






 本文详细介绍了在Windows环境下解决FastText安装问题的方法,并分享了如何将数据转换成FastText所需格式进行文本分类,最终达到0.901的F1值。
本文详细介绍了在Windows环境下解决FastText安装问题的方法,并分享了如何将数据转换成FastText所需格式进行文本分类,最终达到0.901的F1值。
1. fasttext在windows下的安装
不知道多少小伙伴跟我遇到过一样类似的问题,直接pip install fasttext会报错。所以我们需要先下载一个.whl的包。下载地址:fasttext
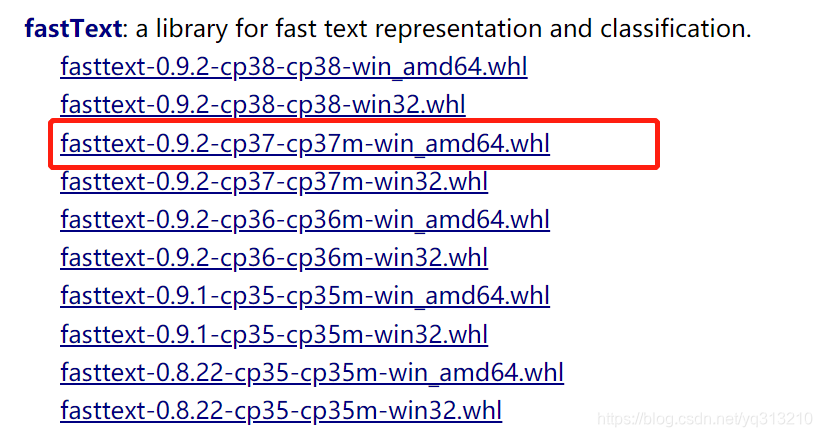
我的python是3.7的,选了如上图所示的
测试一下,在cmd里输入
import fasttext
不报错即可。
2. fasttext对数据格式的要求
我们的训练集数据格式:label,text
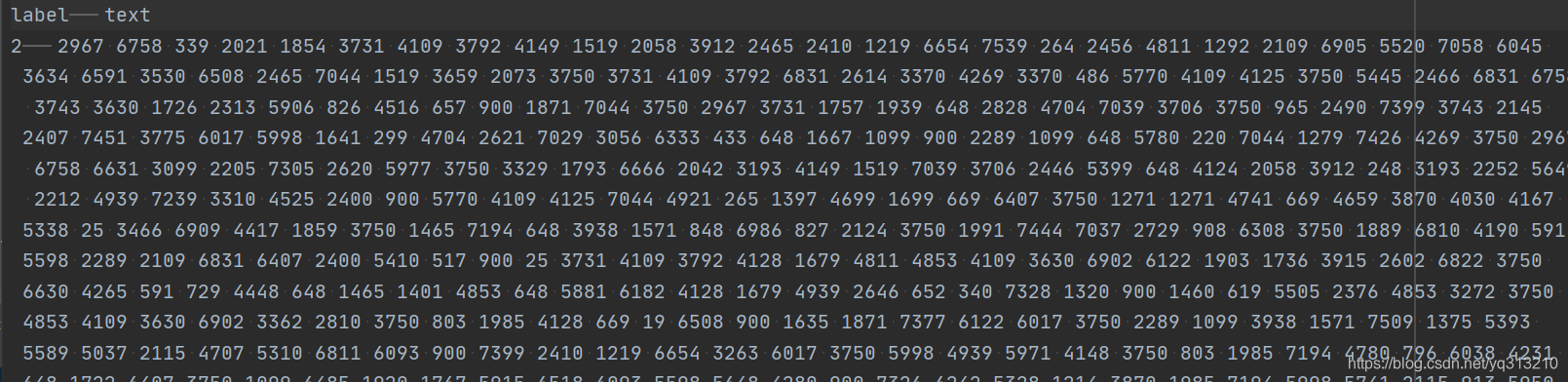
但是,fasttextasttext在windows下的安装
不知道多少小伙伴跟我遇到过一样类似的问题,直接pip install fasttext会报错。所以我们需要先下载一个.whl的包。下载地址:fasttext我的python是3.7的,选了如上图所示的测试一下,在cmd里输入pythonimport fasttext不报错即可。## 2. fasttext对数据格式的要求我们的训练集数据格式:label,text但是,fasttext要求的数据格式:分词后的句子+\t__label__标签。
因此首先需要对数据处理一下
# 转换为FastText需要的格式
train_df = pd.read_csv('data/train_set.csv',sep='\t')
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
print(train_df.head())
train_df[['text','label_ft']].iloc[:-50000].to_csv('train_fasttext.csv', index=None, header=None, sep='\t')
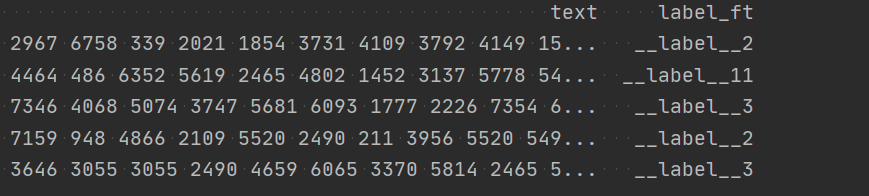
fasttext在文本分类的任务上是由于TF-IDF的。
全部代码如图:
import pandas as pd
import fasttext
#from gensim.models import fasttext
from sklearn.metrics import f1_score
# 转换为FastText需要的格式
train_df = pd.read_csv('data/train_set.csv',sep='\t')
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
print(train_df.head())
train_df[['text','label_ft']].iloc[:-50000].to_csv('train_fasttext.csv', index=None, header=None, sep='\t')
df = pd.read_csv('train_fasttext.csv')
print(df.head())
#import fasttext
model = fasttext.train_supervised('train_fasttext.csv',lr=1.0, wordNgrams=2,
verbose=2, epoch=25, loss='hs')
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-50000:]['text']
]
model.save_model('data/fasttext_demo.model')
f1值达到了0.901的效果。
在用fasttext的时候我遇到了一个问题

百度了好久也没找到答案,其实犯了一个很弱智的错误,是因为我自己建的.py文件命名为了fasttext,与下载的fasttext重名了,当时怎么也 没想到是这么回事,改了以后就可以正常运行了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









