




Apache Pinot 是一个实时分布式在线分析处理(OLAP)系统,专为低延迟、高吞吐量地查询大规模数据而设计。Pinot 适用于高并发、低延迟的分析场景,特别是在实时和批处理数据的查询中表现优异。广泛应用于实时用户仪表盘、监控系统、推荐引擎等领域。
核心特点
-
实时分析
- 支持从实时流(如 Kafka)和批处理数据源(如 Hadoop、S3)中摄取数据,提供实时查询能力。
- 在几秒或毫秒级时间内查询数据。
-
高性能查询
- 专为低延迟查询优化,支持数百毫秒内完成复杂分析。
- 内置多种索引(如倒排索引、范围索引、字典索引和星图索引),加速查询性能。
-
可扩展性
- 使用分布式架构,可以横向扩展,处理 PB 级数据。
- 支持动态扩展以满足增长的数据和查询需求。
-
多模式摄取
- 实时摄取:从 Kafka、Pulsar 等流处理系统获取实时数据。
- 批量摄取:通过 Hadoop、S3 等数据存储加载历史数据。
-
丰富的查询功能
- 支持 SQL 查询语法。
- 提供聚合、过滤、分组等功能,满足复杂分析需求。
-
灵活的存储格式
- Pinot 支持列式存储,优化了 IO 和计算性能。
- 使用压缩技术减少存储占用,同时提高查询速度。
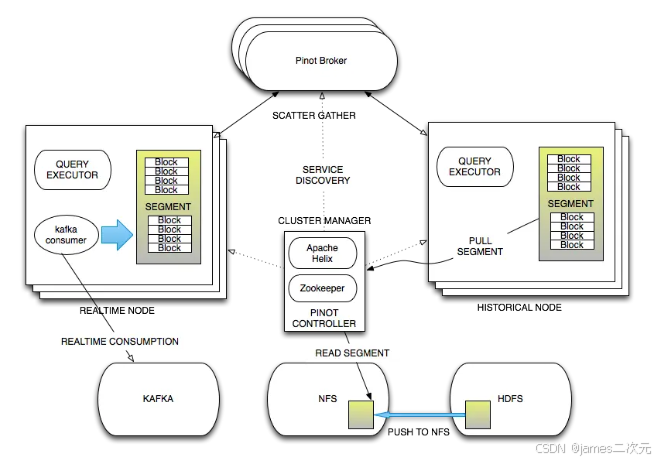
架构概览
Pinot 的核心架构包括以下几个组件:
-
控制器(Controller)
负责集群管理、任务调度、表配置和分区信息维护。 -
服务器(Server)
存储分区数据并执行查询请求。 -
代理(Broker)
接收用户查询请求,将查询分发到多个服务器,并聚合结果返回客户端。 -
实时摄取(Realtime Ingestion)
处理来自 Kafka 或 Pulsar 的实时流数据。 -
批量摄取(Batch Ingestion)
从 Hadoop、S3 或其他离线存储中加载数据。
安装与配置
1. 环境准备
- Java 8 或以上版本。
- 推荐至少 8 GB 内存和 4 核 CPU。
2. 快速启动(单节点模式)
-
下载 Pinot 的最新版本:
wget https://downloads.apache.org/pinot/apache-pinot-x.y.z/apache-pinot-x.y.z-bin.tar.gz tar -xvf apache-pinot-x.y.z-bin.tar.gz cd apache-pinot-x.y.z-bin -
启动 Pinot:
bin/pinot-admin.sh StartQuickstart -
Web 界面访问:http://localhost:9000
3. 分布式部署
Pinot 支持通过 Kubernetes、Docker Compose 或直接在物理/虚拟机上部署分布式集群。
使用示例
1. 创建表
通过配置文件定义实时表和离线表。以下为实时表的示例:
{
"tableName": "events",
"tableType": "REALTIME",
"segmentsConfig": {
"replication": "2"
},
"tableIndexConfig": {
"loadMode": "MMAP"
},
"tenants": {
"broker": "defaultBroker",
"server": "defaultServer"
},
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "events",
"stream.kafka.broker.list": "localhost:9092",
"stream.kafka.consumer.type": "simple",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
}
将该表配置文件上传到 Pinot:
bin/pinot-admin.sh AddTable -tableConfigFile events-realtime.json
2. 摄取数据
使用 Kafka 作为实时数据源,将数据摄取到 Pinot。
3. 查询数据
通过 Pinot 的 SQL 查询接口执行分析:
SELECT category, COUNT(*)
FROM events
WHERE timestamp > CURRENT_DATE - INTERVAL '1' DAY
GROUP BY category;
应用场景
-
实时用户行为分析
- 监控用户点击、浏览和购买行为。
-
日志和指标分析
- 分析服务器日志、应用性能指标。
-
推荐系统
- 实时计算用户喜好并生成个性化推荐。
-
欺诈检测
- 实时监控交易记录,识别潜在欺诈。
优化技巧
- 分区和分片设计:根据数据分布和查询模式设计分区策略,提高查询效率。
- 索引优化:使用适当的索引类型(如倒排索引或范围索引)加速查询。
- 内存管理:调整内存配置以适应数据规模和查询需求。
- 压缩策略:优化存储空间使用,减少数据读取的 IO 开销。
总结
Apache Pinot 是一个强大的实时 OLAP 系统,专注于低延迟、高吞吐量查询。凭借其灵活的架构和丰富的功能,Pinot 成为实时分析领域的优秀解决方案之一,广泛应用于互联网、金融、零售等行业。


















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









