






 本文详细介绍了一种基于LSTM的文本分类模型搭建过程,包括定义函数、获取类别数目、参数设置、构建模型各层、初始化及计算损失函数等关键步骤。
本文详细介绍了一种基于LSTM的文本分类模型搭建过程,包括定义函数、获取类别数目、参数设置、构建模型各层、初始化及计算损失函数等关键步骤。
1.定义一个函数,实现文本分类的模型:
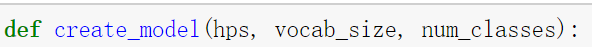
定义一个获得类别数目的api:

测试:

效果:
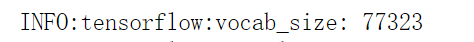
添加上两个变量:

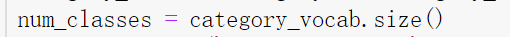
2.将必要的参数从超参数集合里取出来,防止在后面经常用到:

定义输入、输出和drop out用到keep_prob:

定义能记录和保存现在训练到哪一步的global_step:
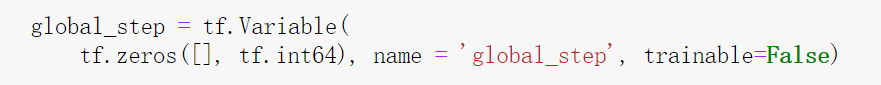
3.正式构建文本分类的模型:
定义embedding层的初始化函数:

定义LSTM层:
定义一个scale:
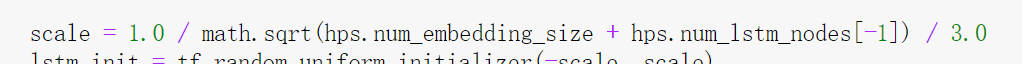
初始化lstm:
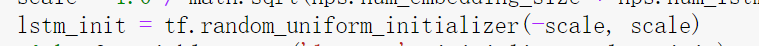

输出是一个三维的矩阵:

将最后一层是输出连接到全连接层上:
初始化全连接层:

计算损失函数:

计算train_op并返回计算的数值:

以上,LSTM文本分类模型就搭建完成了~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









