










1.数组和list的区别
一、定义
1.数组:数组的大小是固定的,并且只能存放同一种类型的数据(基本类型数据或引用类型数据);
2.集合:可以对数据数量不固定的数组进行存储和操作。如果程序中不清楚到底有多少对象,需要在容量不足的时候进行自动扩充,则需要使用集合,而不选择数组。
3.联系:可以通过相应的toArray和Arrays.asList()方法进行相互转换。
二、list,set,map区别
1.List:有序,元素可重复
ArrayList、LinkedList和Vector是三个主要的实现类。ArrayList是线程不安全的, Vector 是线程安全的,这两个类底层都是由数组实现的LinkedList是线程不安全的,底层是由链表实现的。
2.Set:元素不可重复
HashSet和TreeSet是两个主要的实现类。Set 只能通过游标来取值,并且值是不能重复的。
3.Map: 键值对集合
其中key列就是一个集合,key不能重复,但是value可以重复。HashMap、TreeMap和Hashtable是Map的三个主要的实现类。HashTable是线程安全的,不能存储 null 值;HashMap不是线程安全的,可以存储 null 值。
三、List与ArrayList的区别
1.List是接口,List特性就是有序,会确保以一定的顺序保存元素;
ArrayList是它的实现类,是一个用数组实现的List。
2.如果在开发的时候觉得ArrayList,HashMap的性能不能满足你的需要,可以通过实现List,Map(或者Collection)来定制你的自定义类。
Map、Set、List是否有序
首先我们应该清楚这个概念:这里的有序和无序不是指集合中的排序,而是是否按照元素添加的顺序来存储对象。
list是按照元素的添加顺序来存储对象的,因此是有序的。他的实现类ArrayList、LinkedList、Vector都是有序的。
Map是无序的,它的存储结构是哈希表<key,value>键值对,map中插入元素是根据key计算出的哈希值来存储元素的,因此他不是按照元素的添加顺序来存储对象的,所以Map是无序的。它的实现类有:HashMap、TableMap和TreeMap。
其中LinkedHashMap是有序的,hashMap用来保证存储的值键值对,list用来保证插入的顺序和存储的顺序一致。
Set是无序的,并且set中的元素不能重复。set的底层实现其实是Map,它是计算key的哈希值来确定元素在数组中的存放位置,所以是无序的,应为在Map中key的值不能重复,所以set中的元素不能重复。它的实现类有:haseSet、TreeSet。
其中LinkedHashSet是有序的,其中haseSet用来保证数据唯一,List用来保证插入的顺序和存储的顺序一致。
#和$的区别
1、#对传入的参数视为字符串,也就是它会预编译
select * from user where name = #{name}
比如我传一个csdn,那么传过来就是
select * from user where name = 'csdn'
2、$将不会将传入的值进行预编译
select * from user where name=${name}
比如我穿一个csdn,那么传过来就是
select * from user where name=csdn
3、#的优势就在于它能很大程度的防止sql注入,而$则不行。
比如:用户进行一个登录操作,后台sql验证式样的:
select * from user where username=#{name} and password = #{pwd}
如果前台传来的用户名是“wang”,密码是 “1 or 1=1”,用#的方式就不会出现sql注入,而如果换成$方式,sql语句就变成了
select * from user where username=wang and password = 1 or 1=1
这样的话就形成了sql注入。
4、MyBatis排序时使用order by 动态参数时需要注意,用$而不是#。
mysql中in和exists有什么区别
mysql中exists和in的区别有:
1、in是把外表和内表做hash连接,先查询内表;
2、exists是对外表做loop循环,循环后在对内表查询;
3、在外表大的时用in效率更快,内表大用exists更快。
#对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大
select * from A where exists (select * from B where A.id=B.id);
#对A查询涉及id,使用索引,故A表效率高,可用大表 -->外大内小
select * from A where A.id in (select id from B);
(1)exists是对外表做loop循环,每次loop循环再对内表(子查询)进行查询,那么因为对内表的查询使用的索引(内表效率高,故可用大表),而外表有多大都需要遍历,不可避免(尽量用小表),故内表大的使用exists,可加快效率;
(2)in是把外表和内表做hash连接,先查询内表,再把内表结果与外表匹配,对外表使用索引(外表效率高,可用大表),而内表多大都需要查询,不可避免,故外表大的使用in,可加快效率。
(3)如果查询的两个表大小相当,那么用in和exists差别不大。如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
总结:外大内小用in,外小内大用exists
SQL语句insert into 不存在则插入,存在则修改
参考文档: https://blog.youkuaiyun.com/tiantang_1986/article/details/78037804
分组查询和分组筛选
关键字:group by 分组字段名
注意1.使用了分组后,在select语句中只允许出现分组字段和多行函数
2.如果是多字段分组,则先按照第一字段分组,后按照第二字段分组,一次类推
3.在where子句中不允许出现多行函数
分组筛选
关键字:having
作用:针对分组进行分组后的数据筛选,允许使用多行函数
注意:having关键字必须和group by一块使用,不能单独使用
where和having的比较:
where子句不允许出现多行函数,having子句允许出现多行函数
where子句和having子句都可以使用普通字段进行筛选,但是where效率高于having
where执行顺序:from–>where–>group by–>select–>order by
having执行顺序:from–>group by–>select–>having–>order by
结论:在分组语句中,使用where进行字段筛选,使用having进行多行函数筛选
--查询不同部门的最高工资
select deptno,max(sal) group by deptno;
--查询不同工作岗位员工数
select job,count(*)from emp group by job;
--查询不同工作部门不同岗位工作人数
select deptno,job,count(*) from emp group by deptno,job order by deptno;
--查询不同部门的不同工作岗位的并且人数大于1的信息
select deptno,job,count(*)from emp group by deptno,job having count(*)>1 order by deptno;
--查询部门号大于10的不同部门的不同工作岗位的人数
select deptno,job,count(*) from emp where deptno>10 group by deptno,job order by deptno;
select deptno,job,count(*)from emp group by deptno,job having deptno>1 order by deptno;
## like用法
```java
Select * from emp where ename like 'M%';
% 表示多个字值,_ 下划线表示一个字符;
M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。
%M% : 表示查询包含M的所有内容。
%M_ : 表示查询以M在倒数第二位的所有内容。
SELECT * FROM sys_user WHERE nick_name LIKE '刘%';
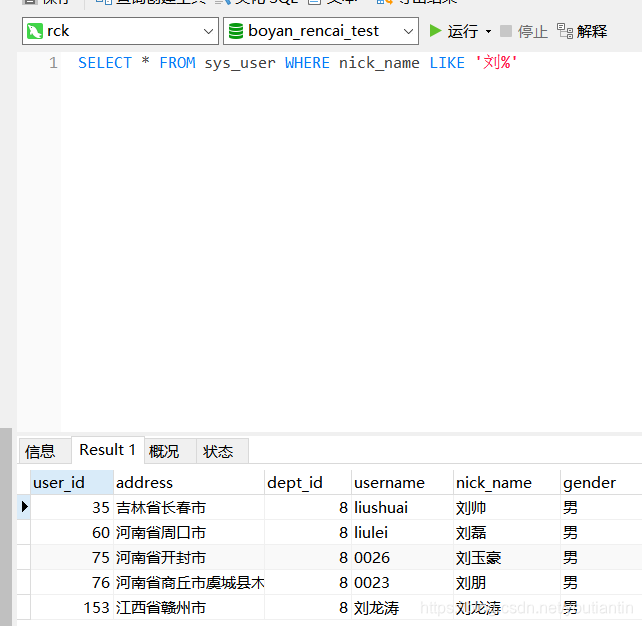
其他的自己测试吧
查询 sys_user 表中 nick_name 列中有 刘的值,刘为要查询内容中的模糊信息。
————————————————
(本文记录我自己遇到的,以后遇到什么写什么)后续会一直变化。。。。

















 171万+
171万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









