



HDFS WEB UI
当我们启动HDFS集群后,然后通过http://master:50070/去访问HDFS WEB UI的时候,我们会经常使用Utilities下的Browse the file system去查看HDFS中的文件,如下:

然后就会出现HDFS中的根目录下所有的文件:
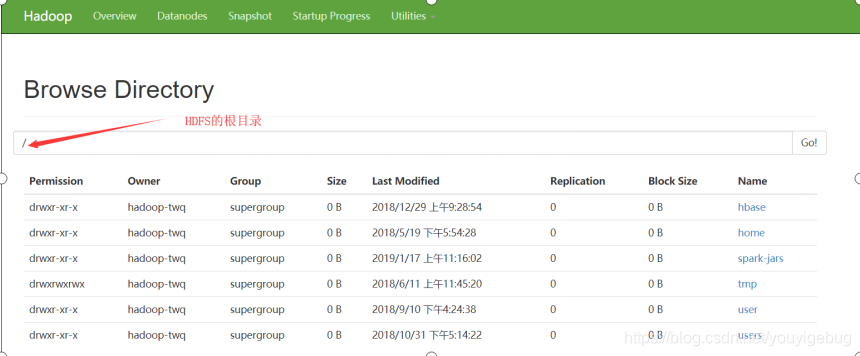
上面的方式是我们常见的访问HDFS文件的方式之一,这种使用的方式也是很方便的。
当我们启动HDFS集群后,我们可以通过http://master:50070来访问HDFS集群,其中,master是NameNode所在机器的名称。下面的就是HDFS WEB UI的七个大模块:

这篇文章,我们重点分别来详细看一下Overview、Datanodes以及Utilities三个模块
Overview
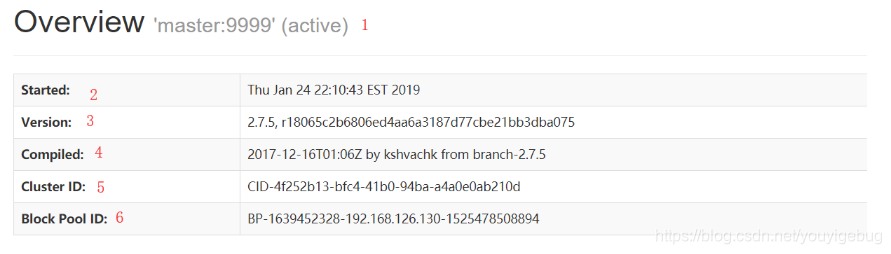
第1处的master:9999表示当前HDFS集群的基本路径。这个值是从配置core-site.xml中的fs.defaultFS获取到的。
- 第2处的Started表示集群启动的时间
- 第3处的Version表示我们使用的Hadoop的版本,我们使用的是2.7.5的Hadoop
- 第4处的Compiled表示Hadoop的安装包(hadoop-2.7.5.tar.gz)编译打包的时间,以及编译的作者等信息
- 第5处的Cluster ID表示当前HDFS集群的唯一ID
- 第6处的Block Pool ID表示当前HDFS的当前的NameNode的ID,我们知道通过HDFS Federation (联盟)的配置,我们可以为一个HDFS集群配置多个NameNode,每一个NameNode都会分配一个Block Pool ID
Summary
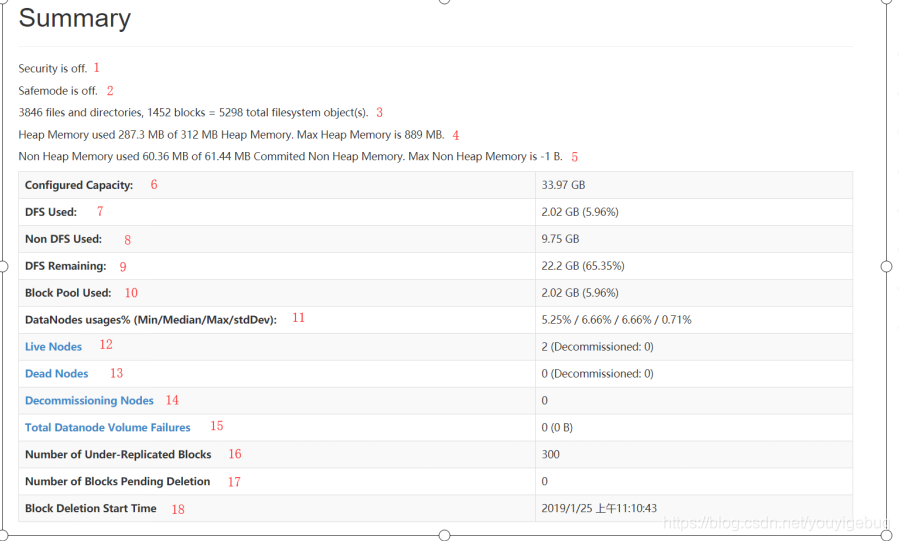
- 第1处的Security is off表示当前的HDFS集群没有启动安全机制
- 第2处的Safemode is off表示当前的HDFS集群不在安全模式,如果显示的是Safemode is on的话,则表示集群处于安全模式,那么这个时候的HDFS集群是不能用的
- 第3处表示当前HDFS集群包含了3846个文件或者目录,以及1452个数据块,那么在NameNode的内存中肯定有3846 + 1452 = 5298个文件系统的对象存在
- 第4处表示NameNode的堆内存(Heap Memory)是312MB,已经使用了287.3MB,堆内存最大为889MB,对
- 第5处表示NameNode的非堆内存的使用情况,有效的非堆内存是61.44MB,已经使用了60.36MB。没有限制最大的非堆内存,但是非堆内存加上堆内存不能大于虚拟机申请的最大内存(默认是1000M)
- 第6处的Configured Capacity表示当前HDFS集群的磁盘总容量。这个值是通过:Total Disk Space - Reserved Space计算出来的。Total Disk Space表示所在机器所在磁盘的总大小,而Reserved Space表示一个预留给操作系统层面操作的空间。Reserved space空间可以通过dfs.datanode.du.reserved(默认值是0)在hdfs-site.xml文件中进行配置。我们这边的总容量为什么是:33.97GB呢,我们可以通过du -h看一下两个slave的磁盘使用情况,如下:
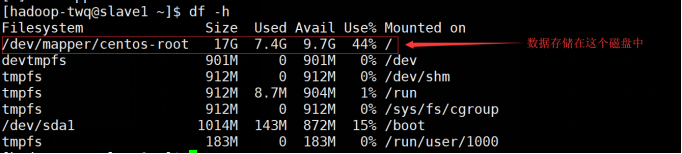
上面 17GB + 17GB = 34GB,而且我们没有配置Reserved Space,所以HDFS总容量就是33.97GB(有一点点的误差可以忽略)
- 第7处DFS Used表示HDFS已经使用的磁盘容量,说白了就是HDFS文件系统上文件的总大小(包含了每一个数据块的副本的大小)
- 第8处Non DFS Used表示在任何DataNodes节点上,不在配置的dfs.datanode.data.dir里面的数据所占的磁盘容量。其实就是非HDFS文件占用的磁盘容量
配置dfs.datanode.data.dir就是DataNode数据存储的文件目录
- 第9处DFS Remaining = Configured Capacity - DFS Used - Non DFS Used。这是HDFS上实际可以使用的总容量
- 第10处Block Pool Used表示当前的Block Pool使用的磁盘容量
- 第11处DataNodes usages%表示所有的DataNode的磁盘使用情况(最小/平均/最大/方差)
- 第12处Live Nodes表示存活的DataNode的数量。Decommissioned表示已经下线的DataNode
- 第13处Dead Nodes表示已经死了的DataNode的数量。Decommissioned表示已经下线的DataNode
- 第14处Decommissioning Nodes表示正在下线的DataNode的数量。
- 第15处Total Datanode Volume Failures表示DataNode上数据块的损坏大小
- 第16处Number of Under-Replicated Blocks表示没有达到备份数要求的数据块的数量
- 第17处Number of Blocks Pending Deletion表示正要被删除的数据块
- 第18处Block Deletion Start Time表示可以删除数据块的时间。这个值等于集群启动的时间加上配置dfs.namenode.startup.delay.block.deletion.sec的时间,其中配置dfs.namenode.startup.delay.block.deletion.sec默认是0秒
Datanodes
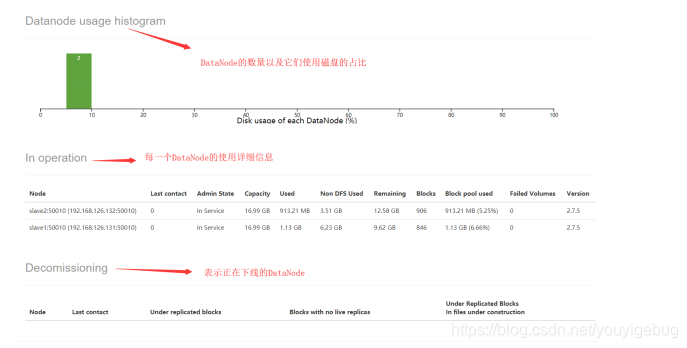
上面有一个Admin State我们有必要说明下,Admin State可以取如下的值:
- In Service,表示这个DataNode正常
- Decommission In Progress,表示这个DataNode正在下线
- Decommissioned,表示这个DataNode已经下线
- Entering Maintenance,表示这个DataNode正进入维护状态
- In Maintenance,表示这个DataNode已经在维护状态

我们这里详细总结下Browse the file system,对于Logs我们在HDFS日志的查看总结中讲解
当我们点击Browse the file system时,我么会进入到如下的界面:
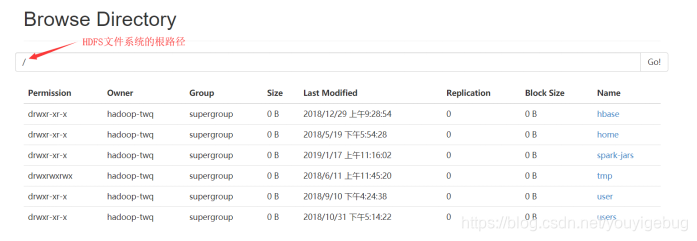
上图每一个字段的解释如下:
- Permission:表示该文件或者目录的权限,和Linux的文件权限规则是一样的
- Owner:表示该文件或者目录的所有者
- Group:表示该文件或者目录的所有者属于的组
- Size:表示该文件或者目录的大小,如果是目录的话则一直显示0B
- Last Modified:表示该文件或者目录的最后修改时间
- Replication:表示该文件或者目录的备份数,如果是目录的话则一直显示0
- Block Size:表示该文件的数据块的大小,如果是目录的话则一直显示0B
- Name:表示文件或者目录的名字
我们可以通过鼠标点击Name来访问对应的文件目录或者文件:
当我们访问的是目录的时候,则是去查看该目录下有哪些子文件或者子目录。
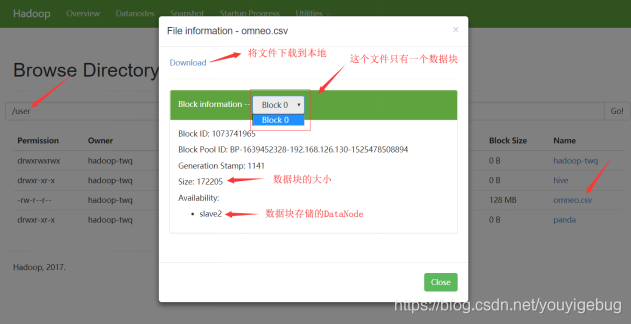
当我们访问的是文件的时候,我们查看的是文件的详细信息,比如,我们访问文件/user/omneo.csv文件:

















 2270
2270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









