







我们在开发过程中,经常会使用mysql中的order by实现各种排序功能,大部分人都可以非常熟练的使用,但是对其内部如何实现排序的过程不太了解。今天就带大家一起了解一下order by的排序原理,帮助我们以后更好的使用和排查问题。
怎么判断是否用到了排序?
我们准备下列数据
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` smallint(3) D EFAULT NULL,
`name` varchar(64) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
DROP PROCEDURE IF EXISTS userdata;
delimiter ;;
create procedure userdata()
begin
declare i int;
set i=0;
while i<10000 do
insert into user(age,name) values(
round(rand()*18),
concat(char(98+round(rand()*10)+(i div 1000)), char(97+round(rand()*16)+(i % 1000 div 100)), char(97+round(rand()*11)+(i % 100 div 10)), char(97+round(rand()*14)+(i % 10)))
);
set i=i+1;
end while;
end;;
delimiter ;
call userdata();执行下面的sql
select * from user where age=18 order by name desc;
explain select * from user where age=18 order by name desc;观察结果

我们可以观察到执行计划,虽然用到了age索引,但是排序字段没有用到索引,extra 显示 using filesort 表示的就是需要排序,filesort直接翻译过来就是文件排序,filesort分为内部排序和外部排序。mysql 会给每个线程分配一块内存用于排序,称为sort_buffer。当要排序的字段占用内存大于sort_buffer_size时,会借助临时文件来完成排序,叫做外部排序,否则就是内部排序。
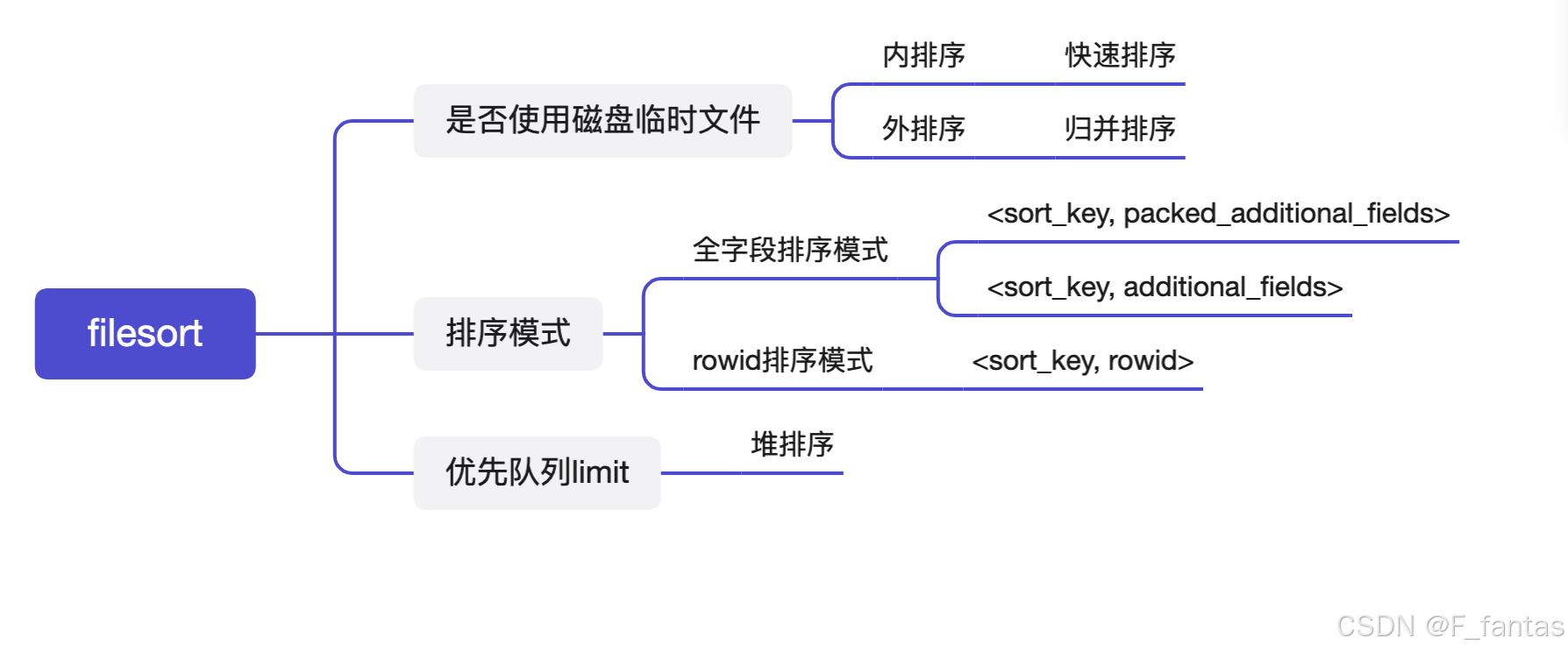
排序模式
order by有三种排序模式。
<sort_key, additional_fields>
表示排序缓冲区元组包含排序键值和查询引用的列(char和varchar类型按照固定长度来存放)。元组按排序键值排序,列值直接从元组中读取。
<sort_key, packed_additional_fields>
与前一种变体类似,但附加列紧密地打包在一起(char和varchar类型按照实际占用的长度来存放),而不是使用固定长度的编码。
<sort_key, rowid>
这表示排序缓冲区元组是包含原始表行的排序键值和行 id 的对。元组按排序键值排序,行 id 用于从表中读取行。
全字段排序模式
<sort_key,packed_additional_fields>和<sort_key,additional_fields>也叫做全字段排序模式,全字段顾名思义所有字段都参与排序过程,我们看看上面的sql用全字段排序的过程:
1、初始化该线程的sort_buffer
2、遍历age索引树,找到age=18的对应的主键id,回主键索引树取id,age,name字段放入sort_buffer,如果sort_buffer放不下,就放到磁盘临时文件。
3、对取出来的数据进行排序,如果有临时文件就用归并排序,没有就用快速排序。
将排序结果返回给客户端
下图是整个排序过程

我们可以通过 optimizer_trace来观察order by使用的什么排序模式。optimizer_trace 是 mysql 中的一个工具,用来详细记录mysql查询优化器在处理查询时所做的决定和步骤。它帮助开发者和数据库管理员深入了解查询是如何被优化和执行的,并且可以用于诊断和调试查询性能问题。排序相关指标(filesort_summary)字段介绍:
memory_available:可用内存(sort buffer大小)
key_size:排序关键字的大小
row_size: 一行数据的大小
num_rows_estimate :预估扫描的行数
num_rows_found:实际扫描行数
num_initial_chunks_spilled_to_disk :使用的临时文件数
peak_memory_used:内存使用峰值
sort_mode:排序模式
在进行观察前,我再介绍两个影响排序模式的变量。
max_length_for_sort_data:是 mysql 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,mysql 就认为单行太大,要换一个排序模式。
sort_buffer:排序内存的大小,当要排序的字段占用内存大于sort_buffer_size时,会借助临时文件来完成排序,叫做外部排序,否则就是内部排序。
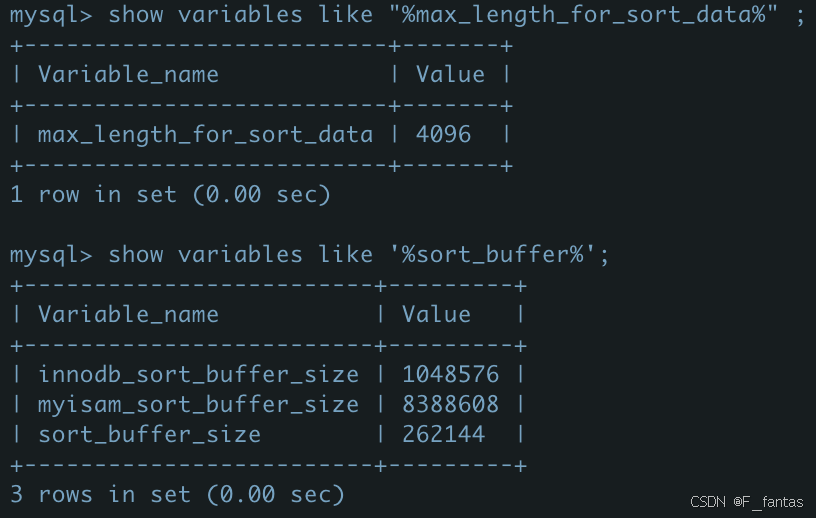
观察前先看看配置,开启optimizer_trace
##开启optimizer_trace,并且查看目前max_length_for_sort_data和sort_buffer的大小
SET optimizer_trace='enabled=on';
show variables like "%max_length_for_sort_data%" ;
show variables like '%sort_buffer%';我们可以看到当前sort_buffer_size=256M,max_length_for_sort_data=4096byte
开始实操了
select * from performance_schema.session_status where variable_name = 'Innodb_rows_read';
##保存sql执行前扫描的行数
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
select * from user where age=18 order by name desc;
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G;
##保存sql执行后扫描的行
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
##获取此次sql扫描的行数
select @b-@a;下图是optimizer_trace结果
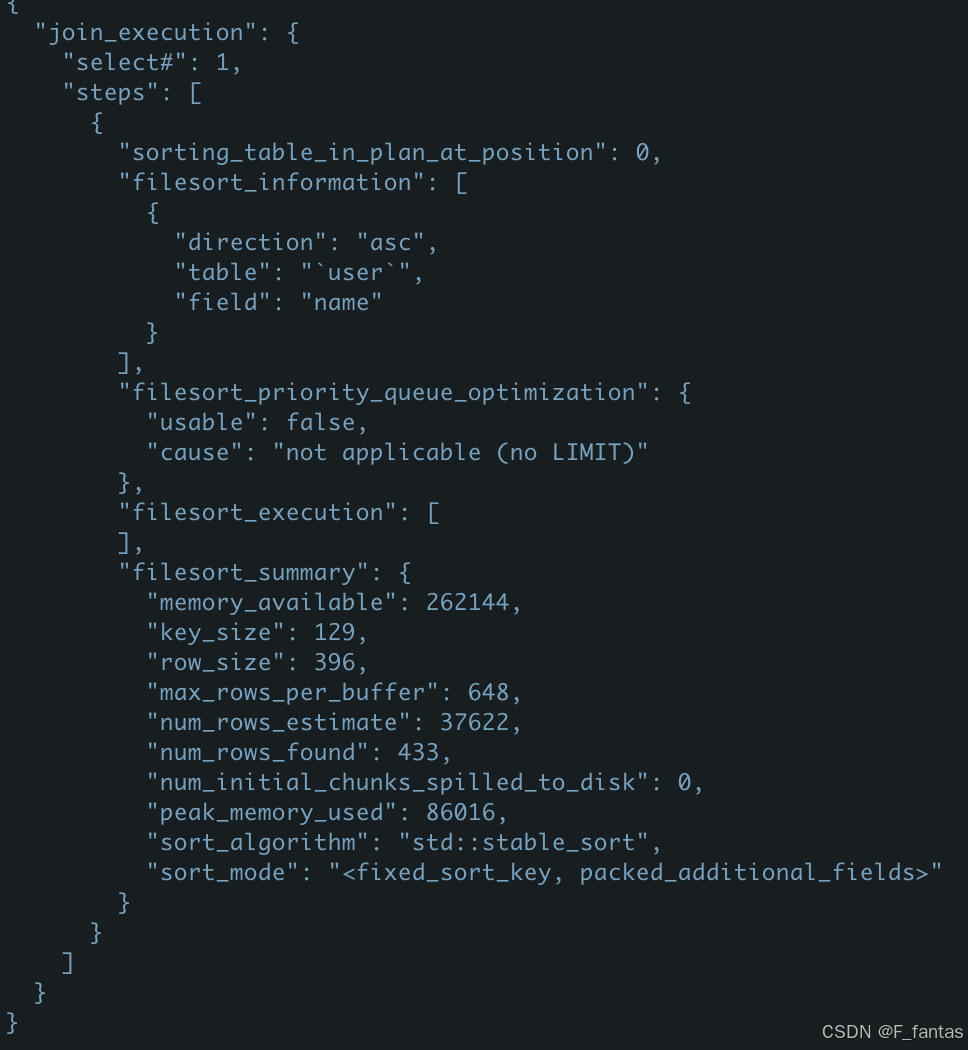
我们可以看到的值sort_mode:<fixed_sort_key,packed_additional_fields>,用到的临时文件为0,此时用的是快速排序算法。
key_size= varchar(64)*2+1;
按照占用最大空间的算法计算一行占用的内存:4(id int)+ 2(age samllint)+ 64*4(name varchar(64))+2(varchar长度记录)+ 1(null 标志)= 265。
但是实际看图中row_size=396,实验发现一个varchar占用是按6个字节来算的,算下来是4+2+64*6+2+1=393;
按照压缩的算法来算:4(id int)+ 2(age samllint)+ 5*4(name varchar(64))+2(varchar长度)+ 1(null 标志)= 29;
不管是29还是393还是256都远远小于4096(目前max_length_for_sort_data的值),所以使用的是全字段排序。
##我们修改max_length_for_sort_data的长度
set max_length_for_sort_data =394;
select * from user where age=18 order by name desc;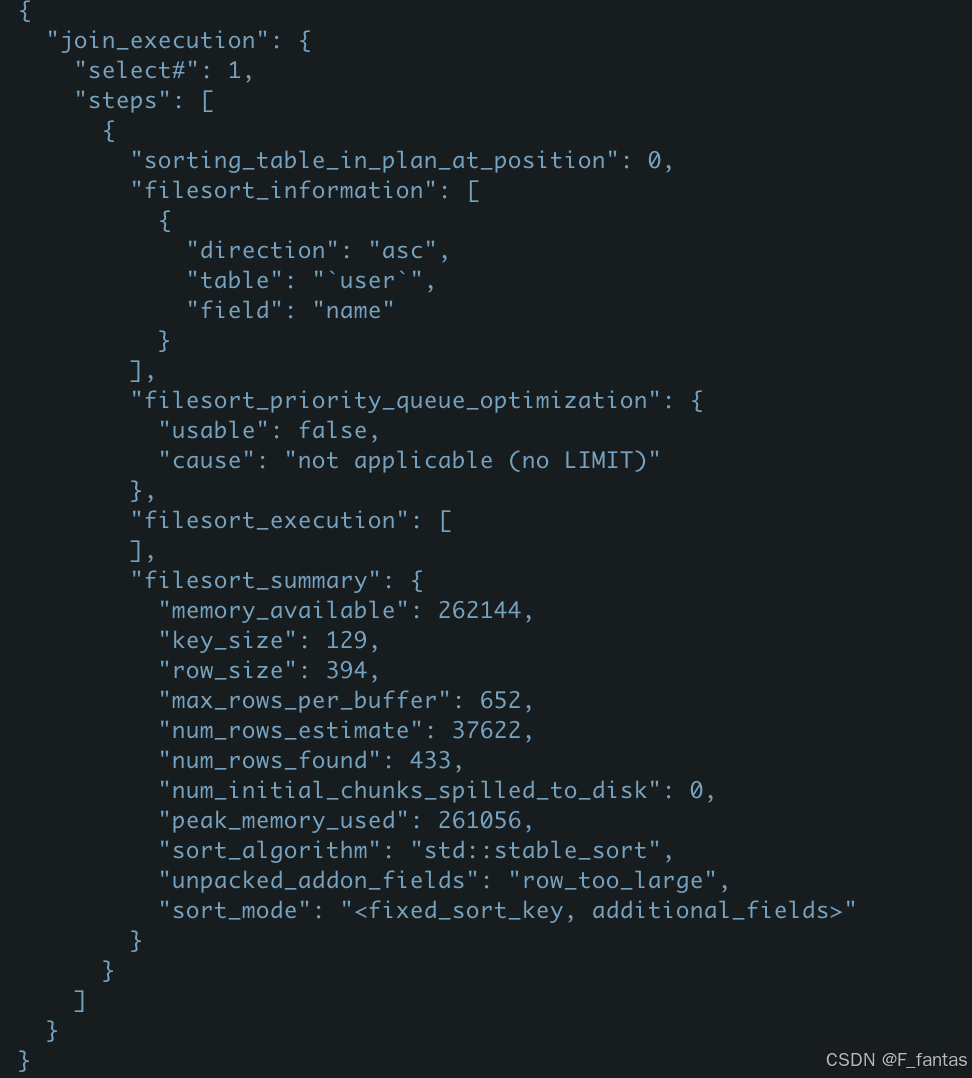
我们可以看到换了一个排序模式,现在sort_mode:<fixed_sort_key, additional_fields>,用到的临时文件为0,此时用的是快速排序算法。
我们前面说过sort_buffer的大小控制着使用外排序还是内排序,前面两个图中我们可以看到num_initial_chunks_spilled_to_disk的值都是0,说明目前sort_buffer的大小满足排序所需的内存。所以我们修改sort_buffer_size的大小,让其选择走外排序。
##为什么是这个值,实验中发现,只要设置的值小于32769就不生效,所以直接设置成它了
set sort_buffer_size=32769;
select * from user where age=18 order by name desc;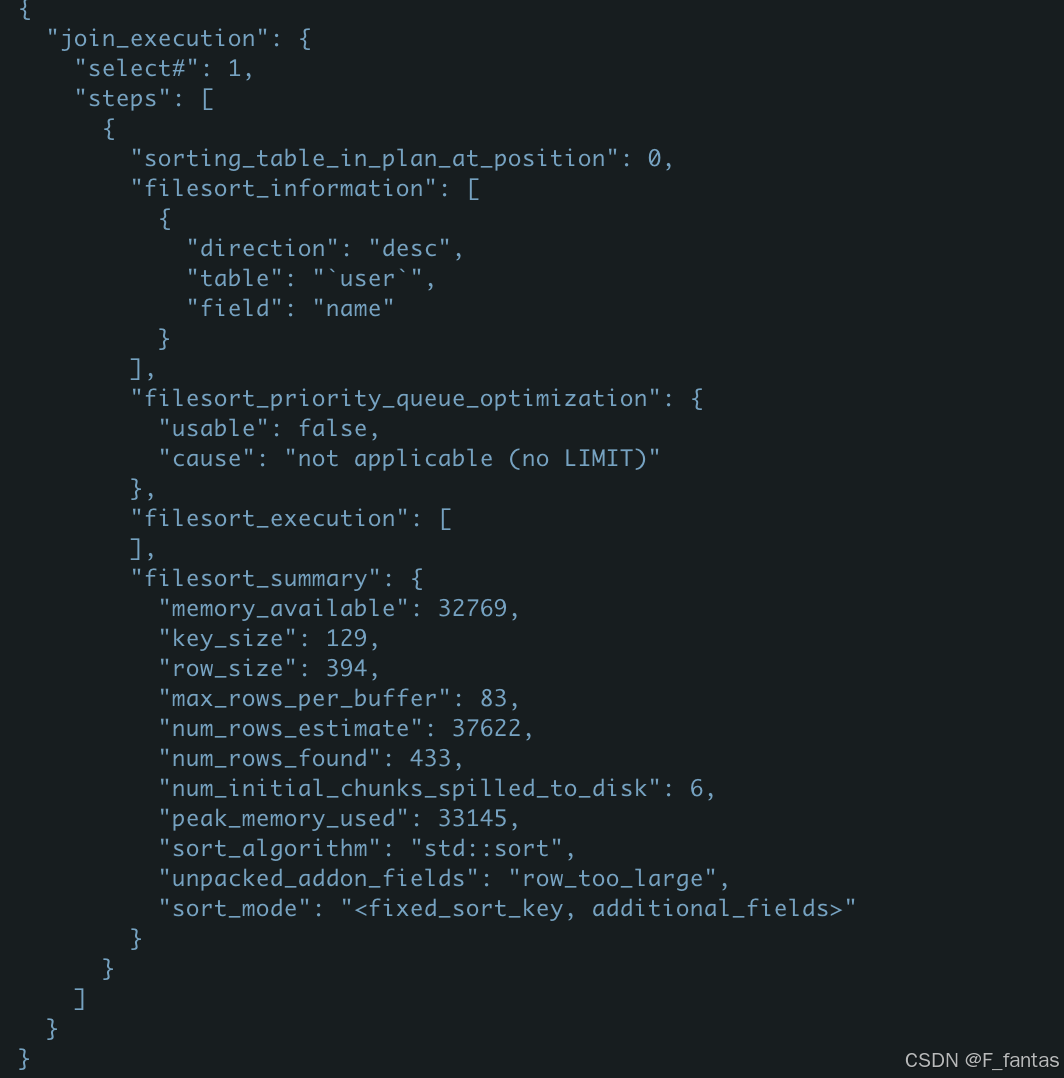
我们现在可以看到用到的临时文件个数为6(num_initial_chunks_spilled_to_disk:6)。因为排序用到的内存大于sort_buffer_size,所以现在需要借助临时文件,用归并排序来实现排序过程,属于外部排序。
内排序为什么采用快速排序算法?
内排序(Internal Sorting): 是指数据量较小,可以完全加载到内存中进行排序。这种情况下,内存访问速度很快,因此算法的时间复杂度和空间复杂度是主要的考量因素,而快速排序的高效性、空间利用率、原地操作使得它在内排序(即数据量较小,能够全部装入内存中)时成为首选。
外排序为什么采用归并排序算法?
外排序(External Sorting): 是指数据量过大,无法全部放入内存,因此需要将数据部分存储在外部设备(如磁盘)上进行排序。这时,磁盘的读写速度成为影响排序性能的重要因素,而归并排序可以处理无法完全装入内存的大数据集,并且在磁盘 I/O 操作中表现良好。其稳定的时间复杂度和顺序读写的特点使其成为处理外部数据排序的理想选择。
rowid排序模式
上面的全字段排序模式中,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。我们现在想要sort_buffer中只存放关键排序数据。继续修改max_length_for_sort_data的值,让其使用rowid模式。
set max_length_for_sort_data =393;
select * from user where age=18 order by name desc;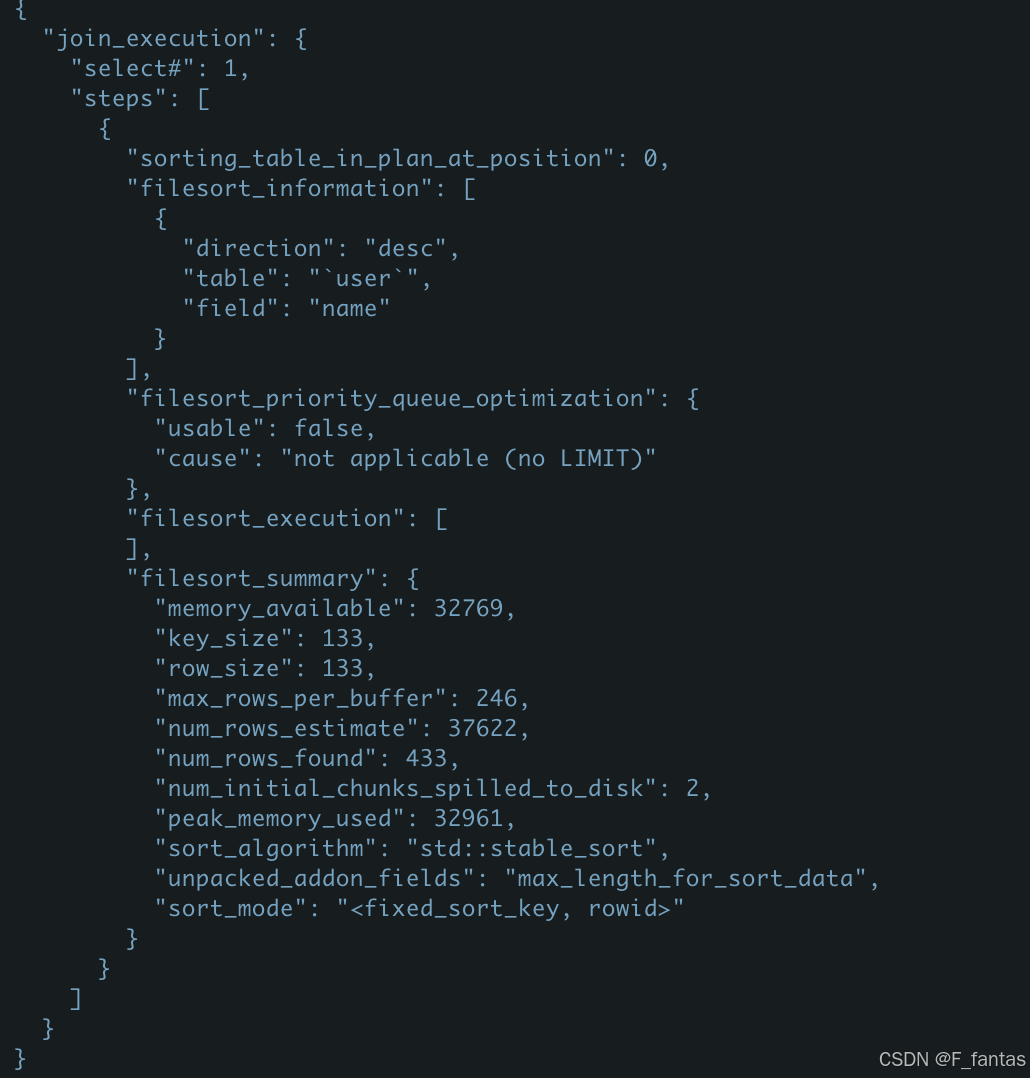
我们可以看到现在的sort_mode值为<fixed_sort_key, rowid>,在相同的sort buffer下,rowid排序用了2个临时文件,上面的全字段排序用了6个临时文件。因为rowid模式只存排序的关键字值和行id。所以最终排完序后还要回主键表读取select的字段。我们看看rowid的排序过程:
初始化该线程的sort_buffer
遍历age索引树,找到age=18的对应的主键id,回主键索引树取id,name字段放入sort_buffer
对sortbuffer中的数据按照name进行排序
按照排序回主键索引树取id,name,age的值返回给客户端
mysql将这种排序方式成为rowid排序

全字段排序 vs rowid排序
| 特点 | 全字段排序 | rowid 排序 |
| 内存占用 | 高,占用较多内存(加载整行数据) | 低,仅加载排序键和 rowid,内存占用较少 |
| 处理大数据 | 不适合,数据量大时容易导致内存不足 | 适合,能够处理大数据量 |
| 效率 | 内存够用时效率高,因为无需额外的查找 | 需要二次查找,排序后要再次获取完整数据行 |
| 排序后的读取 | 排序后直接返回完整数据行 | 排序后根据 rowid 再次查找完整数据行 |
| 适用场景 | 数据量小、行数少,列数较少 | 数据量大、列数多,或者包含大字段的场景 |
| I/O 开销 | I/O 较少,一次性读取所有数据到内存进行排序 | 需要进行额外的随机读取,可能增加 I/O |
全字段排序 更适合数据量较小,或者可以将全部数据放入内存的场景。在这种情况下,避免了二次查找的开销,直接进行排序和输出。
rowid 排序 则更适合大数据量、列数多或数据行较大的情况。通过只对排序键和行指针进行排序,能够减少内存消耗,但需要付出额外的二次查找代价。因此,在内存有限且数据量较大的情况下,rowid 排序是一个更好的选择。
通过根据查询的数据量、行大小以及排序列来选择合适的排序方式,可以提升 mysql 查询的性能。
优先队列优化排序
正常情况下,使用Limit会启用优先队列的优化,但是最终影响是否启用优先队列优化的还是sort buffer排序内存的大小,如果待排序的N条数据比sort_buffer_size小就使用优先队列优化,采用堆排序,否则还是生成临时文件采用归并排序
select * from user where age=18 order by name desc limit 10;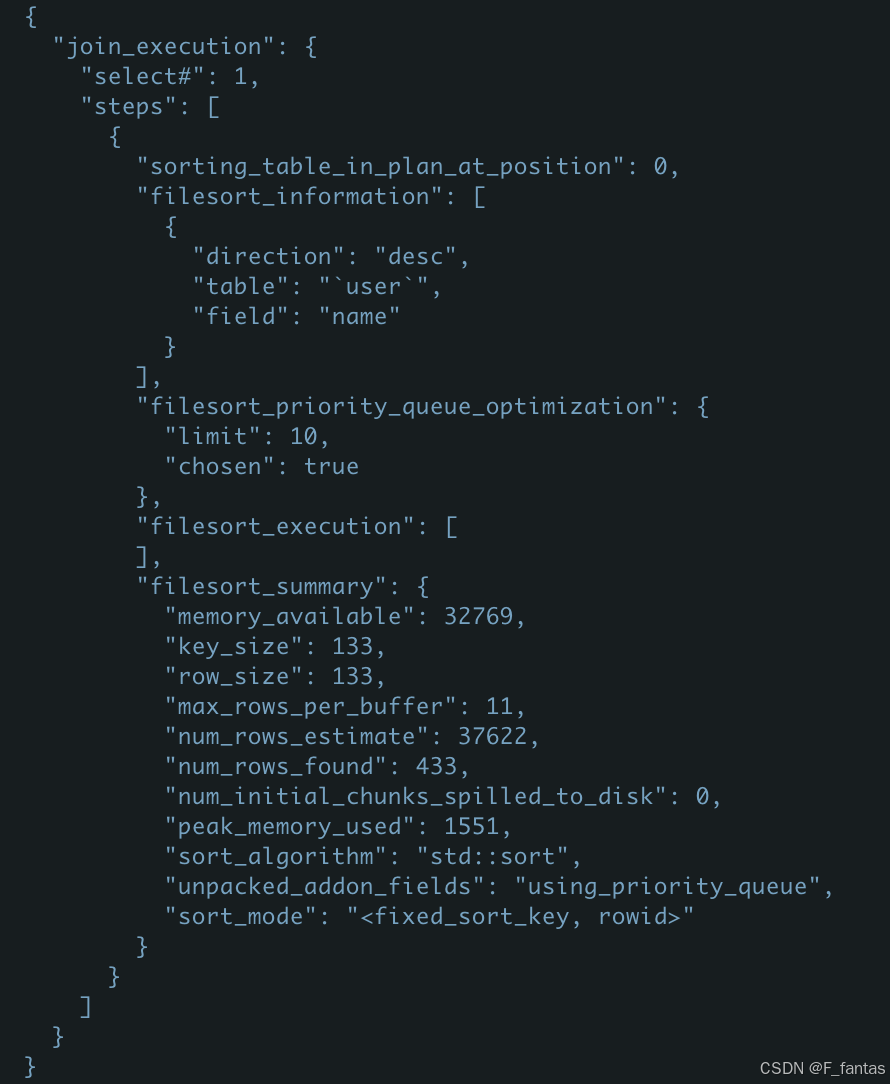
上图中sort_buffer_size大于前10行占用的内存,因此使用优先队列优化。filesort_priority_queue_optimization集合中chosen:true,采用的是堆排序算法。
select * from user where age=18 order by name desc limit 300;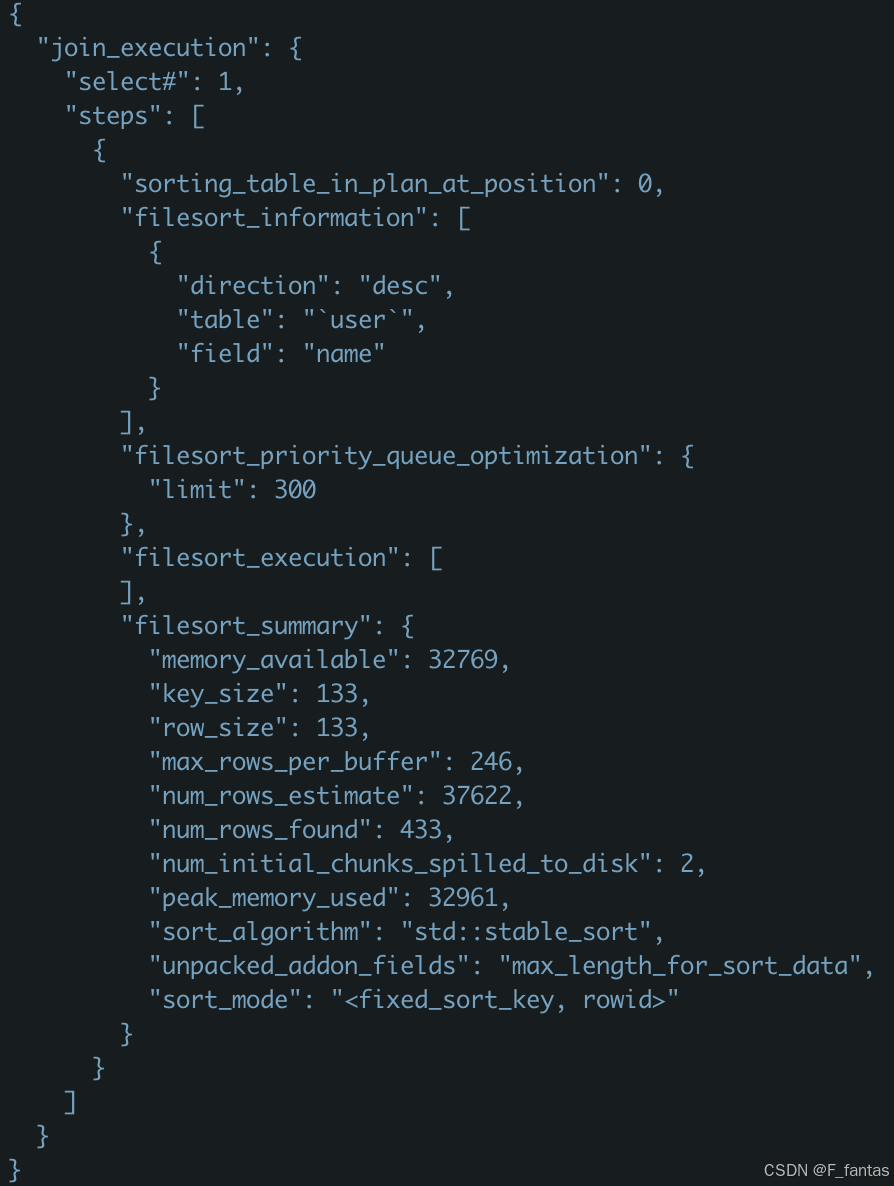
133*300=39900 < 32769,sort_buffer_size小于排序前N列的大小,所以放弃使用优先队列优化。
为什么使用堆排序?
mysql使用limit N意思就是只需要前N条数据有序,不需要将所有数据进行排序。借助堆排序,来构造一个N个数的大根堆或者小根堆来实现前N条数据的排序,可以避免全局排序。这样既可以节省内存又可以节省时间。
排序效率:堆排序的时间复杂度是O(N log n),其中 N 是总数据量,n 是 LIMIT 中指定的记录条数。相比全局排序的 O(N log n),当 n 比 N 小得多时,堆排序的效率会更高。
order by优化
参数调优
1、尝试提高 sort_buffer_size。不管rowid排序还是全字段排序模式,提高这个参数都会提高效率,要根据系统的能力去提高,对于普通场景,sort_buffer_size 的值可以设置在 2MB - 8MB 范围内。如果数据量非常大或排序非常频繁,可以适当设置到 16MB 或更高,但要注意内存的总消耗,因为每个排序线程都会分配该缓冲区。
2、尝试提高 max_length_for_sort_data。提高这个参数,会增加用全字段排序和优先队列优化排序的概率。但是如果设的太高,数据总容量超出sort_buffer_size的概率就增大,明显症状是高的磁盘I/O活动和低的处理器使用率。如果需要返回的列的总长度大max_length_for_sort_data,使用rowid排序,否则使用全字段排序。1024-8192字节之间调整。
语句方面
1、排序字段和返回字段,建议形成覆盖索引。
2、mysql的字段选择要严谨,如字段类型定义长varchar 255,虽然在存放数据的时候,只是放14个字符,但是一旦这个字段被查询到用于排序的时候,就可能会按照255个字符申请内存。
3、带order by的查询应该禁止select *操作,而select具体的必要字段。
参考资料
一次MySQL存储空间撑爆的故障处理和分析 – OracleBlog MySQL :: MySQL 5.7 Reference Manual :: 8.2.1.14 ORDER BY Optimization


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









