






可以说说你的故事:阻碍、努力、结果成果,意外与转折。
目标网站
网站:某词霸网站
网址:aHR0cHM6Ly93d3cuaWNpYmEuY29tL3RyYW5zbGF0ZQ==
定位分析
分析网页的接口,通过抓包请求的接口分析得到一个结论。我们需要解决sign参数,也就是如下的参数。
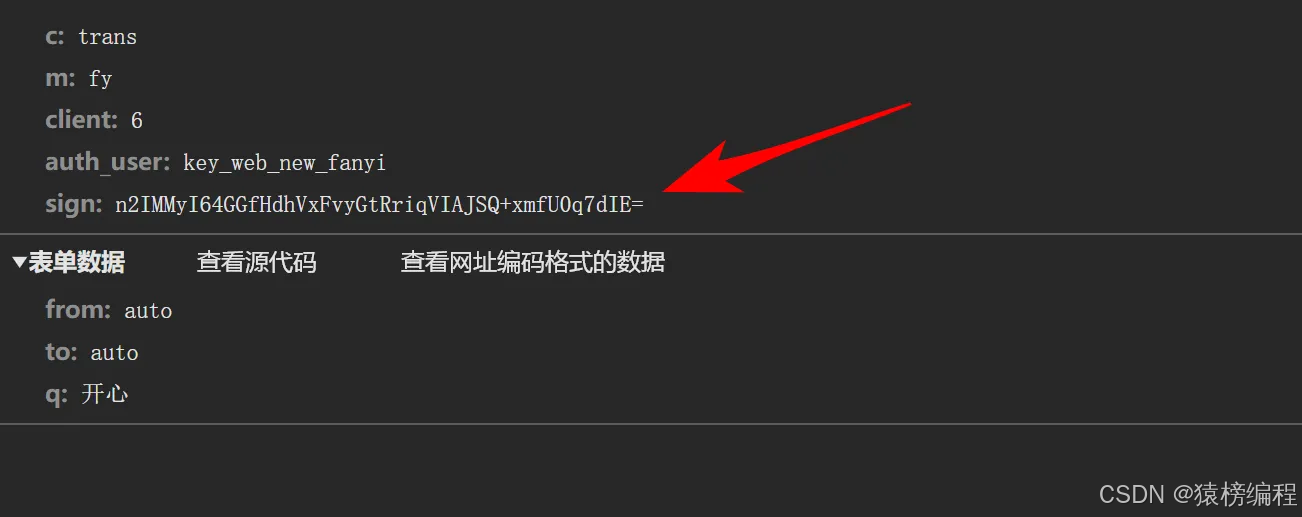
然后再请求看到response结果,他也是加密的,我们需要解密才能看到真正的返回内容。
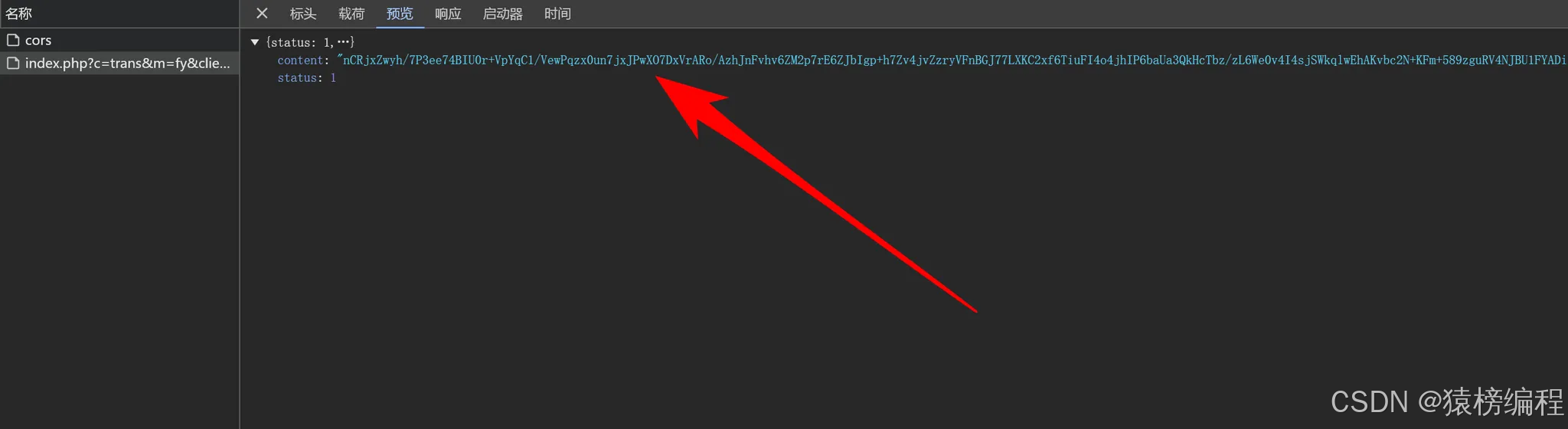
我们今天使用截包的方式来找对应的加密位置,我们先在浏览器中打上链接的断点,让他可以断点在请求之前的位置。

然后我们在触发段点断点,所以我们需要在堆栈找到对应的位置,就在浏览器中的这个地方。
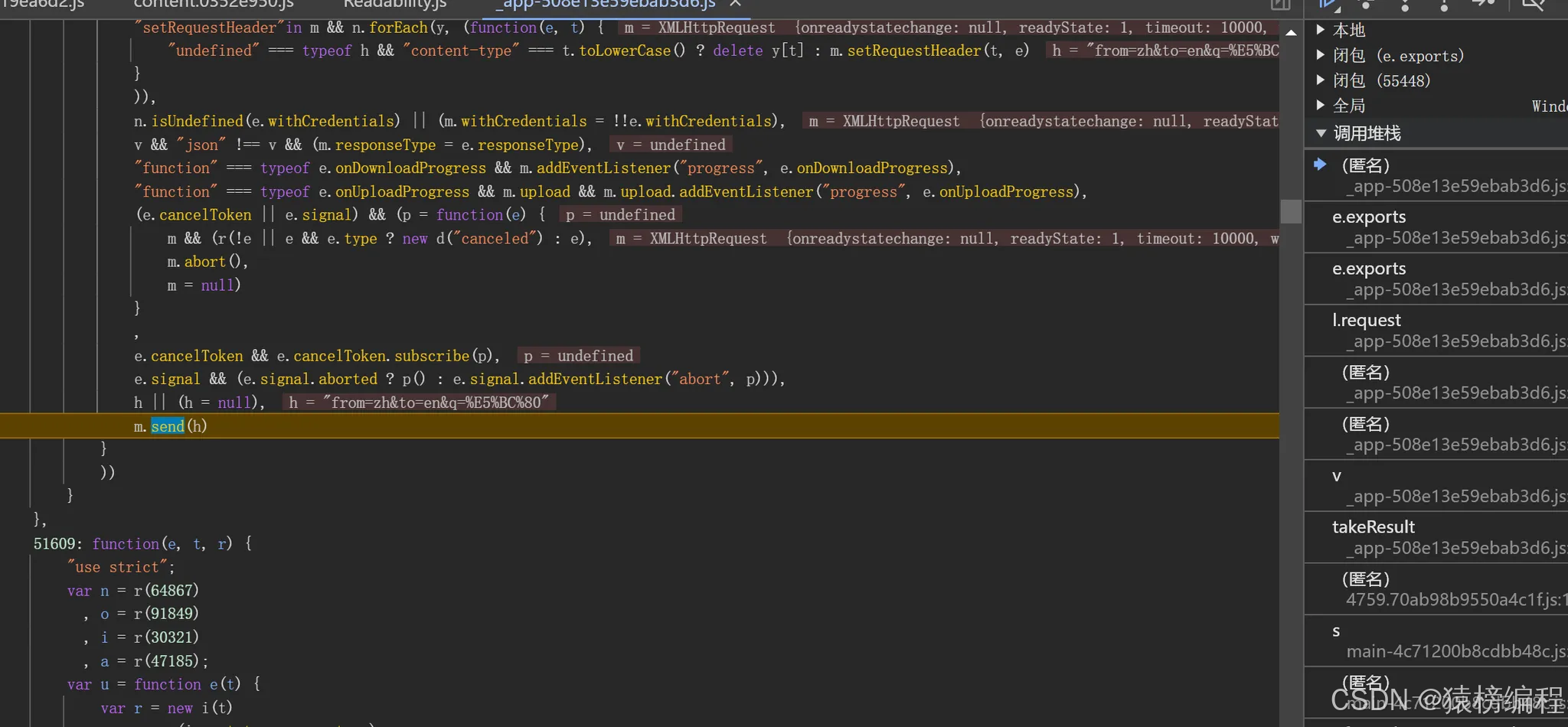
通过一个堆栈一个堆栈慢慢的查找,直到在这个位置,我们可以看到对应的数据被解密和请求之前的加密在进行拼接得到一个完整的链接。
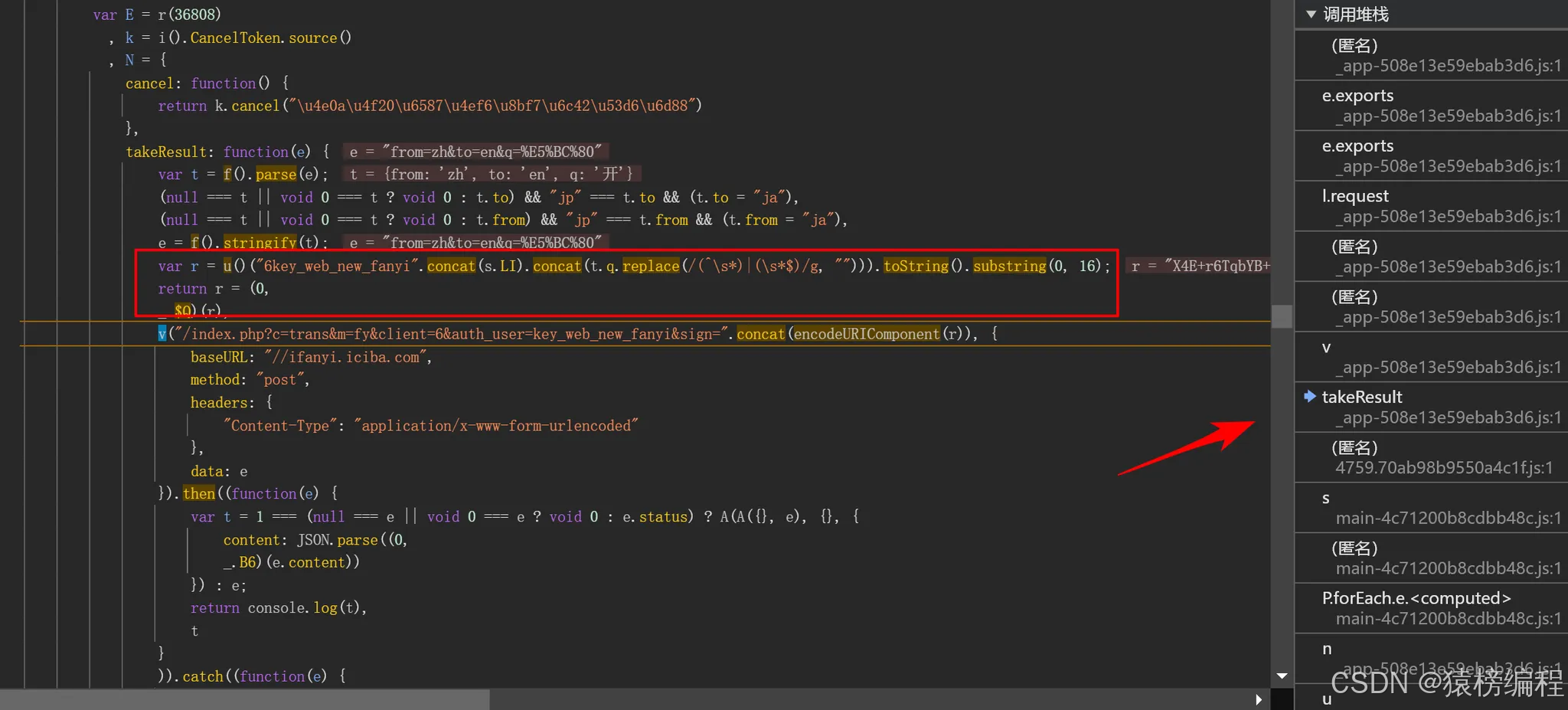
我们这里看到加密之前所需要的参数,然后再加密获取前16位数。
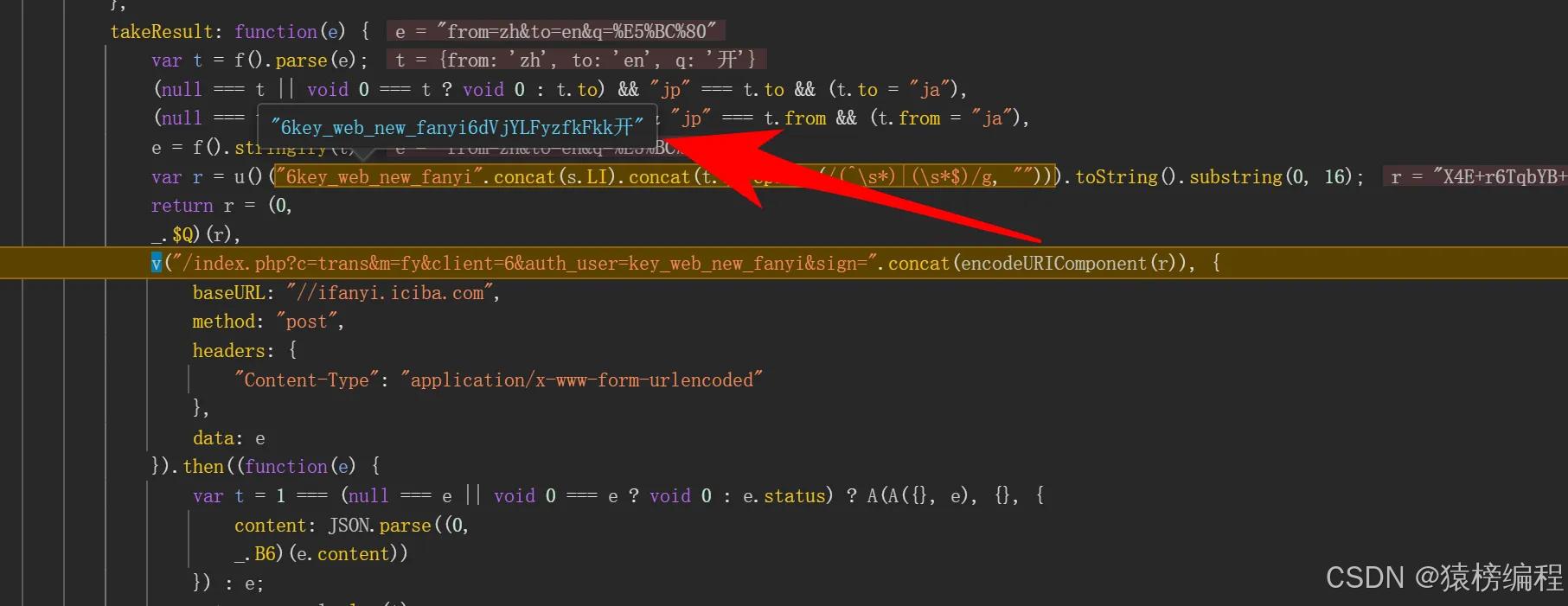
得到第一次结果还需要再进行第二次的运算。
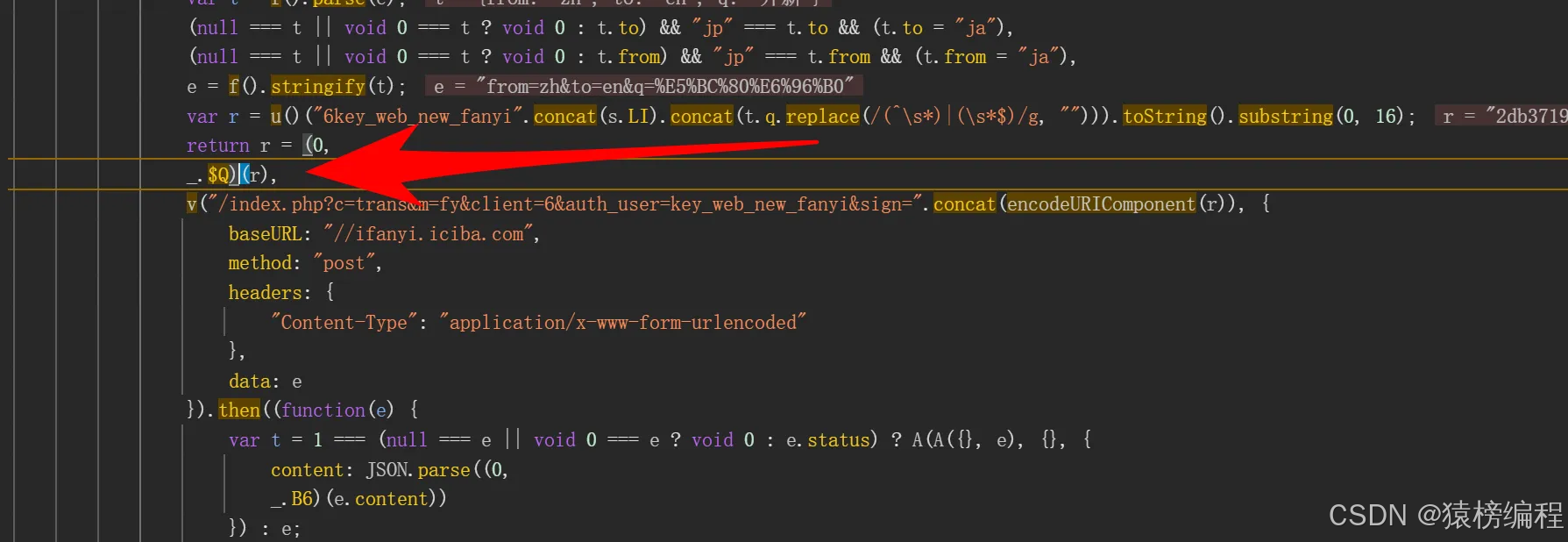
通过这个函数进行第二次的运行,我们在调试跟上去看一下是什么。
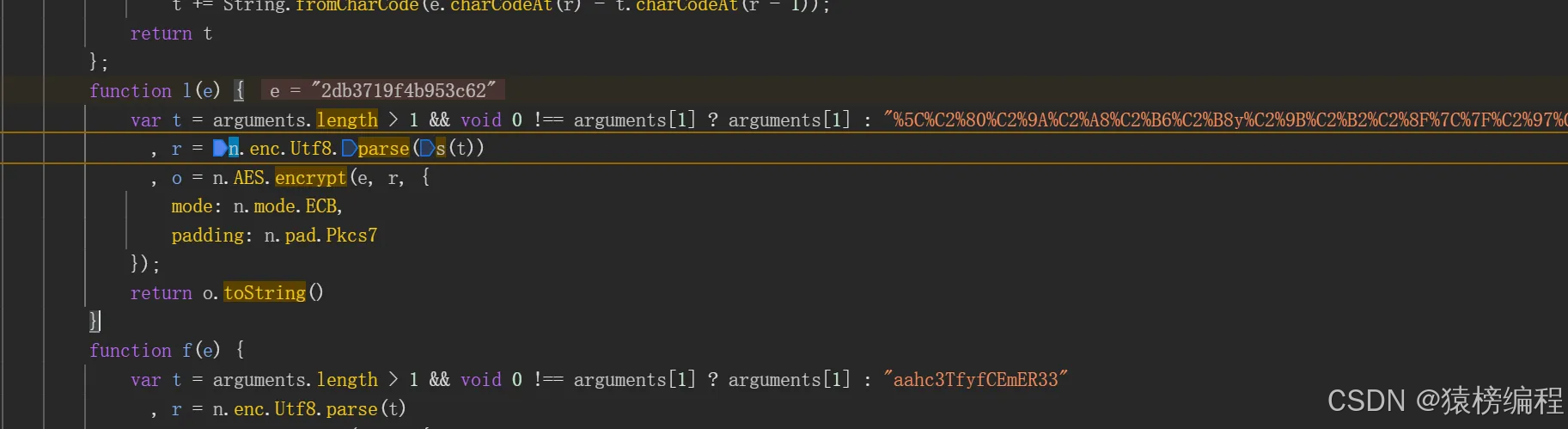
这里通过key然后用算法进行运行,得到这个sign加密,这样就可以正常的获取这个结果。
接下来我们就需要对这个返回结果,然后再解密得到正确的结果。我们才能分析请求是否正常。
我们通过之前的分析,看到其实也相对简单。还是在这个sign的下面位置一点。
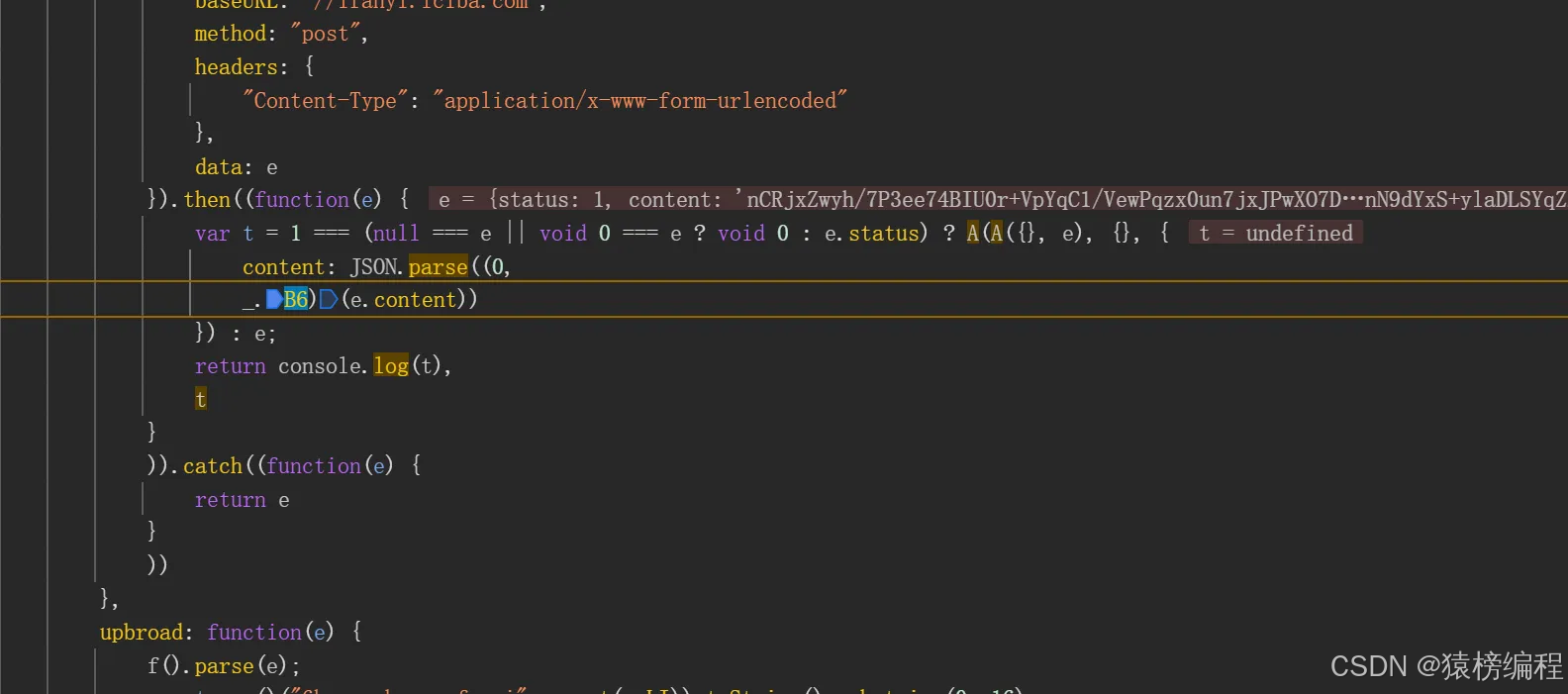
我们具体就要分析这个函数如何实现的,我们打个断电然后跳转一下。
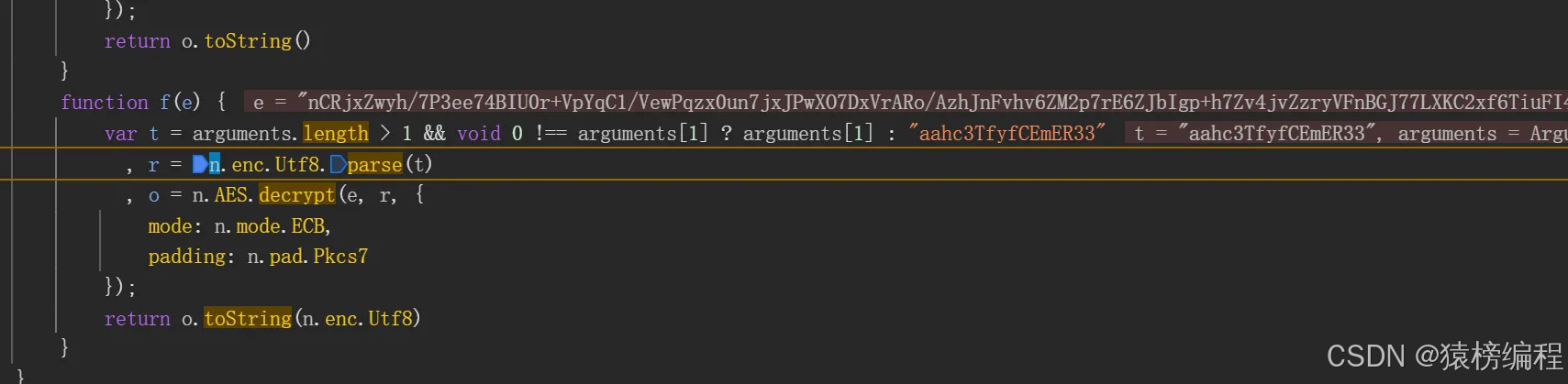
其实这里跟sign第二次的运算比较相识,我们可以看出代码也相对比较相识。这里就是使用算法进行解密得到最后的内容,然后再转换成JSON格式。

我们在控制台进行JSON转换查看是否正常。
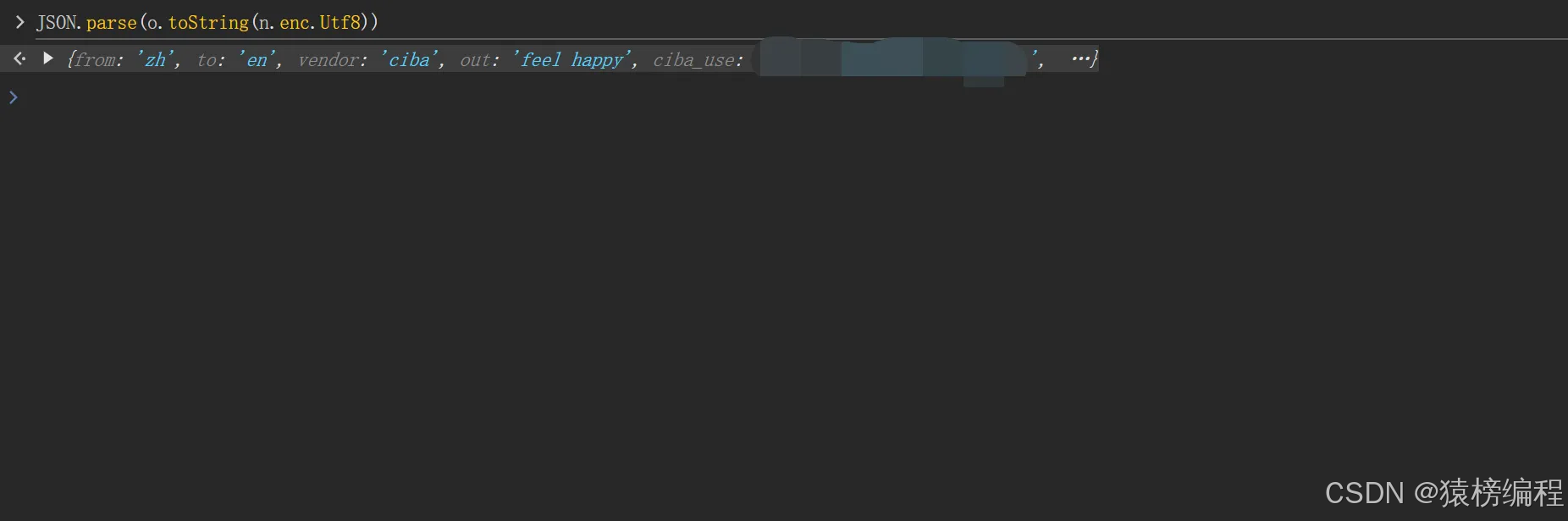
我们可以看到结果也是正常的。
算法还原实现
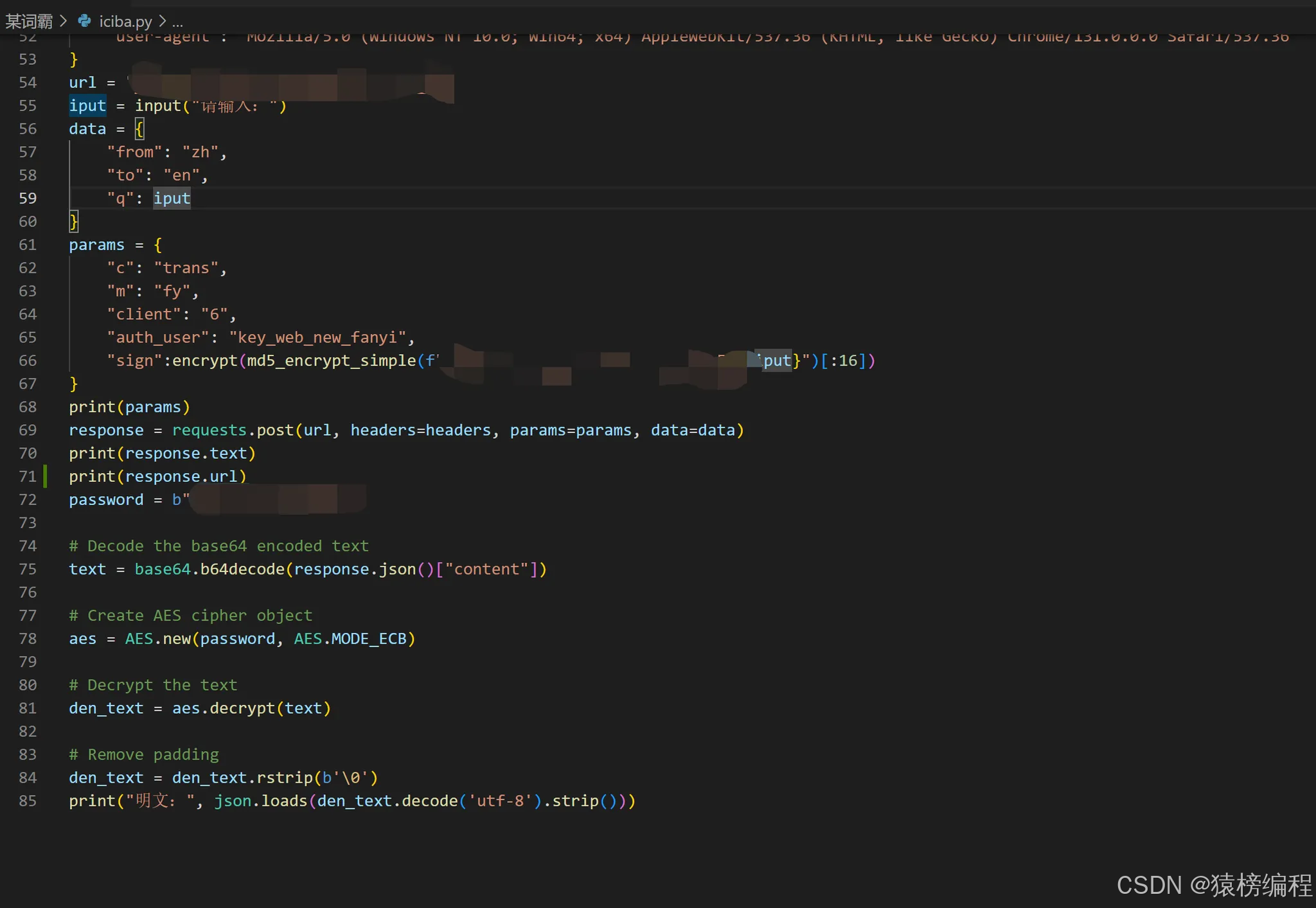
运行得到的结果如下:

代码实现的完整代码。
from Crypto.Cipher import AES
import base64
import json
import requests
import hashlib
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
from Crypto.Random import get_random_bytes
import base64
def encrypt(text):
key = "脱敏处理"
# Ensure the key length is 16 bytes for AES
key = key.encode('utf-8') # Truncate to 16 bytes if necessary
# Prepare the plaintext to be padded
plaintext = text.encode('utf-8')
# Create AES cipher in ECB mode
cipher = AES.new(key, AES.MODE_ECB)
# Apply PKCS7 padding
padded_text = pad(plaintext, AES.block_size)
# Encrypt the padded text
encrypted = cipher.encrypt(padded_text)
# Return base64 encoded encrypted string
return base64.b64encode(encrypted).decode('utf-8')
def md5_encrypt_simple(text):
return hashlib.md5(text.encode('utf-8')).hexdigest()[:16]
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-type": "application/x-www-form-urlencoded",
"origin": "脱敏处理",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "脱敏处理",
"sec-ch-ua": "\"Google Chrome\";v=\"131\", \"Chromium\";v=\"131\", \"Not_A Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
url = "脱敏处理"
iput = input("请输入:")
data = {
"from": "zh",
"to": "en",
"q": iput
}
params = {
"c": "trans",
"m": "fy",
"client": "6",
"auth_user": "key_web_new_fanyi",
"sign":encrypt(md5_encrypt_simple(f"脱敏处理{iput}")[:16])
}
print(params)
response = requests.post(url, headers=headers, params=params, data=data)
print(response.text)
print(response.url)
password = b"脱敏处理"
# Decode the base64 encoded text
text = base64.b64decode(response.json()["content"])
# Create AES cipher object
aes = AES.new(password, AES.MODE_ECB)
# Decrypt the text
den_text = aes.decrypt(text)
# Remove padding
den_text = den_text.rstrip(b'\0')
print("明文:", json.loads(den_text.decode('utf-8').strip()))
🤗 总结归纳
本文介绍了对某词霸网站的sign参数逆向分析过程。通过浏览器断点调试,我们定位到了sign参数的加密位置,发现它需要经过两次运算才能得到最终的sign值。同时,响应数据也是加密的,需要通过类似的解密算法才能获取真实内容。整个过程包括:
- 通过断点定位到加密位置
- 分析sign参数的两次加密运算过程
- 找到响应数据的解密方法
- 验证解密后的JSON数据正确性



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









