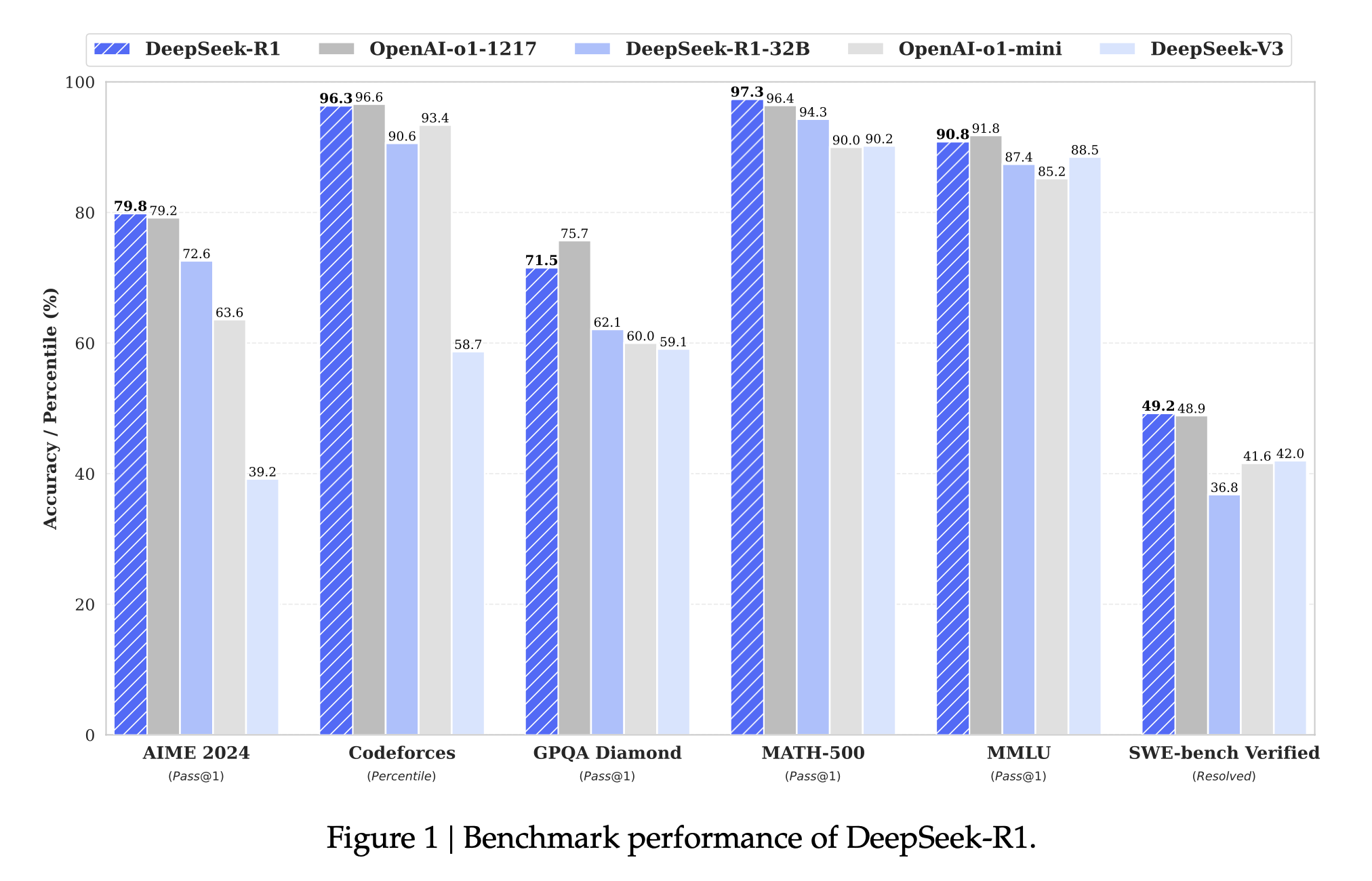
经过上述训练,DeepSeek-R1展现出了令人惊叹的能力,在许多困难测试中,其表现几乎可以与现有最强的闭源AI模型——OpenAI-o1相媲美。例如:
- 在数学考试中,DeepSeek-R1与OpenAI-o1的成绩几乎持平。在美国高中数学竞赛(AIME)测试中,R1答对了79.8%**的问题,而OpenAI-o1答对了**79.2%,两者几乎没有差异。此外,在一份包含500道高难度数学题的测验中,R1的准确率高达97.3%,远超OpenAI-o1的96.4%,这已经超越了许多参赛的人工选手。
- 在编程方面,DeepSeek-R1的表现堪比资深程序员。它参加了编程竞赛平台Codeforces的挑战,最终成绩相当于超过96%的参赛者,甚至略胜OpenAI-o1。这表明R1不仅可以编写简单代码,还能解决竞赛级别的算法问题,成为程序开发者的重要助手。
- 在常识问答和知识测验方面,DeepSeek-R1同样表现优异。在涵盖历史、文学、科学等各类知识的MMLU测试中,R1得分接近91%,几乎与OpenAI-o1相当。而在简单常识问答的SimpleQA测试中,R1更是超越了前一代模型DeepSeek-V3,证明它不仅能够推理,知识问答也更胜一筹。
简而言之,DeepSeek-R1已经在数学、逻辑和编程这三大难题上达到了开源模型的顶峰,甚至与现有的顶级闭源模型平起平坐。这对于开源社区和广大用户来说,意义重大:过去,这些高级能力只属于少数科技公司的封闭模型,而现在,任何人都可以通过一个免费的开源模型享受到这种强大的AI能力。
应用价值:开放、高效的AI智囊
DeepSeek-R1的成功为多个领域带来了广泛的应用价值:
- 教育与学习:凭借其强大的解题和推理能力,DeepSeek-R1可以作为智能教师或辅导员。它能够详细解答奥数题的步骤,提供数学证明的思路,帮助编程学习者理解复杂的代码难点。特别是,R1擅长逐步推理,这对于学习者理解和掌握知识至关重要。
- 科研助理:在科学研究中,推理和计算常常是必不可少的。R1已经能够解答大学甚至研究生水平的数学问题(论文中提到它能处理研究生级别的数学问答)。因此,科研人员可以将R1视为一个"头脑风暴"工具,通过询问复杂问题并参考R1的解答,从而启发新的思路和解决方案。
- 代码开发:由于在编程方面表现出色,DeepSeek-R1可作为编程助手AI,部署在开发工具中。它能够帮助自动生成代码、优化算法,或根据错误提示进行调试。对于企业而言,使用一个开源的高能力模型来替代昂贵的外部API,显得更加经济可控。
- 推动开放研究:DeepSeek-R1的开源特性也具有深远的意义。它的模型权重和代码都已公开,全球的AI研究者可以深入研究并改进它。这种开放性不仅促进了社区的快速发展,也可能为其他领域的AI应用(例如机器人决策等)提供借鉴。
- 成本优势:商业API如OpenAI的收费高昂,而DeepSeek-R1作为开源模型,几乎没有使用成本。即使算上运行费用,DeepSeek团队提供的云服务也远低于OpenAI,处理相同的文本量,R1的费用只是OpenAI的几十分之一。对于中小企业和独立开发者而言,这无疑是一个更具吸引力的选择。
相关研究进展:AI 学会思考的探索之路
DeepSeek-R1的出现并非偶然,而是站在众多前沿研究成果的基础上,推动了人工智能多步推理的发展。以下是一些关键研究阶段:
- Chain-of-Thought方法:早期,研究者发现让AI在给出最终答案之前输出思考过程(即Chain-of-Thought,推理链)能够显著提高推理的准确性。这类似于让AI"大声思考"。通过让模型在思考过程中分步骤输出,它能够更好地解决复杂问题。这一方法的成功为多步推理的普及奠定了基础。
- 人类反馈与对齐:为了提高模型的可靠性,强化学习与人类反馈(RLHF)成为了主流方法。OpenAI的InstructGPT和ChatGPT都采用了这种方式,即通过人类反馈来教会模型什么是好的答案。尽管如此,人类评分依然存在成本高和效率低的挑战。因此,AI自我反馈成为了当前的趋势,DeepSeek-R1便采用了这种AI判别AI的方法,通过程序评估模型的输出,而无需大量人工介入。
- 逐步验证与工具调用:AI自我检查是提升推理能力的另一个方向。例如,给AI配备一个"小助手"来验证每一步推理的正确性。这类似于让AI在解题时每一步都验证自己的推理是否正确。DeepSeek-R1也探索了这种方法,尽管目前仍主要适用于某些领域(如数学证明和代码测试),但结合更多工具来提高推理可靠性是未来研究的重要方向。
- 自我博弈与探索:AlphaGo通过与自己对弈学会围棋,而AI在语言模型中的自我博弈也是一个值得关注的方向。有研究表明,让两个AI模型互相出题、互相验证,可能会加速其学习过程。DeepSeek-R1在这一方面也做出了一些探索,虽然它没有明确提到自我对抗式训练,但其在强化学习过程中与环境的"博弈"显然起到了推动作用。
这些研究的共同目标是让AI学会如何思考、如何推理,并减少对人类反馈的依赖,逐步实现更加自主的推理和决策。DeepSeek-R1的出现,标志着这一步走得更加坚定,证明了AI通过强化学习可以在没有人类示范的情况下,自己探索出复杂问题的解决方案。
总的来说,DeepSeek-R1是AI在推理能力、开放性以及多领域应用方面的一次巨大进步。它不仅能帮助我们在数学、编程等复杂任务中取得突破,还为学术界、工业界甚至个人开发者提供了一个强大的开源工具,开启了AI发展中的新篇章。
随着更多研究者参与到这一领域的探索中,我们有理由相信,未来会有更多像DeepSeek-R1一样的模型诞生,推动AI向着更具推理能力和智能决策的方向发展。而DeepSeek-R1的开源性,也为全球开发者和研究人员提供了更广阔的创新空间,推动人工智能技术的进步。
参考文献:
- [DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning](https://ar5iv.org/html/2501.12948v1#:~:text=> Abstract%3AWe introduce our first,1217 on reasoning)


















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包










