







背景
Linux 具有功能丰富的网络协议栈,并且兼顾了非常优秀的性能。但是,这是相对的。单纯从网络协议栈各个子系统的角度来说,确实做到了功能与性能的平衡。不过,当把多个子系统组合起来,去满足实际的业务需求,功能与性能的天平就会倾斜。
容器网络就是非常典型的例子,早期的容器网络,利用 bridge、netfilter + iptables (或lvs)、veth等子系统的组合,实现了基本的网络转发;然而,性能却不尽如人意。原因也比较明确:受限于当时的技术发展情况,为了满足数据包在不同网络 namespace 之间的转发,当时可以选择的方案只有 bridge + veth 组合;为了实现 POD 提供服务、访问 NODE 之外的网络等需求,可以选择的方案只有 netfilter + iptables(或 lvs)。这些组合的技术方案增加了更多的网络转发耗时,故而在性能上有了更多的损耗。
然而,eBPF 技术的出现,彻底改变了这一切。eBPF 技术带来的内核可编程能力,可以在原有漫长转发路径上,制造一些“虫洞”,让报文快速到达目的地。针对容器网络的场景,我们可以利用 eBPF,略过 bridge、netfilter 等子系统,加速报文转发。
下面我们以容器网络为场景,用实际数据做支撑,深入分析 eBPF 加速容器网络转发的原理。
网络拓扑
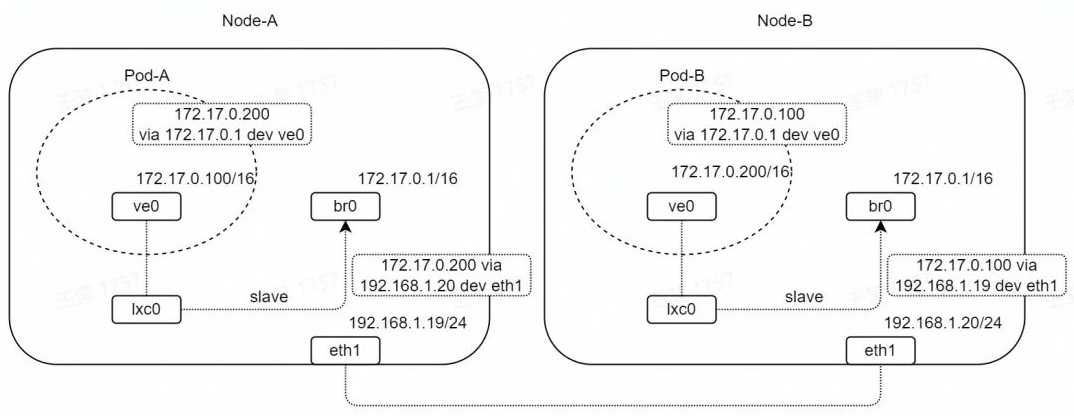
- 如图,两台设备 Node-A/B 通过 eth1 直连,网段为 192.168.1.0/24。
- Node-A/B 中分别创建容器 Pod-A/B,容器网卡名为 ve0,是 veth 设备,网段为172.17.0.0/16。
- Node-A/B 中分别创建桥接口 br0,网段为 172.17.0.0/16,通过 lxc0(veth 设备)与 Pod-A/B 连通。
- 在 Node、Pod 网络 namespace 中,分别设置静态路由;其中,Pod 中静态路由网关为 br0,Node 中静态路由网关为对端 Node 接口地址。
- 为了方便测试与分析,我们将 eth1 的网卡队列设置为 1,并且将网卡中断绑定到 CPU0。
# ethtool -L eth1 combined 1# echo 0 > /proc/irq/$(cat /proc/interrupts | awk -F ':' '/eth1/ {gsub(/ /,""); print $1}')/smp_affinity_list
bridge
bridge + veth 是容器网络最早的转发模式,我们结合上面的网络拓扑,分析一下网络数据包的转发路径。
- 在上面网络拓扑中,eth1 收到目的地址为 172.17.0.0/16 网段的报文,会经过路由查找,走到 br0 的发包流程。
- br0 的发包流程,会根据 FDB 表查找目的 MAC 地址归属的子接口,如果没有查找到,就洪泛(遍历所有子接口,发送报文);否则,选择特定子接口,发送报文。在本例中,会选择 l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









