







给定两个单链表的头节点 headA 和 headB ,请找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交:
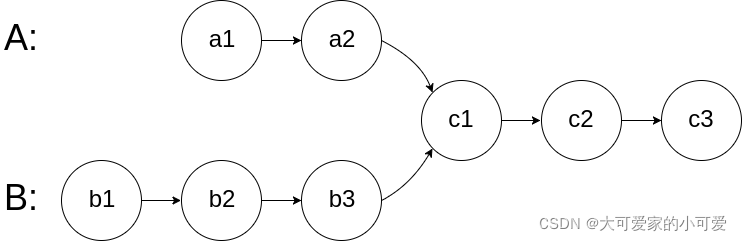
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
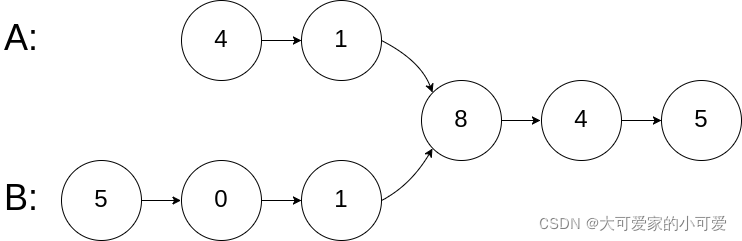
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
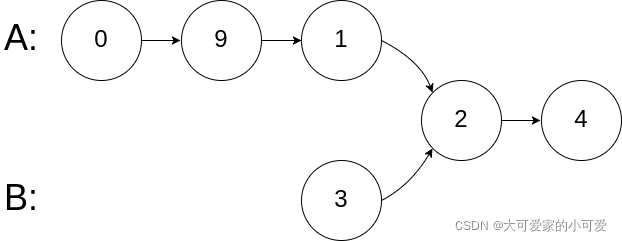
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at ‘2’
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
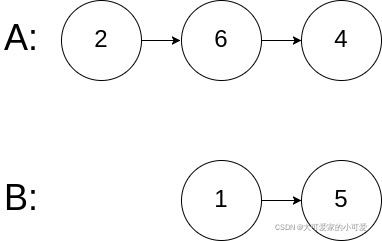
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA 中节点数目为 m
listB 中节点数目为 n
0 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA + 1] == listB[skipB + 1]
进阶:能否设计一个时间复杂度 O(n) 、仅用 O(1) 内存的解决方案?
思路1:双指针
思路如下:首先让第一个指针指向第一个链表的头结点,第二个指针指向第二个链表的头结点。然后开始遍历,如果第一个指针到达第一个链表的结尾,那么就让它指向第二个链表的头结点;同理,如果第二个指针到达第二个链表的头结点,那么就让它指向第一个链表的头结点。若有重合,两指针会在第一个重合的节点相遇,否则都为 nullptr,结束循环。这种思路相当于将两个链表串成了一个,是空间复杂度O(1)的解法。
证明如下:
设第一个链表长度为 A,不重合的长度为 a;第二个链表长度为 B,不重合的长度为 b;两个链表重合部分的长度为 C。那么有 A = a + C; B = b + C。现在开始模拟遍历的情况。
指针 1 走到链表 1 的结尾时,走过了 a + C 的长度,此时指针 1 指向 链表 2 的头结点,走到第一个重合节点时,走了 a + C + b 的长度。而指针 2 走到链表 2 的结尾时, 走过了 b + C 的长度,此时指针 2 指向链表 1 的头结点,走到第一个重合的节点时,走了 b + C + a 的长度。可以看出,若两个有重合节点,则两个指针会在第一个重合节点处相遇。反之,如果没有重合节点,那么最后两指针都会指向 nullptr,结束循环。
代码如下:
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(headA == nullptr || headB == nullptr)
return nullptr;
ListNode* list1 = headA, * list2 = headB;
while(list1 != list2){
list1 = list1 == nullptr ? headB : list1->next;
list2 = list2 == nullptr ? headA : list2->next;
}
return list1;
}
};
时间复杂度:O(n);空间复杂度:O(1)。

思路2:哈希表
这种思路就比较直观:首先遍历第一个链表,将其节点存入哈希表中。然后遍历第二个链表,判断每个节点是否在哈希表中出现,若出现,则后边所有节点都会出现,当前节点即为第一个重合节点;若没有出现,继续遍历下一个,只到遍历完第二个链表后,返回 nullptr。
代码如下:
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(headA == nullptr || headB == nullptr)
return nullptr;
unordered_set<ListNode*> us;
ListNode* list = headA;
while(list){
us.insert(list);
list = list->next;
}
list = headB;
while(list){
if(us.count(list))
return list;
list = list->next;
}
return nullptr;
}
};
时间复杂度:O(n);空间复杂度:O(n)。



















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









